
MarkLogic 10 Product DocumentationAdministrator's Guide — Chapter 26
Range Indexes and Lexicons
MarkLogic Server allows you to create, at the database level, indexes and lexicons on elements and attributes according to their QNames. This chapter describes these range indexes and lexicons. The following sections are included:
- Understanding Range Indexes
- Using Range Indexes for Value Lexicons
- Understanding Word Lexicons
- Understanding Path Range Indexes
- Viewing Element Range Index Settings
- Defining Element Range Indexes
- Viewing Attribute Range Index Settings
- Defining Attribute Range Indexes
- Viewing Path Range Index Settings
- Defining Namespace Prefixes Used in Path Range Indexes and Fields
- Defining Path Range Indexes
- Viewing Element Word Lexicon Settings
- Defining Element Word Lexicons
- Viewing Attribute Word Lexicon Settings
- Defining Attribute Word Lexicons
- Defining Value Lexicons
- Deleting Range Indexes or Lexicons
- Defining Field Range Indexes
Additionally, you can create range indexes on fields, as described in Creating a Range Index on a Field.
This chapter describes how to use the Admin Interface to create range indexes and lexicons. For details on how to create range indexes programmatically, see Adding Indexes to a Database in the Scripting Administrative Tasks Guide.
Understanding Range Indexes
This chapter describes the types of range indexes shown in the table below. There are also field range indexes, as described in Creating a Range Index on a Field.
| Type | Description |
|---|---|
| Element range index | A range index on an XML element or JSON property. |
| Attribute range index | A range index on an attribute in an XML element. |
| Path range index | A range index on an XML element, XML attribute, or JSON property as defined by an XPath expression. |
| Field range index | A range index on a field. For details, see Fields Database Settings. |
MarkLogic Server maintains a universal index for every database to rapidly search the text, structure, and combinations of the text and structure that are found within collections of XML and JSON documents.
In some cases, however, XML and JSON documents can incorporate numeric or date information. Queries against these documents may include search conditions based on inequalities (for example, price < 100.00 or date ℜ≥ thisQtr). Specifying range indexes for these elements, attributes, and/or JSON properties will substantially accelerate the evaluation of these queries.
Defining a range index also allows you to use the range query constructors (cts:element-range-query and cts:element-attribute-range-query) in cts:search operations, making it easy to compose complex range-query expressions to use in searches. For details, see the Using Range Queries in cts:query Expressions chapter in the Search Developer's Guide.
Similarly, you can create range indexes of type xs:string. These indexes can accelerate the performance of queries that sort by the string values, and are also used for lexicon queries (see Understanding Word Lexicons).
If you specify a range index on an element, and if you have elements of that name that have complex content (for example, elements with child elements), the content is indexed based on a casting of the element to the specified type of the range index. For example, if you specify a range index of type xs:string on an element named h1, then the following element:
<h1>This is a <b>bold</b> title.</h1>
is indexed with the value of This is a bold title, which is the value returned by casting the h1 element to xs:string. The same type casting applies to range indexes on XML attributes, JSON properties, and fields. This behavior allows you to index complex content without pre-processing the content.
Also, range indexes can improve the performance of queries that sort the results using an order by clause and return a subset of the data (for example, the first ten items). For details on this order by optimization using range indexes, see Sorting Searches Using Range Indexes in the Query Performance and Tuning Guide guide.
MarkLogic Server supports range indexes for both elements and attributes across a wide spectrum of XML data types. For the most part, this list conforms to the XML totally ordered data types:
It is important to note that the date and time types listed above adhere to the XML specification for dates and times. At present, other date and time formats are not supported by MarkLogic Server range indexes. For a more detailed description of the definition of these data types, consult the W3C XML Schema documents.
Range indexes must be explicitly created using the Admin Interface, the XQuery or JavaScript Admin API, or the REST Management API. To create a range index on a JSON property, use the element range index interfaces or functions. The following table outlines the basic information needed to define each kind of index:
| Index Type | Required Information |
|---|---|
| XML element | The element name, the namespace for the element, the data type of the values found in that element. |
| XML attribute | The attribute name, the name of the attribute's parent element, a namespace for the element, and the data type of the values found in that attribute. |
| JSON property | The property name and the data type of the values found in that property. |
| path | An XPath expression and the data type of the values found in the element, attribute, or JSON property expressed by the XPath. |
| field | The field name and data type of the values in the field. You must also configure the field definition. For details, see Configuring Fields. |
Range indexes are populated during the document loading process, and are automatically kept in sync through subsequent updates to indexed data. Consequently, range indexes should be specified for a database before any XML or JSON documents containing the content to be indexed are loaded into that database. Otherwise, the content must be either reindexed or reloaded to take advantage of the new range indexes.
