
MarkLogic Server 11.0 Product DocumentationSearch Developer's Guide — Chapter 9
Relevance Scores: Understanding and Customizing
Search results in MarkLogic Server return in relevance order; that is, the result that is most relevant to the cts:query expression in the search is the first item in the search return sequence, and the least relevant is the last. There are several tools available to control the relevance score associated with a search result item. This chapter describes the different methods available to calculate relevance, and includes the following sections:
- Understanding How Scores and Relevance are Calculated
- How Fragmentation and Index Options Influence Scores
- Using Weights to Influence Scores
- Proximity Boosting With the distance-weight Option
- Boosting Relevance Score With a Secondary Query
- Including a Range or Geospatial Query in Scoring
- Interaction of Score and Quality
- Using cts:score, cts:confidence, and cts:fitness
- Relevance Order in cts:search Versus Document Order in XPath
- Exploring Relevance Score Computation
- Sample cts:search Expressions
Understanding How Scores and Relevance are Calculated
When you perform a cts:search operation, MarkLogic Server produces a result set that includes items matching the cts:query expression and, for each matching item, a score. The score is a number that is calculated based on statistical information, including the number of documents in a database, the frequency in which the search terms appear in the database, and the frequency in which the search term appears in the document. The relevance of a returned search item is determined based on its score compared with other scores in the result set, where items with higher scores are deemed to be more relevant to the search. By default, search results are returned in relevance order, so changing the scores can change the order in which search results are returned.
As part of a cts:search expression, you can specify the following different methods for calculating the score, each of which uses a different formula in its score calculation:
- log(tf)*idf Calculation
- log(tf) Calculation
- Simple Term Match Calculation
- Random Score Calculation
- Term Frequency Normalization
You can use the relevance-trace option with cts:relevance-info to explore score calculations in detail. For details, see Exploring Relevance Score Computation.
log(tf)*idf Calculation
The logtfidf method of relevance calculation is the default relevance calculation, and it is the option score-logtfidf of cts:search. The logtfidf method takes into account term frequency (how often a term occurs in a single fragment) and document frequency (in how many documents does the term occur) when calculating the score. Most search engines use a relevance formula that is derived by some computation that takes into account term frequency and document frequency.
The logtfidf method (the default scoring method) uses the following formula to calculate relevance:
log(term frequency) * (inverse document frequency)
The term frequency is a normalized number representing how many terms are in a document. The term frequency is normalized to take into account the size of the document, so that a word that occurs 10 times in a 100 word document will get a higher score than a word that occurs 100 times in a 1,000 word document.
The inverse document frequency is defined as:
log(1/df)
where df (document frequency) is the number of documents in which the term occurs.
For most search-engine style relevance calculations, the score-logtfidf method provides the most meaningful relevance scores. Inverse document frequency (IDF) provides a measurement of how information rich a document is. For example, a search for the or dog would probably put more emphasis on the occurences of the term dog than of the term the.
log(tf) Calculation
The option score-logtf for cts:search computes scores using the logtf method, which does not take into account how many documents have the term. The logtf method uses the following formula to calculate scores:
log(term frequency)
where the term frequency is a normalized number representing how many terms are in a document. The term frequency is normalized to take into account the size of the document, so that a word that occurs 10 times in a 100 word document will get a higher score than a word that occurs 100 times in a 1,000 word document.
When you use the logtf method, scores are based entirely on how many times a document matches the search term, and does not take into account the information richness of the search terms.
Simple Term Match Calculation
The option score-simple on cts:search performs a simple term-match calculation to compute the scores. The score-simple method gives a score of 8*weight for each matching term in the cts:query expression, and then scales the score up by multiplying by 256. It does not matter how many times a given term matches (that is, the term frequency does not matter); each match contributes 8*weight to the score. For example, the following query (assume the default weight of 1) would give a score of 8*256=2048 for any fragment with one or more matches for hello, a score of 16*256=4096 for any fragment that also has one or more matches for goodbye, or a score of zero for fragments that have no matches for either term:
cts:or-query(("hello", "goodbye"))
Use this option if you want the scores to only reflect whether a document matches terms in the query, and you do not want the score to be relative to frequency or information-richness of the term.
