Matches for cat:guide/sql (cat:guide) have been highlighted.


MarkLogic Server 11.0 Product DocumentationSQL Data Modeling Guide — Chapter 4
Creating Range Views
This chapter describes how to configure MarkLogic Server and create range views to model your MarkLogic data for access by SQL. Range views can also be created using the Views API described in MarkLogic XQuery and XSLT Function Reference. You must have the admin role on MarkLogic Server to complete the procedures described in this chapter.
In most situations, you will want to create a template view, as described inCreating Template Views. Though a range view may be preferable to a template view in some situations, such as for a database already configured with range indexes, they are supported mostly for backwards compatibility with previous versions of MarkLogic.
- Creating Range Indexes for Column Specifications
- Creating Searchable Fields for use by Views
- Creating a View
- Data Modeling Example
- Guidelines for Relational Behavior
- Limitations to SQL Support
- Errors, Exceptions, and Diagnostics
Creating Range Indexes for Column Specifications
You must create range indexes for a database before creating view columns that make use of the range indexes. In addition, range indexes are constructed during the document loading process, so they should be created before you load any XML documents into the database, otherwise the content must be either reindexed or reloaded to take advantage of the new range indexes. For details on how to create range indexes, see Range Indexes and Lexicons in the Administrator's Guide.
The following table lists the types range indexes that can be used for columns.
Creating Searchable Fields for use by Views
Fields provide a convenient mechanism for querying a portion of the database based on element QNames. A field can be defined for one or more elements, as described in Fields Database Settings in the Administrator's Guide. Binding a field to a view is useful when you don't want to create a column on the element, but you want the ability to query content in one or more elements simply and efficiently as a single unit. The procedure for binding a field to a view is described in Creating View Fields.
Field values are computed by concatenating tokens from all the included elements of a field. However, efficient evaluation of range queries on field values will need range indexes on these values, as described in Creating a Range Index on a Field in the Administrator's Guide.
Creating a View
Each column in a view has a name and a range index reference. You can create a schemas and views using the XQuery view API or by means of the REST API.
This section describes how to create views using the REST API with the JSON document format. The topics are:
- Naming the View
- Creating and Setting the Schema
- Setting Schema and View Permissions
- Creating View Columns
- Creating View Columns for URI and Collection Lexicons
- Creating View Fields
- Defining View Scope
Naming the View
The view name must be unique in the context of the schema in which it is created. A valid view name is a single word that starts with an alpha character. The view name may contain numeric characters, but, with the exception of underscores (...Äò_'), cannot contain punctuation or special characters.
For example, to create a view, named employees:
"name": "employees"
Creating and Setting the Schema
As described in Schemas and Views, a schema is a naming context for a set of views. Each view must belong to a schema. A schema created in this manner can support both Range Views and Template Views.
Every SQL deployment must include a default schema, called "main." The main schema is created automatically and is the default schema set for new views. To create a new schema, check the New Schema button and enter the name of the schema in the adjacent field.
The schema name must be unique. A valid schema name is a single word that starts with an alpha character. The schema name may contain numeric characters, but, with the exception of underscores (...Äò_'), cannot contain punctuation or special characters.
You can use POST /manage/v2/databases/{id|name}/view-schemas to create a new schema. For example to create a schema, named mySchema, for the SQLdata database:
curl -X POST --anyauth --user admin:admin \ --header "Content-Type:application/json" \ -d '{"view-schema-name": "mySchema"}' \ http://gordon-2:8002/manage/v2/databases/SQLdata/view-schemas?format=json
You can use PUT:/manage/v2/databases/{id|name}/view-schemas/{schema-name}/views/{id|name}/properties to set or add permissions to a schema.
Setting Schema and View Permissions
Permissions set on a schema and/or view determine which users have access to the schema or view. A permission consists of a role name, such as app-user, and a capability, such as read, insert, update, or execute. Users are assigned roles, as described in Role-Based Security Model in the Security Guide. You can enable and disable views for different users by assigning permissions that correspond to a particular user's role, along with the capabilities you want that users to possess for that view.