Use the element range index interfaces and APIs to create indexes for JSON documents. Some restrictions apply. For details, see Creating Indexes and Lexicons Over JSON Documents in the Application Developer's Guide.
You can create the same type of index with a path range index as you can with an element or attribute range index. Path range indexes are useful in circumstances in which an element or attribute range index will not work. For example, you may have documents with the same element name appearing under different parent elements and you only want to index the elements appearing under one of the parent elements. In this case, a path range index is required to correctly index that element.
When creating a range index with a scalar type of string (xs:string), specify a collation as well as the element/attribute QNames or JSON property name. The collation specifies the unique ordering for the string values. You can have multiple range indexes on the same element, attribute, or JSON property with different collations; that is, the collation is part of the unique identifier for the string range index. For details about collations, see the Encodings and Collations chapter in the Search Developer's Guide.
Because a range index stores typed data, if the data you load does not conform to that type, or if it cannot be coerced to conform to the specified type, it cannot be loaded into the document. For each range index, you can specify what to do for invalid values, either reject them and have the document load throw an exception and fail, or ignore them and log the coercion errors in the ErrorLog.txt file at Debug level. The default is to reject invalid data.
Range indexes use disk space and consume memory. That is the trade-off for improved performance. Additionally, if you have a large amount of range index data and if your system is updated regularly, you might need to increase the size of your journals. For details on the database journal settings, see Memory and Journal Settings.
Using Range Indexes for Value Lexicons
In addition to speeding up sorting and comparison queries, MarkLogic Server uses range indexes to resolve XML element, XML attribute, JSON property, and field value lexicon queries. These are queries that use the following search APIs:
- cts:values
- cts:value-match
- cts:element-attribute-values
- cts:element-attribute-value-match
- cts:element-values
- cts:element-value-match
- cts:field-values
- cts:field-value-match
The cts:values and cts:value-match functions work on any kind of range index and are equivalent to the corresponding index-specific function when called with a reference to the same type of index. For example, the following two function calls are equivalent:
cts:values(cts:element-reference(xs:QName("some-element"))) cts:element-values(xs:QName("some-element")
In order to use any of these APIs, you must create range indexes on the element(s), attribute(s), JSON property(s), or field(s) specified in the query. The type of the range index must match the type specified in the lexicon API.
For details about lexicons, see the Browsing With Lexicons chapter of the Search Developer's Guide. For more details on the lexicon APIs, see the MarkLogic XQuery and XSLT Function Reference.
Understanding Word Lexicons
MarkLogic Server allows you to create a word lexicon that is restricted to a particular XML element, XML attribute, JSON property, or field. You can also define a field word lexicon across a collation. A word lexicon stores all of the unique words that are stored in the specified element, attribute, or JSON property. The words are stored case-sensitive and diacritic sensitive, so the words Ford and ford would be separate entries in the lexicon.
Word lexicons are used in wildcard searches (when wildcarding is enabled). For details, see Understanding and Using Wildcard Searches in the Search Developer's Guide.
Understanding Path Range Indexes
A path range index enables you to define a range index on an XML element, XML attribute, or JSON property using an XPath expression. A path range index can give you finer control over what is indexed. For example, if your content contains elements with the same name at multiple levels, but you only want to index one of them, you can use a path range index to target just that one.
This section describes the XPath expressions you can use to define a path range index. For performance reasons, MarkLogic Server restricts you to a subset of XPath when defining a path range index.
- Limitations on Index Path Expressions
- Examples of Index Path Expressions
- Testing the Validity of an Index Path Expression
- Using Namespace Prefixes in Index Path Expressions
Limitations on Index Path Expressions
You can only use subset of XPath for defining path range indexes. The limitations are described in Path Field and Path-Based Range Index Configuration in the XQuery and XSLT Reference Guide.
Avoid creating multiple path indexes that end with the same element/attribute, as ingestion performance degrades with the number of path indexes that end in common element/attributes.
You can use cts:valid-index-path to test whether or not you can use an XPath expression to define a path range index. For details, see Testing the Validity of an Index Path Expression.