Random Score Calculation
The option score-random on cts:search computes a randomly-generated score for each search match. You can use this to randomly choose fragments matching a query. If you perform the same search multiple times using the score-random option, you will get different ordering each time (because the scores are randomly generated at runtime for each search).
Term Frequency Normalization
The scoring methods that take into account term frequency (score-logtfidf and score-logtf) will, by default, normalize the term frequency (how many search term matches there are for a document) based on the size of the document. The idea of this normalization is to take into account how frequent a term occurs in the document, relative to the other documents in the database. You can think of this is the density of terms in a document, as opposed to simply the frequency of the terms. The term frequency normalization makes a document that has, for example, 10 occurrences of the word "dog" in a 10,000,000 word document have a lower relevance than a document that has 10 occurrences of the word "dog" in a 100 words document. With the default term frequency normalization of scaled-log, the smaller document would have a higher score (and therefore be more relevant to the search), because it has a greater term density of the word "dog". For most search applications, this behavior is desirable.
If you would like to change that behavior, you can set the tf normalization option on the database configuration to lessen or eliminate the effects of the size of the matching document in the score calculation, which in turn would strengthen the effect of its term frequency (the number of matches in that document). The unscaled-log option does no scaling based on document size, and the scaled-log option (the default) does the maximum scaling of the document based on document size. Additionally, there are four intermediate settings, weakest-scaled-log, weakly-scaled-log, moderately-scaled-log, and strongly-scaled-log, which have increasing degrees of scaling in between none and the most scaling. If you change this setting in the database and reindexer enable is set to true, then the database will begin reindexing.
How Fragmentation and Index Options Influence Scores
Scores are calculated based on index data, and therefore based on unfiltered searches. That has several implications to scores:
- Scores are fragment-based, so term frequency and document frequency are calculated based on term frequency per fragment and fragment frequency respectively.
- Scores are based on unfiltered searches, so they include false-positive results.
Because scores are based on fragments and unfiltered searches, index options will affect scores, and in some case will make the scores more accurate; that is, base the scores on searches that return fewer false-positive results. For example, if you have word positions enabled in the database configuration, searches for three or more term phrases will have fewer false-positive matches, thereby improving the accuracy of the scores.
For details on unfiltered searches and how you can tell if there are false-positive matches, see Using Unfiltered Searches for Fast Pagination in the Query Performance and Tuning Guide.
Using Weights to Influence Scores
Use a weight in a query sub-expression to either boost or lower the sub-expression contribution to the relevance score.
For example, you can specify weights for leaf-level cts:query constructors, such as cts:word-query and cts:element-value-query; for details, see XQuery and XSLT Reference Guide. You can also specify weights in the equivalent Search API abstractions, such as the structured query constructs value-query and word-constraint-query, or when defining a word or value constraint in query options.
The default weight is 1.0. Use the following guidelines for choosing custom weights:
- To boost the score contribution, set the weight higher than 1.0.
- To lower the score contribution, set the weight between 0 and 1.0.
- To contribute nothing to the score, set the weight to 0.
- To make the score contribution negative, set the weight to a negative number.
Scores are normalized, so a weight is not an absolute multiplier on the score. Instead, weights indicate how much terms from a given query sub-expression are weighted in comparison to other sub-expressions in the same expression. A weight of 2.0 doubles the contribution to the score for terms that match that query. Similarly, a weight of 0.5 halves the contribution to the score for terms that match that query. In some cases, the score reaches a maximum, so a weight of 2.0 and a weight of 20,000 can yield the same contribution to the score.
Adding weights is particularly useful if you have several components in a query expression, and you want matches for some parts of the expression to be weighted more heavily than other parts. For an example of this, see Increase the Score for some Terms, Decrease for Others.
Proximity Boosting With the distance-weight Option
If you have the word positions indexing option enabled in your database, you can use the distance-weight option to the leaf-level cts:query constructors, and then all of the terms passed into that cts:query constructors will consider the proximity of the terms to each other for the purposes of scoring. This proximity boosting will make documents with matches close together have higher scores. Because search results are sorted by score, it will have the effect of making documents having the search terms close together have higher relevance ranking. This section provides some examples that use the distance-weight option along with explanations of the examples, and includes the following parts:
- Example of Simple Proximity Boosting
- Using Proximity Boosting With cts:and-query Semantics
- Using cts:near-query to Achieve Proximity Boosting
Example of Simple Proximity Boosting
The distance weight is only applied to the matches for cts:query constructors in which the distance-weight occurs. For example, consider the following cts:query constructor:
cts:word-query(("cat", "dog")), "distance-weight=3")
If one document has an instance of "cat" very near "dog", and another document has the same number of "cat" and "dog" terms, but they are not very near, then the one with the "cat" near "dog" will have a higher score.