By default, views are assigned the following permissions:
- sql-execution(read)
- view-admin(read)
- view-admin(update)
Unlike other documents, user default permissions are not assigned to the view or schema.
This means that users with the sql-execution role can execute SQL SELECT statements and get functions on the view, such as view:get or view:get-column, but cannot modify or otherwise manage the view. Only users with both the sql-execution and view-admin roles can fully access and manage views.
You can use the view API to set additional permissions on a schema or view to further restrict which users can access the schema or view. You set permissions on a schema by calling view:schema-set-permissions on an existing schema or by calling view:schema-create when creating a new schema. You set permissions on a view by calling view:set-permissions on an existing view or by calling view:create when creating a new view.
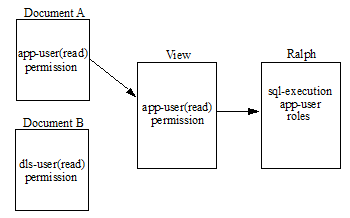
Schemas and views are simply documents stored in a schema database, so setting permissions on a schema or view has the same security implications as permissions set on any other type of document. This means a user must be assigned the correct roles to access the view. For example, Ralph has the sql-execution and app-user role. You set a view with the app-user(read) permission. This means that Ralph can read data from the view, but only documents that are loaded with the app-user(read) permission. Now, let's say we have documents that were loaded with the dls-user(read) permission. Ralph does not have the dls-user role, so he cannot read the data from these documents from this or any other view.
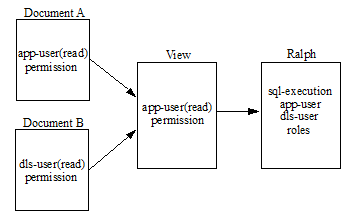
However, if we assign the dls-user role to Ralph, he can now read the documents loaded with the dls-user(read) permission through the view, regardless of the permissions set on the view. In this way, the permissions set on the view control only which users can access the view, rather than which documents can be seen through the view.
Creating View Columns
When creating columns in your view be sure that their settings map to the range index to be used for the column. The table below describes the JSON payload to create a column for each type of range index.
Range indexes on elements or attributes of type string are associated with a collation that specify the order in which strings are sorted and how they are compared. A collation is required for columns that use path and field range indexes and are optional for columns that use element and attribute range indexes. For more details on collations, see Collations in the Search Developer's Guide.
To make the column nullable, specify nullable as true:
"nullable":true
For example, to specify the subject column as nullable:
{ "column-name": "subject", "element-reference": { "namespace-uri": "", "localname": "subject", "scalar-type": "string", "nullable":true} }
Creating View Columns for URI and Collection Lexicons
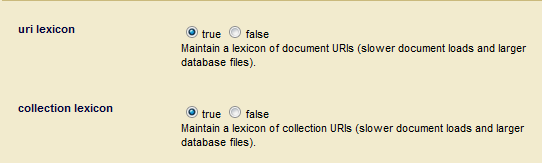
In addition to range indexes, you can also create view columns for uri and collection lexicons, as described in URI and Collection Lexicons in the Search Developer's Guide. To create columns on uri and/or collection lexicons, you must enable the capability for the database.
- In the Admin Interface, open the database that contains your content and scroll down to the uri and collection lexicon fields. Click on true to enable either or both types of lexicons.
- To create a column for the uri lexicon, use:
{"column-name":"uri", "uri-reference":null}
- To create a column for the collection lexicon, use:
{"column-name":"collection", "collection-reference":null}
Creating View Fields
The following procedure describes how to bind a field to a view.
- Create a searchable field, as described in Creating Searchable Fields for use by Views.
- In the view description, enter:
"field-reference": [{ "field-name": "name", }]
For example, to create a view field for the position field:
"field-reference": [{ "field-name": "position" }]
Defining View Scope
The scope of the view is used to constrain the view to the documents in a particular collection. The scope is optional, so do not specify a scope if you elect not to set the scope of the view.
To set the scope for a collection, use collection-scope and enter the collection uri.