Note numbers, booleans, and nulls in JSON documents are indexed separately rather than all being treated as text. For details on constructing XPath expressions on JSON documents, see Traversing JSON Documents Using XPath in the Application Developer's Guide.
Examples of Index Path Expressions
The following table provides examples of XPath expressions that are valid and invalid for defining a path range index.
Avoid creating multiple path indexes that end with the same element/attribute, as ingestion performance degrades with the number of path indexes that end in common element/attributes.
Namespace prefixes are permitted in all valid path expressions. Note that you can also use fn:matches and fn:contains as part of the path expression, but you cannot use other functions in the path expression. Use cts:valid-index-path to test if a path expression is valid for an index path.
Testing the Validity of an Index Path Expression
You can use the XQuery function cts:valid-index-path to test whether or not an XPath expression can be used to define a path range index. To test validity, copy the following query into Query Console, modify it to use your path expression, and run it.
xquery version "1.0-ml"; cts:valid-index-path("/a/b", fn:true())
Use the second parameter to control whether or not to verify that namespace binding definitions are configured for namespace prefixes used in the path expression.
Using Namespace Prefixes in Index Path Expressions
XML namespace prefixes are permitted in all valid path range index expressions, but you must define the namespace binding in your database configuration. For example, if your path expression is /ns:a/ns:b, you must configure a namespace binding for the prefix ns.
To pre-define a namespace binding, use the Path Namespaces configuration page for your database in the Admin Interface or the XQuery function admin:database-add-path-namespace.
For details, see Defining Path Range Indexes.
Viewing Element Range Index Settings
To view the element range indexes that will be applied to documents as they are loaded or reindexed, perform the following steps:
Defining Element Range Indexes
To define a range index for an XML element or JSON property, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to create a range index, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to create a range index.
- Click the Element Range Indexes icon in the tree menu, under the selected database.
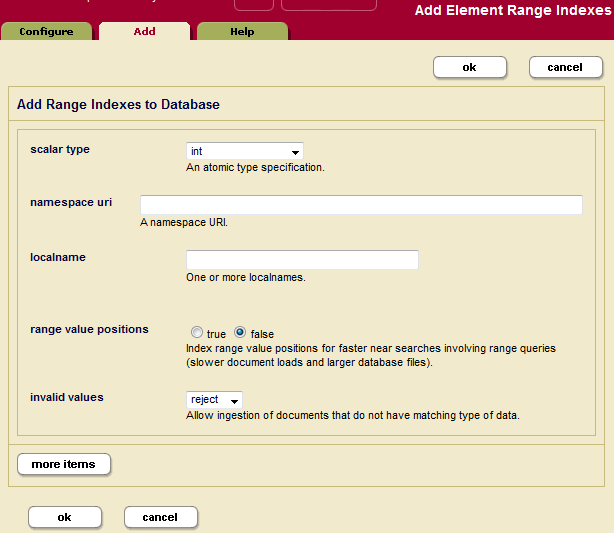
- Click the Add tab. The Add Range Indexes configuration page displays:
- Select the type of the XML element or JSON property for which you want to build a range index.
- If the index is of type
xs:string, a collation box appears with a default collation. If you want the index to use a different collation than the default, enter the collation URI. You can click the Collation Builder button for a wizard that constructs the collation URI for you based on the language and other parameters you enter. For details about collations, see the Language Support in MarkLogic Server chapter in the Search Developer's Guide. - Enter the namespace URI of the XML element. Skip this step for a JSON property index.
Every XML element is associated with a namespace. For the description of the element to be precise, you must specify the namespace of the XML element. The asterisk (*) cannot be used to indicate namespace independence. Leaving the namespace URI field blank specifies the universal unnamed namespace.
- Enter the element or JSON property name in the localname field.
The local name is the name of the XML element to be indexed. If you have more than one element of the same type in the same namespace that you want to index, you can provide a comma-separated list of element names.
- Choose whether to index range value positions for this index. Setting range value positions to
truewill speed the performance of searches that use cts:near-query and cts:element-query with this index, but will use more disk space than leaving the positions off (range value positionsfalse). - In the invalid values field, choose whether to allow insertion of documents that contain elements or JSON properties on which range index is configured, but the value of those elements cannot be coerced to the index data type. It can be configured to either
ignoreorreject. By default server rejects insertion of such documents. However, if a user configures invalid values to ignore, these documents can be inserted. This setting does not change the behavior of queries on invalid values after documents are inserted in the database. Performing an operation on an invalid value at query time can still result in an error. - To add more indexes, click the More Items button and repeat step 6 through step 11 for each index as needed.