For example, consider the following:
xquery version "1.0-ml"; (: make sure word positions are enabled in the database :) (: create 3 documents, then run two searches, one with distance-weight and one without, printing out the scores :) xdmp:document-insert("/2.xml", <p>The cat is pretty near a dog.</p>) ; xdmp:document-insert("/1.xml", <p>The cat dog is very near.</p>) ; xdmp:document-insert("/3.xml", <p>The cat is not very near the very large dog.</p>) ; for $x in (cts:search(fn:doc(), cts:word-query(("cat", "dog") , "distance-weight=3" ) ), cts:search(fn:doc(), cts:word-query(("cat", "dog") ) ) ) return element hit{attribute uri {xdmp:node-uri($x)}, attribute score {cts:score($x)}, attribute text{fn:string($x/p)}}
This returns the following results:
<hit uri="/1.xml" score="146" text="The cat dog is very near."/> <hit uri="/2.xml" score="140" text="The cat is pretty near a dog."/> <hit uri="/3.xml" score="135" text="The cat is not very near the very large dog."/> <hit uri="/3.xml" score="72" text="The cat is not very near the very large dog."/> <hit uri="/2.xml" score="72" text="The cat is pretty near a dog."/> <hit uri="/1.xml" score="72" text="The cat dog is very near."/>
Notice that the first three hits use the distance-weight, and the ones with the terms closer together have higher scores, and thus rank higher in the search. The last three hits have the same score because they all have the same number of each term in the cts:query and there is no proximity taken into account in the scores.
Using Proximity Boosting With cts:and-query Semantics
Because the distance-weight option applies to the terms in individual cts:query constructors, the terms are combined as an or-query (that is, any term match is a match for the query). Therefore, the example above would also return results for documents that contain "cat" and not "dog" and vice versa. If you want to have and-query semantics (that is, all terms must match for the query to match) and also have proximity boosting, you will have to construct a cts:query that does an and of all of the terms in addition to the cts:query with the distance-weight option.
xquery version "1.0-ml"; cts:search(fn:doc(), cts:and-query(( cts:word-query("cat"), cts:word-query("dog"), cts:word-query(("cat", "dog") , "distance-weight=3" ) )) )
The difference between this query and the previous one is that the previous one would return a document that contained "cat" but not "dog" (or vice versa), and this one will only return documents containing both "cat" and "dog".
If you have a large corpus of documents and you expect to have many matches for your searches, then you might find you do not need to use the cts:and-query approach. The reason a large corpus has an effect is because document frequency is taken into account in the relevance calculation, as described in Understanding How Scores and Relevance are Calculated. You might find that the most relevant documents still float to the top of your search even without the cts:and-query. What you do will depend on your application requirements, your preferences, and your data.
Using cts:near-query to Achieve Proximity Boosting
Another technique that makes results with closer proximity have higher scores is to use cts:near-query. Searches that use the cts:near-query constructor will take proximity into account when calculating scores, as long as the word positions index option is enabled in the database. Additionally, you can use the distance-weight parameter to further boost the effect of proximity on scoring.
Because cts:near-query takes a distance argument, you have to think about how near you want results to be in order for them to match. With the distance parameter to cts:near-query, there is a tradeoff between the size of the distance and performance. The higher the number for the distance, the more work MarkLogic Server does to resolve the query. For many queries, this amount of work might be very small, but for some complex queries it can be noticeable.
