MarkLogic 10 Product DocumentationAdministrator's Guide — Chapter 14
Word Query Database Settings
This chapter describes how to configure a database to include or exclude elements, add index settings, and perform other configuration changes for cts:word-query operations. The following topics are included:
Understanding the Word Query Configuration
Basic search of words and phrases in MarkLogic Server is based on the query constructor cts:word-query. You can control the behavior of these basic searches by changing the database configuration for word query. You can exclude and/or include elements from word queries, and you can add extra indexing options compared to the options configured in the database configuration. This section describes the options available in the word query configuration and includes the following parts:
- Overview of Configuration Options
- Understanding Which Elements are Included and Excluded
- Adding a Weight to Boost or Lower the Relevance of an Included Element
- Specifying An Attribute Value for an Included Element
- Understanding the Index Option Configuration
Overview of Configuration Options
The following lists the main options you can set in the word query configuration to control how word queries are resolved in a database:
- By default, all elements are included in the word query configuration and the indexing options are the same as the database indexing options.
- All word query configurations are set on a per-database basis.
- The word query configuration controls the behavior of the
cts:word-query,cts:words, and cts:word-match APIs. This includes controlling the words that get indexed, as well as controlling the words that are returned from the filter (evaluator) portion of query evaluation. - Word query inherits the database index settings as a starting point for its index settings.
- You cannot turn off indexing options that are enabled in the database settings.
- If you check index options in word query that are enabled in the database, it will not change any behavior. However, if you subsequently disable a database index setting that is checked in the word query settings, it will remain for the word query.
- You can include and/or exclude named elements from word queries.
- For any element you include, you can optionally constrain it by a value for a specified attribute.
- For any element you include, you can optionally specify a weight. The weight is used when determining relevance scores, where a weight greater than 1.0 will boost scores and a weight lower than 1.0 will lower scores for matches within the element.
Understanding Which Elements are Included and Excluded
You can include and/or exclude elements from word queries. This is useful if you know you will never want to search some element content. This section describes how MarkLogic Server determines what content is included in word queries and what is not when you include and/or exclude elements from the word query configuration.
If you want to be able to search on everything in a word query, but also want a special view of the content that includes and/or excludes some elements, consider creating a field instead of modifying the word query configuration. For details on fields, see Fields Database Settings.
By default, all element content (all text node children of elements) is included in word queries. If you decide to include and/or exclude any elements from word queries, there are rules that govern which non-specified elements are indexed and which are not. The rules are based on inheriting the include state from the parent element. For example, if the parent element is marked as an included element (and is therefore indexed and evaluated for word query), then its children, if they do not appear on the exclude list, are also included.
If you configure word query exclusions then MarkLogic may not use word positions, even if it is enabled. For example, MarkLogic will not use word positions for resolution of queries such as cts:element-word-query or cts.jsonPropertyWordQuery resolution in positional contexts such as a near query. This can lead to false positives. You can use xdmp:plan or cts.plan to determine whether word positions are being used.
When MarkLogic Server determines which elements to include/exclude, it walks the XML tree using the following rules:
- Start at the root node of the document.
- If the root node is included (either because it is explicitly included or because
include document rootis set to true), MarkLogic Server includes the immediate text node children of the document root element and then moves to its element children. If the root node is excluded, the text nodes are not included and MarkLogic Server moves down the XML tree to its element children. - If the parent element (the root element in this case) was included, MarkLogic Server keeps walking down the tree and including the text node children until it encounters an explicitly excluded element.
- If the parent element (the root element in this case) was not included, MarkLogic Server keeps walking down the tree, not including the text node children, until it encounters an explicitly included element.
- MarkLogic Server keeps walking down the tree, including or not according to the state inherited from the parent element, until it encounters the next included element (if it is in the not included state) or excluded element (if it is in the included state).
- During this process, when an element is encountered that is neither included nor excluded, it inherits the included state (not included or included) from the parent element.
- MarkLogic Server keeps walking down the XML tree using this logic to determine its included state, until it reaches the end of the document.
The only way to guarantee an element's text node children will be included (assuming you have any elements included and/or excluded) is to add it to the included list, and the only way to guarantee an element is not included is to add it to the excluded list.
The following figure shows what is included for two configurations, one with the root node included and one with the root node excluded. Note that the includes and excludes are the same. The lines below the element names represent the text nodes, and the yes/no indicates whether the content in the text nodes is included in word queries. The root represents the rode node of an XML structure, with elements A and B included and elements C and D excluded. Elements that are not explicitly included or excluded (for example, E, F, and Z) inherit from their parents.
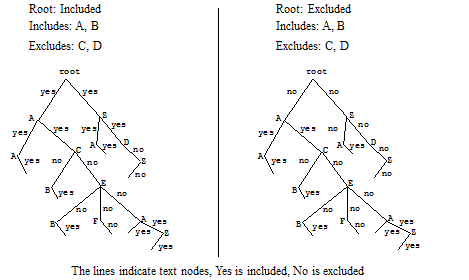
Notice that the Z node, which is not explicitly included or excluded, sometimes is included and sometimes is not included, depending on the include state of its parent element.
