Backing Up Databases with Journal Archiving
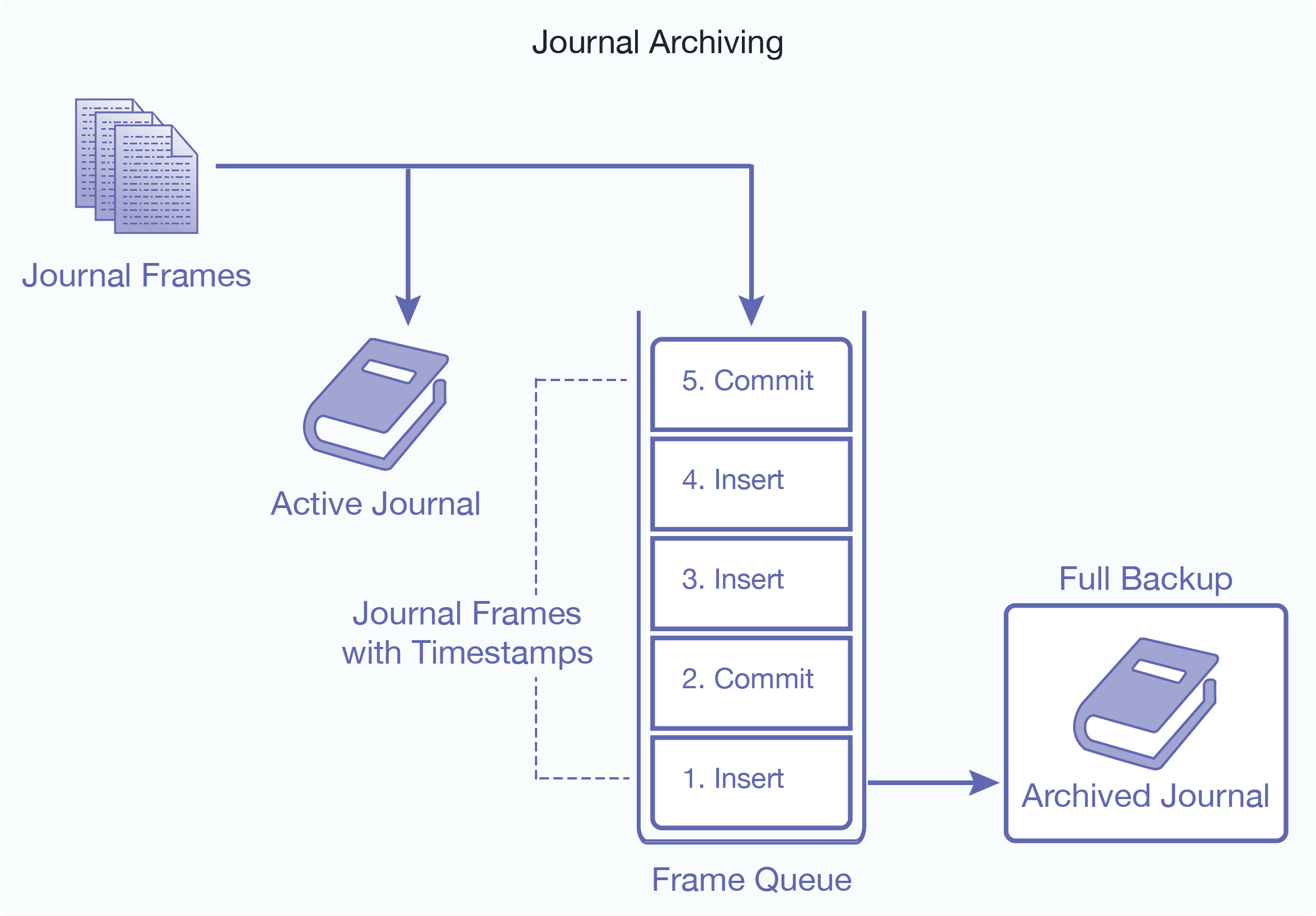
The backup/restore operations with journal archiving enabled provide a point-in-time recovery option that enables you to restore database changes to a specific point in time between full backups with the input of a wall clock time. When journal archiving is enabled, journal frames are written to backup directories by near synchronously streaming frames from the current active journal of each forest.
Note
When you create scheduled backups with journal archiving enabled, and then later delete the backup, it does not stop journal archiving from occurring even though the backups stop happening. The xdmp:stop-journal-archiving function must be explicitly called to stop journal archiving.
When journal archiving is enabled, you will experience longer restore times and slightly increased system load as a result of the streaming of journal frames.
Note
Journal archiving can only be enabled at the time of a full backup. If you restore a backup and want to reenable journal archiving, you must perform a full backup at that time.
When journal archiving is enabled, you can set a lag limit value that specifies the amount of time (in seconds) in which frames being written to the forest's journal can differ from the frames being streamed to the backup journal. For example, if the lag limit is set to 30 seconds, the archived journal can lag behind a maximum of 30 seconds worth of transactions compared to the active journal. If the lag limit is exceeded, transactions are halted until the backup journal has caught up.
The active and backup journal are synchronized at least every 30 seconds. If the lag limit is less than 30 seconds, synchronization will be performed at least once in that period. If the lag limit is greater than 30 seconds, synchronization will be performed at least once every 30 seconds. The default lag limit is 15 seconds.
The decision on setting a lag limit time is determined by your Recovery Point Objective (RPO), which is the amount of data you can afford to lose in the event of a disaster. A low RPO means that you will restore the most data at the cost of performance, whereas a higher RPO means that you will potentially restore less data with the benefit of less impact to performance. In general, the lag limit you chose depends on the following factors:
A lower lag limit implies:
Accurate synchronization between active and backup journals at the potential cost of system performance.
Use when you have an archive location with high I/O bandwidth and your RPO objective is low.
A higher lag limit implies:
Delayed synchronization between active and backup journals, but lesser impact on system performance.
Higher server memory utilization due to pending frames being held in memory.
Use when you have an archive location with low I/O bandwidth and your RPO objective is high.