To construct a query that uses cts:near-query for proximity boosting, pass the cts:query for your search as the first parameter to a cts:near-query, and optionally add a distance-weight parameter to further boost the proximity. The cts:near-query matches will always take distance into account, but setting a distance-weight will further boost the proximity weight. For example, consider how the following query, which uses the same data as the above examples, produces similar results:
xquery version "1.0-ml"; cts:search(fn:doc(), cts:near-query( cts:and-query(( cts:word-query("cat"), cts:word-query("dog") )), 1000, (), 3) )
This query uses a distance of 1,000, therefore documents that have "cat" and "dog" that are more than 1,000 words apart are not included in its result. The size you use is dependent on your data and the performance characteristics of your searches. If you were more concerned about missing document where the matches are more than 1,000 words away, then you should raise that number; if you are seeing performance issues and want faster performance, and you are OK with missing results that are above the distance threshold (which are probably not relevant anyway), then you should make the number smaller. For databases with a large amount of documents, keep in mind that not returning the documents with words that are far apart from each other will probably result in very similar search results, especially for the most relevant hits (because the results with the matches far apart have low relevance scores compared to the ones that have matches close together).
Boosting Relevance Score With a Secondary Query
You can use cts:boost-query to modify the relevance score of search results that match a secondary (or boosting) query. The following example returns results from all documents containing the term "dog", and assigns a higher score to results that also contain the term "cat". The relevance score of matches for the first query are boosted by matches for the second query.
cts:search(fn:doc(), cts:boost-query( cts:word-query("dog"), cts:word-query("cat")) )
As discussed in Understanding How Scores and Relevance are Calculated, many factors affect relevance score, so the exact quantitative effect of a boosting query on relevance score varies. However, the effect is always proportional to the weighting of the boosting query.
For example, suppose the database includes two documents, /example/dogs.xml and /example/llamas.xml that have the following contents:
/example/dogs.xml: <data>This is my dog. I do not have a cat.</data> /example/llamas.xml: <data>This is my llama. He likes to spit at dogs.</data>
Then an unboosted search for the word "dog" returns the following matches:
cts:search(fn:doc(), cts:word-query("dog"))
<data>This is my dog. I do not have a cat.</data>
<data>This is my llama. He likes to spit at dogs.</data>Assume these matches have the same relevance score. If you repeat the search as a boost query with default weight, the first match has a score that is roughly double that of the 2nd match. (The actual score values do not matter, only their relative values.)
for $n in (cts:search(fn:doc(),
cts:boost-query(
cts:word-query("dog"),
cts:word-query("cat"))))
return fn:concat(fn:document-uri($n), " : ", cts:score($n))
==>
/example/dogs.xml : 22528
/example/llamas.xml : 11264If you increase the weight on the boosting query to 10.0, the relevance score of the document containing both terms becomes roughly 10x that of the document that only contains "dog".
for $n in (cts:search(fn:doc(),
cts:boost-query(
cts:word-query("dog"),
cts:word-query("cat", (), 10.0))))
return cts:score($n)
==>
/example/dogs.xml : 22528
/example/llamas.xml : 2048If the primary (or matching) query returns no results, the boosting query is not evaluated. A boosting query is ignored in an XPath expression or any other context in which the score is zero or randomized.
The BOOST string query operator allows equivalent boosting in string search; for details, see Query Components and Operators. The boost-query structured query component also exposes the same functionality as cts:boost-query; for details, see boost-query.
Including a Range or Geospatial Query in Scoring
By default, range queries do not influence relevance score. However, you can enable range and geospatial queries score contribution using the score-function and slope-factor options. This section covers the following topics:
- How a Range Query Contributes to Score
- Use Cases for Range Query Score Contributions
- Enabling Range Query Score Contribution
- Understanding Slope Factor
- Performance Considerations
- Range Query Scoring Examples
How a Range Query Contributes to Score
By default, a range query makes no contribution to score. If you enable scoring for a given range query, it has the same impact as a word query. The contribution from a range query is just one of many factors influencing the overall score, especially in a complex query. As with any query, you can use weights to change the influence a range query has on score; for details, see Using Weights to Influence Scores.
The difference between a matching value and the reference value does not contribute directly to the score. A function is applied to the delta, with suitable scaling based on datatype, such that the resulting range is comparable to the term frequency (TF) contribution from a word query. You control the scaling using the slope factor of the function; for details, see Understanding Slope Factor.
The type of function (linear or reciprocal) determines whether values closest to or furthest from the reference value contribute more to the score. The reference value is the constraining value in the query. For example, if a range query expresses a constraint such as > 5, then the reference value is 5. You cannot choose the function, but you can choose the type of function.