Adding a Weight to Boost or Lower the Relevance of an Included Element
When you include an element, one of the options is to add a weight to the included element specification. When you add a weight, all text in this element (including any text in all text node descendants of the element) are weighted by the specified value, changing the relevance at query time. Specifying a weight greater than 1.0 will boost scores and a weight lower than 1.0 will lower scores for matches within the element.
When you specify a weight, the term frequency for any tokens in that element (including tokens in descendant text nodes) is multiplied by that number. This happens during document load, update, or reindexing. For example, if you specify a weight of 2.0, each term will have a term frequency of 2.0, making it as if each term appeared twice (for score calculation purposes). Similarly, if you specify a weight of 0.5, each term will have a term frequency of 0.5.
Because the weight boosting affects term frequency, it will only affect relevance orders for scoring algorithms that include term frequency (for example, logtf/idf or logtf); scoring algorithms that do not consider weight will not be affected by these weights (for example, score-simple).
Adding a weight is useful to boost or lower scores on searches where the match occurs in a given element. For example, if you want matches in TITLE elements to contribute more towards the relevancy score than matches in other elements, you can specify a weight of 2.0 for the TITLE element. Conversely, if you want matches in TITLE elements to contribute less to the relevancy score than matches in other elements, you can specify a weight of 0.5 for the TITLE element. For details on how relevance is calculated, see the chapter Composing cts:query Expressions in the Search Developer's Guide.
Specifying An Attribute Value for an Included Element
When you include an element, one of the options is to specify an attribute value. This option allows you to only include elements with a particular attribute/value pair. The attribute/value pair acts as a predicate on which to constrain the content. For example, consider the following XML snippet:
<chapter class="history">some text here</chapter> <chapter class="mathematics">some more text here</chapter> <chapter class="english">some other text here</chapter> <chapter class="history">some different text here</chapter> <chapter class="french">other text here</chapter> <chapter class="linguistics">still other text here</chapter>
For the element chapter, if you specify the attribute/value pair of class and history, then only the following elements will be included:
<chapter class="history">some text here</chapter> <chapter class="history">some different text here</chapter>
You can only specify an attribute value for an included element; you cannot specify one for an excluded element.
Understanding the Index Option Configuration
The word query configuration allows you to add some extra indexing options from the ones that are currently set in the database configuration. Adding any index options to the word query configuration does not add those options to the element-based index options.
To add a particular index option to word query, you check the box corresponding to the index option. Adding any index options that are not enabled in the database configuration will cause new and updated documents to use the new indexing for word query, and will trigger a reindex operation if reindex enable is set to true in the database configuration.
Options that are enabled in the database configuration appear in bold on the word query configuration. If you check the box next to an option with bold-face type, it does not change your configuration. However, if you subsequently disable that index option in the database configuration, it will remain enabled for word query as long as the box is checked.
Configuring Customized Word Query Settings
This section provides the procedure for customizing the word query settings. For details on what the meaning of the various configuration options in fields, see Understanding the Word Query Configuration. The following is the procedure for modifying the word query configuration for your database:
When you modify the word query settings, those modifications apply to all queries that use the cts:word-query constructor, which is the default constructor for cts:search. If you want to be able to search on everything in a word query, but also want a special view of the content that includes and/or excludes some elements, consider creating a field instead of modifying the word query configuration. For details on fields, see Fields Database Settings.
Use the Admin Interface to perform the following steps to add a new field configuration to a database.
- Access the Admin Interface in a browser.
- Navigate to and click the database for which you want to modify the word query configuration, either from one of the summary tables or in the left tree menu.
- Under the database in which you want to create the field, click the Word Query link. The Word Query Configuration page appears.
- If you want the word queries to include any extra index options from the database, check those index settings. Index settings shown in bold indicate the setting is inherited from the database setting. For details, see Understanding the Index Option Configuration.
- If you want the word queries to include the root element of the document, even if it is not explicitly included, leave the default of
truefor include document root button. Note that if you set this tofalse, you will need to include elements in the word query configuration in order to get any results from word queries. Typically, you would leave this set to true and choose some elements to explicitly exclude and some to explicitly include (optionally adding a scoring weight and/or an attribute value constraint). - Click OK to save any changes you made. The configuration page refreshes with after the changes have been made to the MarkLogic Server configuration.
- If you want to exclude any elements from word queries, click the Excludes tab.
- Enter the namespace URI (if needed) and the local name for the excluded element.
- Click OK.
- Repeat steps 7 through 9 for each element you want to exclude.
- Click the Includes tab to specify elements to include in the word query.
- On the Included Element page, specify a local name for the element to include. If the element is in a namespace, specify the namespace URI for the element to include.
- [OPTIONAL] If you want to boost or lower the relevance contribution for matches within this element, specify a weight other than the default of 1.0. Weights greater than 1.0 will boost the relevance contribution and weights lower than 1.0 will lower the contribution.
- [OPTIONAL] If you want to only include elements that have an attribute with a specified value, enter the attribute namespace URI (if needed), the attribute local name, and a value for the attribute. Then only elements containing attributes with the specified value will be included. You must specify the exact value; no wildcard characters are used.
- When you have specified everything for this element, click OK.
- Repeat steps 11 through 15 for each element you want to include.
- You can delete any included or excluded fields from the tables at the bottom of the field configuration page.