"collection-scope":{ "collection":"/xdmp/view/messages"}
Data Modeling Example
Data stored in MarkLogic Server is typically unstructured. The data modeling challenge is to determine how to identify the XML elements and attributes in the data and present them as relational. The purpose of this section is to provide an example of how unstructured data, such as emails, might be modeled for SQL access.
The Email Data
The procedures in this section assume you are loading documents like the following in your content database. The elements highlighted in yellow are those to be modeled as columns in the view.

The Range Indexes
This section describes how to create the range indexes for the view described in The View.
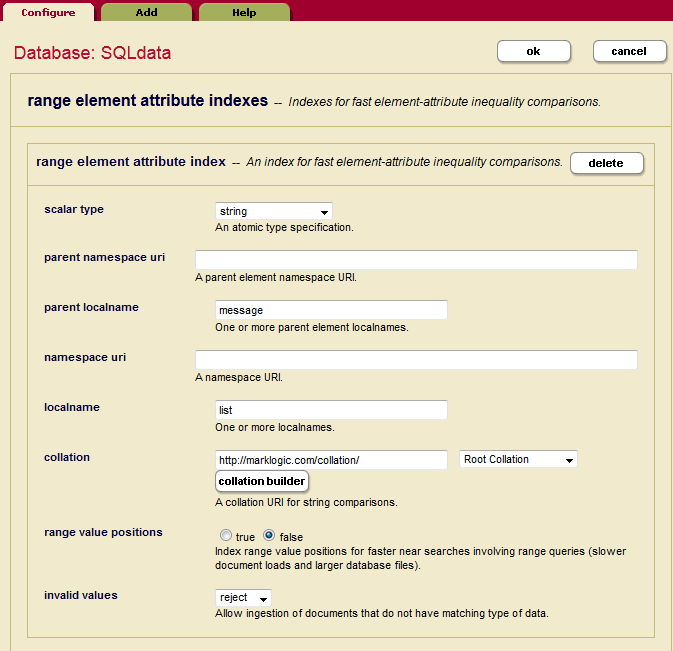
Create an Attribute Range Index for the 'list' attribute in the message element:
Create an Element Range Index for the subject element:
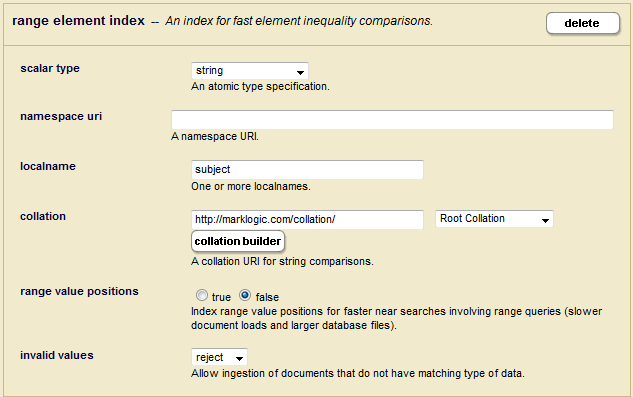
Create additional Element Range Indexes for the following elements:.
| Local Name | Scalar Type |
|---|---|
function |
string |
name |
string |
affiliation |
string |
When you want to create columns for an element of the same name, but with different parent elements, you can create path range indexes for each. For example, in our message document we have url elements with different parents, para and note. In order to define these as separate columns
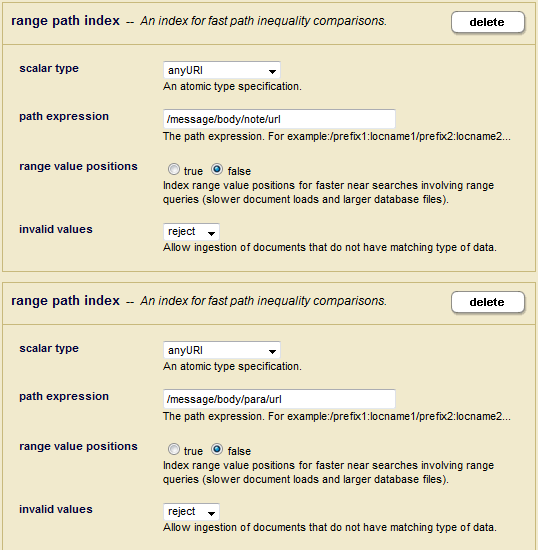
The View
Create a view, named 'mail.' The following call to POST /manage/v2/databases/{id|name}/view-schemas/{schema-name}/views creates a view with columns for all of the range indexes created in The Range Indexes.