If a document contains multiple matching values, the highest contribution is used in the overall score computation.
Use Cases for Range Query Score Contributions
Range query score contributions are useful in cases such as the following:
- Boost the score of newer documents over similar older documents, where newness is a function of dateTime or another numeric element value. For example, boost the score of recently published documents.
- Boost the score based on how close some element value is to a reference value. For example, boost scores for documents containing prices closest to an ideal of $20.
- Boost the score based on how far away some element value is from a reference value. For example, boost scores for items with a price furthest below a maximum of $20.
- Boost the score based on geospatial distance. For example, find all hotels within 5 miles, boosting the scores for those closest to my current location.
For examples of how to realize these use cases, see Range Query Scoring Examples.
Enabling Range Query Score Contribution
Add the score-function option to a range or geospatial query constructor to enable score contributions. You can also use the slope-factor option to scale the contribution; for details, see Understanding Slope Factor.
For example, the following search boosts the score more for documents with high ratings (furthest from the reference value 0). Setting the slope factor to 10 decreases the range of values that make a distinct contribution and increases the difference between the amount of contribution.
(: Scoring for positive ratings in range 1 to 100 :) cts:search(doc(), cts:element-range-query(xs:QName("ratings"), ">", 0, ("score-function=linear","slope-factor=10")))
For examples of constructing a similar query with other MarkLogic Server APIs, see Range Query Scoring Examples.
You can set the value of score-function to one of the following function types:
You can specify a score function and slope factor with the following XQuery query constructors, or the equivalent structured or QBE range query constructs.
Understanding Slope Factor
In addition to specifying a score function for a range query, you can use the slope-factor option to specify a multiplier on the slope of the scoring function applied to a range query. The slope factor affects how the range of differences between a matching value and the reference value affect the score contribution. You should experiment with your application to determine the best slope factor for a given range query. This section provides details to guide your experimentation.
The delta for a given range query match is the difference between the matching value and the reference value in a range query:
delta = reference_value - matching_value
For example, if a range query expresses greater than 5 and the matching value is 3, then the delta is 2. This delta is the basis of the score contribution for a given match, though it is not the actual score contribution.
Each possible delta value does not make a different score contribution because contribution is bucketed. The range of delta values is bounded by a min and max delta value, beyond which all deltas make the same contribution. The granularity represents the size of each bucket within that range. All deltas that fall in the same bucket make the same score contribution, so granularity determines the range of deltas that make a distinct score contribution.
The number of buckets does not change as you vary the slope factor, so changing the slope factor affects the min, max, and granularity of the score function.
The figure below shows the relationship between slope, minimum delta, maximum delta, and granularity for a linear score function.
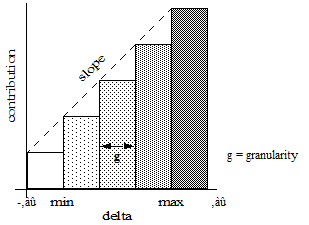
A slope factor greater than 1 results in finer granularity, but a more narrow range of delta values. A slope factor less than 1 gives a coarser granularity, but a greater range of delta values. Doubling the slope factor with a linear function gives you half the range and half the granularity.
The minimum delta, maximum delta, and granularity for a given slope factor depend upon the type of the range index. The table below shows minimum delta, maximum delta, and granularity for each range index type with the default slope factor (1.0). The granularity is not linear for a reciprocal score function.
For example, the table contains the following information about range queries over dateTime with the default slope factor:
Min delta: 1 minute Max delta: 30 days Granularity: ~2.6 hours
From this, you can deduce the following for a slope factor of 1.0:
- Any delta smaller than 1 minute makes the same contribution as 1 minute
- Any delta greater than 30 days makes the same contribution as 30 days.
- Deltas within ~2.6 hours of each other can make the same contribution. For example, a delta of 5 minutes and a delta of 2 hours make the same contribution because they both fall into the bucket for 1 min. < delta ...⧠2.6 hours.
In a dateTime range query where the deltas are on the order of hours, the default slope factor provides a good spread of contributions. However, if you need to distinguish between deltas of a few minutes or seconds, you would increase the slope factor to provide a finer granularity. When you do this, the minimum and maximum delta values get closer together, so the overall range of distinguishable delta values becomes smaller.