- Scroll to the top or bottom and click OK.
The new element range index or element word lexicon is added to the database. These rules are applied to XML and JSON documents loaded into the specified database from this point on.
If you have reindexing enabled for the database and you specify an element that exists in a document, reindexing will run in the background. When the reindexing is complete, the new index will become available to queries.
Viewing Attribute Range Index Settings
To view the attribute range indexes that will be applied to documents as they are loaded or reindexed, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to view a range index, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to view a range index.
- Click the Attribute Range Indexes icon in the tree menu, under the selected database.
Defining Attribute Range Indexes
To define a range index for an attribute of a particular element, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to create an index, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to create an index.
- Under the selected database, click the Attribute Range Indexes icon in the tree menu for an attribute range index.
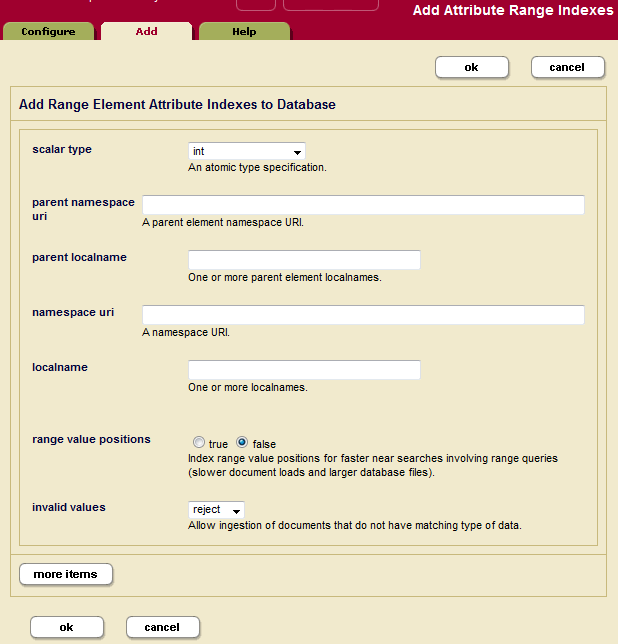
- Click the Add tab. The Add Attribute Range Indexes page displays:
- Select the type of the XML attribute for which you want to build an attribute range index.
- If the index is of type
xs:string, a collation box appears with a default collation. If you want the index to use a different collation than the default, enter the collation URI. You can click the Collation Builder button for a wizard that constructs the collation URI for you based on the language and other parameters you enter. For details about collations, see the Language Support in MarkLogic Server chapter in the Search Developer's Guide. - Enter the namespace URI of the XML element that contains the attribute you want to index into the parent namespace URI field.
Every XML element is associated with a namespace. For the description of the element to be precise, you must specify the namespace of the XML element. The asterisk (*) cannot be used to indicate namespace independence. Leaving the namespace URI field blank specifies the universal unnamed namespace.
- Enter the element name in the parent localname field.
The local name is the name of the XML element that contains the attribute to be indexed. If you have more than one element in the same namespace that contains the attribute you want to index, you can provide a comma-separated list of element names.
- Enter the namespace URI of the attribute that you want to index into the namespace URI field.
Every XML attribute is associated with a namespace. For the description of the attribute to be precise, you must specify the namespace of the XML attribute. The asterisk (*) cannot be used to indicate namespace independence. Leaving the namespace URI field blank specifies the universal unnamed namespace.
- Enter the attribute name in the localname field.
The local name is the name of the XML attribute to be indexed. If you have more than one attribute in the same namespace within the specified parent element(s) that you want to index, you can provide a comma-separated list of attribute names.
- Choose whether to index range value positions for this index. Setting the value to
truewill speed the performance of searches that use cts:near-query and cts:element-query with this index, but will use more disk space than leaving the positions off (range value positionsfalse). - In the invalid values field, choose whether to allow insertion of documents that contain attributes on which range index is configured, but the value of those attributes cannot be coerced to the index data type. It can be configured to either
ignoreorreject. By default server rejects insertion of such documents. However, if a user configures invalid values to ignore, these documents can be inserted. This setting does not change the behavior of queries on invalid values after documents are inserted in the database. Performing an operation on an invalid value at query time can still result in an error. - To add more indexes, click the More Items button and repeat step 6 through step 13 for each attribute index as needed.