curl -X POST --anyauth --user admin:admin \ --header "Content-Type:application/json" \ -d '{ "view-schema-name": "mail", "column": [ { "column-name": "message_list", "element-attribute-reference": { "namespace-uri":"", "parent-namespace-uri" : "", "parent-localname": "message", "localname": "list", "scalar-type": "string" } }, { "column-name": "subject", "element-reference": { "namespace-uri": "", "localname": "subject", "scalar-type": "string" } }, { "column-name": "function", "element-reference": { "namespace-uri": "", "localname": "function", "scalar-type": "string" } }, { "column-name": "name", "element-reference": { "namespace-uri": "", "localname": "name", "scalar-type": "string" } }, { "column-name": "affiliation", "element-reference": { "namespace-uri": "", "localname": "affiliation", "scalar-type": "string" } }, { "column-name": "body_url", "path-reference": { "path-expression": "/message/body/url", "scalar-type": "anyURI" } }, { "column-name": "para_url", "path-reference": { "path-expression": "/message/body/para/url", "scalar-type": "anyURI" } } ] }' \ http://gordon-2:8002/manage/v2/databases/SQLdata/view-schemas/main/views?format=json
Guidelines for Relational Behavior
For conventional relational behavior, data should be modeled such that:
- Every document represents exactly one row.
- Every row has at least one column that is declared as non-nullable. If this is not possible, then you should enable the URI lexicon.
- Every non-nullable column is present in every document.
- Sufficient range indexes are enabled so that a query constraining the presence of a column can be resolved from the index.
- Sufficient range indexes are enabled so that a query representing a where clause constraint can be resolved from the index. For simple relations (equals, less than, etc.), such constraints can and will be checked redundantly by the SQL VM, but full-text constraints cannot and will not. Full-text constraints on a URI or collection column will not work.
Nullable columns impede performance, so you should avoid them when possible. A column that has no null values is one that may or may not be declared nullable. In other words, nullable is about the configuration and has no null values is about the data.
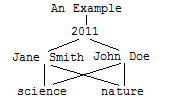
Consider an XML document of the following form, with element range indexes on the title, pubyear, author, and keyword elements and a view, named books, defined over those range indexes:
<book> <title>An Example</title> <pubyear>2011</pubyear> <author>Jane Smith</author> <keyword>science</keyword> <author>John Doe</author> <keyword>nature</keyword> <body> Lots of exciting full text content here... </body> </book>
The same document can be expressed in JSON as follows:
{"book": { "title" : "An Example", "pubyear" : "2011", "author" : ["Jane Smith", "John Doe"], "keyword" : ["science", "nature"], "body": "Lots of exciting full text content here..."} }
Because this document contains two author and keyword elements at the same level, it violates the first data modeling rule listed above. As a result, a select * on this view will produce multiple rows for the single document:
select * from books => | title | pubyear| author | keyword --------------+---------+------------+--------- | An Example | 2011 | Jane Smith| science | An Example | 2011 | Jane Smith| nature | An Example | 2011 | John Doe | science | An Example | 2011 | John Doe | nature
Each time a view encounters a column element in a document, it returns the contents of its associated range index. In the above example, the contents of the range indexes associated with this document are:
The results of the query are the cross-product of these indexes. As a result, four rows are returned:
If cross-product results are undesirable, avoid queries that return more than one range index containing multiple values for the document. For example, you could omit the keyword column:
select title, pubyear, author from books => | title | pubyear| author --------------+---------+------------ | An Example | 2011 | Jane Smith | An Example | 2011 | John Doe
In other circumstances, you might want to set a root fragment on the database. For example, your document data is structured as follows:
<book> <chapter> <title>Chapter 1</title> <section>Section 1</section> <section>Section 2</section> <section>Section 3</section> <section>Section 4</section> </chapter> <chapter> <title>Chapter 2</title> <section>Section 1</section> <section>Section 2</section> </chapter> </book>
You create a view, named books, on the title and section elements. The results of a select * query are:
select * from books => title | section ----------+----------- Chapter 1 | Section 1 Chapter 1 | Section 1 Chapter 1 | Section 2 Chapter 1 | Section 2 Chapter 1 | Section 3 Chapter 1 | Section 4 Chapter 2 | Section 1 Chapter 2 | Section 1 Chapter 2 | Section 2 Chapter 2 | Section 2 Chapter 2 | Section 3 Chapter 2 | Section 4 (12 rows)
Creating a fragment root on the chapter element makes the document appear to the view as two separate documents, each with chapter as their root element. The details on defining fragments on a database, are described in Fragments in the Administrator's Guide.