Another way to look at slope factor is based on the target minimum or maximum delta. For example, if the default maximum delta for your datatype is 1024 and the range of interesting delta values for your range query is only 1 to 100, you probably want to set slope-factor to 10, which lowers the maximum delta to 100 (1024 div 10).
Performance Considerations
The performance impact of enabling range query score contributions depends on the nature of your query. The cost is highest for queries that return many matches and queries on strings.
The number of matches affects cost because the scoring calculation is performed for each match. The value type affects the cost because the score calculation is significantly more complex for string values.
Range query score contribution calculations are skipped (and therefore have no negative performance impact) if any of the following conditions apply:
Range Query Scoring Examples
This section contains examples that illustrate the use cases outlined in Use Cases for Range Query Score Contributions, plus examples of how to use the feature with additional APIs, such as structured query and QBE.
The following examples are included:
- Example: Most Recently Published
- Example: Closest to a Target Price
- Example: Best Price Below a Maximum
- Example: Closest to a Location
- Example: Use in a Structured Query
- Example: Use in Query By Example
Example: Most Recently Published
Boost the score of newer documents over similar older documents, where newness is a function of dateTime or another numeric element value. The following example boosts the score of recently published documents, where the publication date is stored in a pubdate element:
cts:element-range-query( xs:QName("pubdate"), "<=", current-dateTime(), "score-function=reciprocal")
The example uses a reciprocal score function so that pubdate values closest to now contribute the most to the score. That is, the smallest deltas make the biggest contribution.
Example: Closest to a Target Price
Boost the score based on how close some element value is to a reference value. The following example boost scores for documents containing prices closest to an ideal of $20, assuming the price is an attribute of the item element:
cts:element-attribute-range-query( xs:QName("item"), xs:QName("price"), ">=", 20.0, "score-function=reciprocal")
The example uses a reciprocal score function so that the smallest deltas between actual and ideal price ($20) make the highest contribution.
Example: Best Price Below a Maximum
Boost the score based on how far away some element value is from a reference value. For example, boost scores for items with a price furthest below a maximum of $20:
cts:element-attribute-range-query( xs:QName("item"), xs:QName("price"), "<=", xs:decimal(20.0), ("score-function=linear","slope-factor=51.2"))
The example uses a linear function so that the largest deltas between the actual price and the maxiumum price ($20) make the highest contribution.
The slope factor is increased to bring the range of interesting delta values down. As shown in Understanding Slope Factor, the default maximum delta for xs:decimal is 1024.0. However, in this example, the interesting deltas are all in the range of 0 to 20.0. To bring the upper bound down to ~20.0, we calculate the slope factor as follows:
slope-factor = 1024.0 / 20.0 = 51.2
Increasing the slope factor also reduces the granularity, so smaller price differences make different score contributions. With the default slope factor, the granularity is ~3.98, which is very coarse for a delta range of 0-20.0.
Example: Closest to a Location
Boost the score based on geospatial distance. For example, find all hotels within 10 miles, boosting the scores for those closest to my current location:
cts:and-query(("hotel", cts:element-geospatial-query( xs:QName("pt"), cts:circle(10, $current-location), ("score-function=reciprocal", "slope-factor=10.0))))
The example uses a reciprocal score function so that points closest to the reference location (the smallest deltas) make the greatest score contribution.
The slope factor is increased because the range of interesting delta values is only 0 to 10 (within 10 miles). As shown in Understanding Slope Factor, the default maximum delta for a point is 100.0 miles. To bring the maximum delta down to 10.0, slope factor is computed as follows:
slope-factor = 100.0 / 10.0 = 10.0
Example: Use in a Structured Query
The following example is a structured query containing a range query for ratings greater than zero, boosting the score more as the rating increases. Documents with a higher rating receive a higher range query score contribution.
For details, see Searching Using Structured Queries and the following interfaces:
| Interface | Interface | More Information |
|---|---|---|
| Search API | search:resolve |
XQuery and XSLT Reference Guide |
| REST API | GET/POST methods of the /search service |
Querying Documents and Metadata in REST Application Developer's Guide |
| Java API | RawStructuredQueryDefinition or StructuredQueryBuilder in com.marklogic.client.query |
Search Documents Using Structured Query Definition in Java Application Developer's Guide |
Example: Use in Query By Example
The following example is a QBE that contains a range query for ratings greater than zero, boosting the score more as the rating increases. Documents with a higher rating receive a higher range query score contribution.