- Scroll to the top or bottom and click OK.
The new attribute index is added to the database. These rules are applied to XML documents loaded into the specified database from this point on.
If you have reindexing enabled for the database and you specify an element-attribute pair that exists in a document, reindexing will run in the background. When the reindexing is complete, the new index will become available to queries.
Viewing Path Range Index Settings
To view the path range indexes that will be applied to documents as they are loaded or reindexed, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to view a range index, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to view a range index.
- Click the Path Range Indexes icon in the tree menu, under the selected database.
Defining Namespace Prefixes Used in Path Range Indexes and Fields
When you define a path range index over XML documents and your path uses namespace prefixes, you must pre-define any namespace bindings used in the path expression. These namespace bindings can be used by multiple path range indexes.
To define a namespace binding, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to create a namespace prefix binding, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to create a namespace binding.
- Click the Path Namespaces icon in the tree menu, under the selected database.
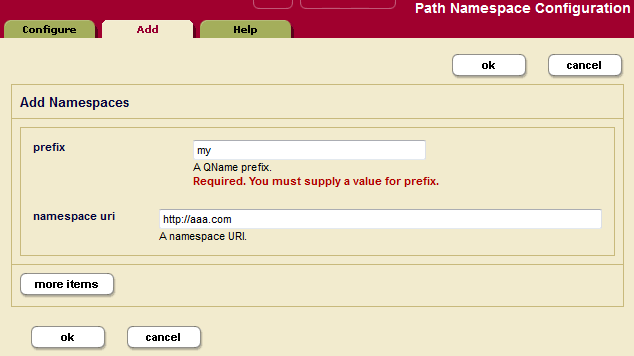
- Click the Add tab. The Path Namespaces Configuration page displays:
- In the Prefix field, enter the namespace prefix you intend to use for the element or attribute in the XPath expression in your path range index.
- In the Namespace URI field, enter the namespace URI of the XML element or attribute in the XPath expression.
- Click OK.
Defining Path Range Indexes
To define a range index expressed by an XPath expression, perform the following steps:
- If you are creating a path range index over XML data, create bindings for any namespaces prefixes used in your index XPath expression. For details, see Defining Namespace Prefixes Used in Path Range Indexes and Fields.
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to create a range index, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to create a range index.
- Click the Path Range Indexes icon in the tree menu, under the selected database.
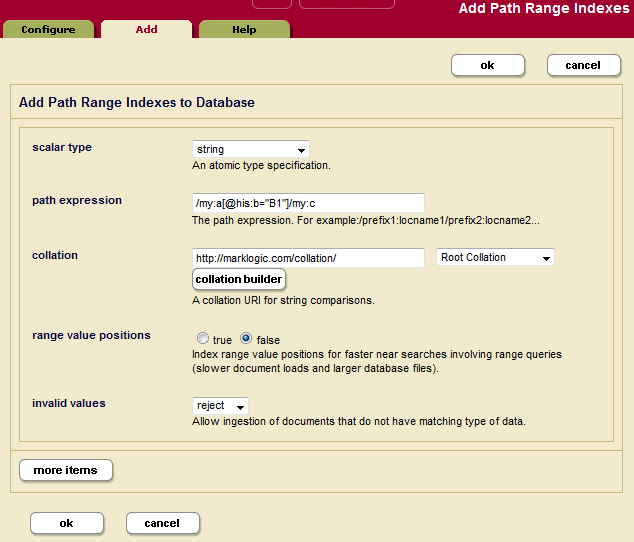
- Click the Add tab. The Path Range Index Configuration page displays:
- Select the type of the XML element, XML attribute, or JSON property for which you want to build a range index.
- If the index is of type
xs:string, a collation box appears with a default collation. If you want the index to use a different collation than the default, enter the collation URI. You can click the Collation Builder button for a wizard that constructs the collation URI for you based on the language and other parameters you enter. For details about collations, see the Language Support in MarkLogic Server chapter in the Search Developer's Guide. - Enter the XPath expression in the path expression field. For XML, you can use any namespace prefix you created in step 1. XPath expressions are summarized in XPath Quick Reference in the XQuery and XSLT Reference Guide. Not all XPath features are supported by path range indexes. For details, see Understanding Path Range Indexes.