Now, with a fragment root set on the chapters element, the results of a select * query are:
select * from books => title | section -----------+----------- Chapter 1 | Section 1 Chapter 1 | Section 2 Chapter 1 | Section 3 Chapter 1 | Section 4 Chapter 2 | Section 1 Chapter 2 | Section 2 (6 rows)
In other situations, you might want to create more than one view for a particular document structure. For example, your document data is structured as follows:
<book> <meta> <title>An Example</title> <pubyear>2011</pubyear> <author>Jane Smith</author> <keyword>science</keyword> </meta> <chapter> <title>Chapter 1</title> <section>Section 1</section> <section>Section 2</section> <section>Section 3</section> <section>Section 4</section> </chapter> <chapter> <title>Chapter 2</title> <section>Section 1</section> <section>Section 2</section> </chapter> </book>
The views are defined as follows:
| View Name | Columns |
|---|---|
meta |
title
pubyear
author
keyword |
chapter |
title
section |
Limitations to SQL Support
The SQL supported by MarkLogic Server is SQL92 with some additions and extensions as noted.
- Triggers, coherency constraints, keys, and foreign keys are not supported.
- MarkLogic views are read-only. You cannot update, delete, or insert data into a view. You cannot manage data stored in MarkLogic through DDL statements in SQL.
- SQL statements operate on range indexes in MarkLogic. If the information is not in a range index, it is not available via SQL. Exception: the whole document is available as a special hidden column which can be a target for a search constraint.
- Search constraints are unfiltered.
- The MATCH operator (full-text search) will not work on columns backed by the URI or collection lexicons.
- There must be exactly one row in each fragment and one fragment in each row. Failure to do so will produce anomalous results that may cause trouble for consuming applications. For example, if a fragment contains more than one row, where clause constraints on that row will only rule out fragments for which none of the rows matches the where clause constraint unless redundant checking is enabled (and even if it is for full-text constraints). If a row spans multiple fragments, it may not be selected when it should.
Errors, Exceptions, and Diagnostics
Errors will be thrown if attempts are made to use views that lack the necessary backing range indexes, or to use them in a way that those backing range indexes do not support (for example, a view cannot be ordered unless all the backing range indexes have positions). Errors will be thrown if the SQL statement is invalid, or the SQL engine encounters some kind of problem. In general, all errors encountered in processing SQL statements will be thrown as SQL-ERROR.
The following errors may be thrown when creating or modifying a view:
You can use trace events to write SQL operations on MarkLogic Server to the log:
To use the trace events, you must enable tracing (at the group level) for your configuration and set events. Perform the following to enable and set trace events:
- Log into the Admin Interface.
- Select Groups > group_name > Diagnostics.
- Click the
truebutton fortrace events activated. - Enter the trace events described in the above table you want to enable.
- Click the OK button to activate the events.
After you configure the trace events, when any of the configured events occur, a line is added to the ErrorLog.txt file, indicating which document is involved the event.
The trace events are designed as development and debugging tools, and they might slow the overall performance of MarkLogic Server. Also, enabling many trace events will produce a large quantity of messages, especially if you are processing a high volume of documents. When you are not debugging, disable the trace event for maximum performance.