This query is suitable for use with the REST API /qbe service or the Java API RawQueryByExampleDefinition interface.
For details, see Searching Using Query By Example and the following interfaces:
| Interface | Interface | More Information |
|---|---|---|
| Search API | search:resolve |
XQuery and XSLT Reference Guide |
| REST API | GET/POST methods of the /qbe service |
Using Query By Example to Prototype a Query in REST Application Developer's Guide |
| Java API | RawQueryByExampleDefinition in com.marklogic.client.query |
Prototype a Query Using Query By Example in Java Application Developer's Guide |
Interaction of Score and Quality
Each document contains a quality value, and is set either at load time or with xdmp:document-set-quality. You can use the optional $QualityWeight parameter to cts:search to force document quality to have an impact on scores. The scores are then determined by the following formula:
Score = Score + (QualityWeight * Quality)
The default of QualityWeight is 1.0 and the default quality on a document is 0, so by default, documents without any quality set have no quality impact on score. Documents that do have quality set, however, will have impact on the scores by default (because the default QualityWeight is 1, effectively boosting the score by the document quality).
If you want quality to have a smaller impact on the score, set the QualityWeight between 0 and 1.0. If you want the quality to have no impact on the score, set the QualityWeight to 0. If you want the quality to have a larger impact on raising the score, set the QualityWeight to a number greater than 1.0. If you want the quality to have a negative effect on scores, set the QualityWeight to a negative number or set document quality to a negative number.
If you set document quality to a negative number and if you set QualityWeight to a negative number, it will boost the score with a positive number.
Using cts:score, cts:confidence, and cts:fitness
You can get the score for a result node by calling cts:score on that node. The score is a number, where higher numbers indicate higher relevance for that particular result set.
Similarly, you can get the confidence by calling cts:confidence on a result node. The confidence is a number (of type xs:float) between 0.0 and 1.0. The confidence number does not include any quality settings that might be on the document. Confidence scores are calculated by first bounding the scores between 0 and 1.0, and then taking the square root of the bounded number.
As an alternate to cts:confidence, you can get the fitness by calling cts:fitness on a result node. The fitness is a number (of type xs:float) between 0.0 and 1.0. The fitness number does not include any quality settings that might be on the document, and it does not use document frequency in the calculation. Therefore, cts:fitness returns a number indicating how well the returned node satisfies the query issued, which is subtly different from relevance, because it does not take into account other documents in the database.
Relevance Order in cts:search Versus Document Order in XPath
When understanding the order an expression returns in, there are two main rules to consider:
cts:searchexpressions always return in relevance order (the most relevant to the least relevant).- XPath expressions always return in document order.
A subtlety to note about these rules is that if a cts:search expression is followed by some XPath steps, it turns the expression into an XPath expression and the results are therefore returned in document order. For example, consider the following query:
cts:search(fn:doc(), "my search phrase")
This returns a relevance-ordered sequence of document nodes that contain the specified phrase. You can get the scores of each node by using cts:score. Things will change if you then add an XPath step to the expression as follows:
cts:search(fn:doc(), "my search phrase")//TITLE
This will now return a document-ordered sequence of TITLE elements. Also, in order to compute the answer to this query, MarkLogic Server must first perform the search, and then reorder the search in document order to resolve the XPath expression. If you need to perform this type of query, it is usually more efficient (and often much more efficient) to use cts:contains in an XPath predicate as follows:
fn:doc()[cts:contains(., "my search phrase")]//TITLE
In most cases, this form of the query (all XPath expression) will be much more efficient than the previous form (with the XPath step after the cts:search expression). There might be some cases, however, where it might be less efficient, especially if the query is highly selective (does not match many fragments).
When you write queries as XPath expressions, MarkLogic Server does not compute scores, so if you need scores, you will need to use a cts:search expression. Also, if you need a query like the above examples but need the results in relevance order, then you can put the search in a FLWOR expression as follows:
for $x in cts:search(fn:doc(), "my search phrase") return $x//TITLE
This is more efficient than the cts:search with an XPath step following it, and returns relevance-ranked and scored results.