You can use the cts:valid-index-path function to test whether the path is syntactically correct for use in a path range index.
You cannot have a path span across a fragment root. Paths should be scoped within fragment roots
- Choose whether to index range value positions for this index. Setting the value to
truewill speed the performance of searches that use cts:near-query,cts:element-query, and cts:json-property-scope-query with this index, but will use more disk space than leaving the positions off (range value positionsfalse). - In the invalid values field, choose whether to allow insertion of documents that contain XML elements, XML attributes, or JSON properties on which range index is configured, but the value of those elements, attributes, or properties cannot be coerced to the index data type. It can be configured to either
ignoreorreject. By default server rejects insertion of such documents. However, if a user configures invalid values to ignore, these documents can be inserted. This setting does not change the behavior of queries on invalid values after documents are inserted in the database. Performing an operation on an invalid value at query time can still result in an error. - To add more indexes, click the More Items button and repeat step 7 through step 11 for each index as needed.
- Scroll to the top or bottom and click OK.
The new path range index is added to the database. These rules are applied to XML or JSON documents loaded into the specified database from this point on.
If you have reindexing enabled for the database and you specify an XML element, XML attribute, or JSON property that exists in a document, reindexing will run in the background. When the reindexing is complete, the new index will become available to queries.
Once you have created a path range index, you cannot change the path expression. Instead, you must remove the existing path range index and create a new one with the updated path expression.
Viewing Element Word Lexicon Settings
To view the lexicon that will be applied to documents as they are loaded or reindexed, perform the following steps:
Defining Element Word Lexicons
To define a lexicon for an XML element or JSON property, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to create lexicon, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to create a lexicon.
- Click the Element Word Lexicons icon in the tree menu, under the selected database.
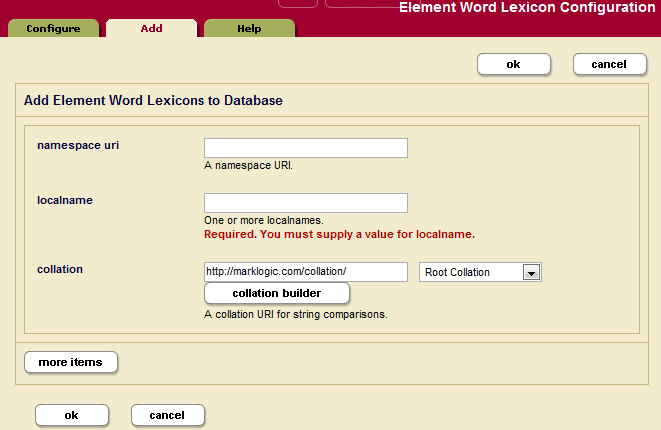
- Click the Add tab. The Element Word Lexicon Configuration page displays:
- If you are defining a lexicon on an XML element, enter the namespace URI of the XML element.
Every XML element is associated with a namespace. For the description of the element to be precise, you must specify the namespace of the XML element. The asterisk (*) cannot be used to indicate namespace independence. Leaving the namespace URI field blank specifies the universal unnamed namespace.
- Enter the XML element or JSON property name in the localname field.
The local name is the name of the XML element or JSON property to be indexed. If you have more than one element of the same type in the same namespace that you want to index or more than one property name, you can provide a comma-separated list of names.
- The collation box appears with a default collation. If you want the lexicon to use a different collation than the default, enter the collation URI. You can click the Collation Builder button for a wizard that constructs the collation URI for you based on the language and other parameters you enter. For details about collations, see the Language Support in MarkLogic Server chapter in the Search Developer's Guide.
- To add more word lexicons, click the More Items button and repeat step 6 through step 8 for each lexicon as needed.
- Scroll to the top or bottom and click OK.
The new range index or word lexicon is added to the database. These rules are applied to XML or JSON documents loaded into the specified database from this point on.
If you have reindexing enabled for the database and you specify an element that exists in a document, reindexing will run in the background. When the reindexing is complete, the new index will become available to queries.
Viewing Attribute Word Lexicon Settings
To view the lexicon that will be applied to documents as they are loaded or reindexed, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to view a lexicon, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to view a lexicon.
- Click the Attribute Word Lexicons icon in the tree menu, under the selected database.
Defining Attribute Word Lexicons
To define a lexicon for an attribute of a particular element, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to create a lexicon, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to create a lexicon.
- Under the selected database, click the Attribute Word Lexicon icon.
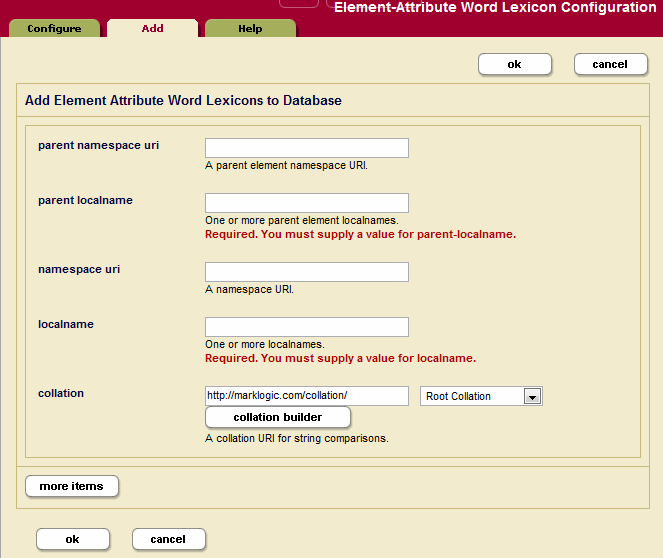
- Click the Add tab. The Element-Attribute Word Lexicon Configuration page displays:
- Enter the namespace URI of the XML element that contains the attribute you want to index into the parent namespace URI field.
Every XML element is associated with a namespace. For the description of the element to be precise, you must specify the namespace of the XML element. The asterisk (*) cannot be used to indicate namespace independence. Leaving the namespace URI field blank specifies the universal unnamed namespace.
- Enter the element name in the parent localname field.
The local name is the name of the XML element that contains the attribute to be indexed. If you have more than one element in the same namespace that contains the attribute you want to index, you can provide a comma-separated list of element names.
- Enter the namespace URI of the attribute that you want to index into the namespace URI field.
Every XML attribute is associated with a namespace. For the description of the attribute to be precise, you must specify the namespace of the XML attribute. The asterisk (*) cannot be used to indicate namespace independence. Leaving the namespace URI field blank specifies the universal unnamed namespace.
- Enter the attribute name in the localname field.
The local name is the name of the XML attribute to be indexed. If you have more than one attribute in the same namespace within the specified parent element(s) that you want to index, you can provide a comma-separated list of attribute names.
- The collation box appears with a default collation. If you want the lexicon to use a different collation than the default, enter the collation URI. You can click the Collation Builder button for a wizard that constructs the collation URI for you based on the language and other parameters you enter. For details about collations, see the Language Support in MarkLogic Server chapter in the Search Developer's Guide.
- To add more element-attribute word lexicons, click the More Items button and repeat step 6 through step 10 for each attribute index as needed.
- Scroll to the top or bottom and click OK.
The new attribute index or attribute word lexicon is added to the database. These rules are applied to XML documents loaded into the specified database from this point on.
If you have reindexing enabled for the database and you specify an element-attribute pair that exists in a document, reindexing will run in the background. When the reindexing is complete, the new index will become available to queries.
Defining Value Lexicons
Value lexicons are implemented using range indexes of type xs:string on the element(s), attribute(s), JSON properties, or fields specified in a query. Therefore, to create a value lexicon, you create a range index of type xs:string for the specified element(s), attribute(s), JSON properties, or fields. Use an element range index for a JSON property value lexicon.
Deleting Range Indexes or Lexicons
To delete element or attribute indexes or lexicons for a specific database, perform the following steps:
- Click the Databases icon on the left tree menu.
- Locate the database for which you want to delete a range index or lexicon, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to delete a range index or lexicon.
- Determine whether you need to delete an element range index, an attribute range index, an element word lexicon, or an attribute word lexicon.
- Click the Element Range Index icon, Attribute Range Index icon, Path Range Index icon, Element Word Lexicon icon, or the Attribute Word Lexicon icon. The configuration page for the appropriate index appears.
- Locate the index you want to delete and click Delete.
- A confirmation message displays. Confirm the delete and click OK.
Defining Field Range Indexes
Fields provide a convenient mechanism for querying a portion of the database based on XML element QNames or JSON property names. You can define a field, and then create a range index or word or value lexicon over it. For details, see Fields Database Settings.