Exploring Relevance Score Computation
You can use the relevance-trace search option to explore how the relevance scores are computed for a query. For example, you can use this feature to explore the impact of varying query weight and document quality weight.
Collecting score computation information during a search is costly, so you should only use the relevance-trace option when you intend to generate a score computation report from the collected trace.
When you use the relevance-trace option on a search, MarkLogic Server collects detailed information about how the relevance score is computed. You can access the information in one of the following ways:
- If you search using cts:search, call cts:relevance-info on your search results to generate an XML report.
- If you search using the Search API (search:search or search:resolve), REST API, or Java API, an XML report is automatically returned in the relevance-info section of each search result. (The REST and Java APIs can also return a JSON report.)
The following example generates a score computation report from the results of cts:search.
for $x in cts:search(fn:doc(), "example", "relevance-trace") return cts:relevance-info($x)
The resulting score computation report looks similar to the following:
<qry:relevance-info xmlns:qry="http://marklogic.com/cts/query"> <qry:score formula="(256*scoreSum/weightSum)+(256*qualityWeight*documentQuality)" computation="(256*208/1)+(256*1*0)">53248</qry:score> <qry:confidence formula="sqrt(score/(256*8*maxlogtf*maxidf))" computation="sqrt(53248/(256*8*18*log(848)))">0.462837</qry:confidence> <qry:fitness formula="sqrt(score/(256*8*maxlogtf*avgidf))" computation="sqrt(53248/(256*8*18*(3.13196/1)))">0.679113</qry:fitness> <qry:uri>/example.xml</qry:uri> <qry:path>fn:doc("/example.xml")</qry:path> <qry:term weight="3.25"> <qry:score formula="8*weight*logtf" computation="26*8">208</qry:score> <qry:key>16979648098685758574</qry:key> <qry:annotation>word("example")</qry:annotation> </qry:term> </qry:relevance-info>
Each qry:score element contains a @formula describing the computation, and a @computation showing the values plugged into the formula. The data in the score element is the result of the computation. For example:
<qry:score formula="(256*scoreSum/weightSum)+(256*qualityWeight*documentQuality)" computation="(256*154/2)+(256*1*0)"> 19712 </qry:score>
The following example generates a score computation report using the XQuery Search API:
xquery version "1.0-ml"; import module namespace search = "http://marklogic.com/appservices/search" at "/MarkLogic/appservices/search/search.xqy"; search:search("example", <search:options xmlns="http://marklogic.com/appservices/search"> <search-option>relevance-trace</search-option> </search:options> )
The query generates results similar to the following:
<search:response snippet-format="snippet" total="1" start="1" ...>
<search:result index="1" uri="/example.xml"
path="fn:doc("/example.xml")" score="14336" confidence="0.749031" fitness="0.749031">
<search:snippet>...</search:snippet>
<qry:relevance-info xmlns:qry="http://marklogic.com/cts/query">
<qry:score
formula="(256*scoreSum/weightSum)+(256*qualityWeight*documentQuality)"
computation="(256*56/1)+(256*1*0)">14336</qry:score>
<qry:confidence formula="sqrt(score/(256*8*maxlogtf*maxidf))"
computation="sqrt(14336/(256*8*18*log(2)))">0.749031</qry:confidence>
<qry:fitness formula="sqrt(score/(256*8*maxlogtf*avgidf))"
computation="sqrt(14336/(256*8*18*(0.693147/1)))">
0.749031
</qry:fitness>
<qry:uri>/example.xml</qry:uri>
<qry:path>fn:doc("/example.xml")</qry:path>
<qry:term weight="0.875">
<qry:score formula="8*weight*logtf" computation="7*8">56</qry:score>
<qry:key>16979648098685758574</qry:key>
<qry:annotation>word("example")</qry:annotation>
</qry:term>
</qry:relevance-info>
</search:result>
<search:qtext>example</search:qtext>
...
</search:response>The REST and Java APIs use the same query options as the above Search API example, and return a report in the same way, inside each search:result.
Sample cts:search Expressions
This section lists several cts:search expressions that include weight and/or quality parameters. It includes the following examples:
- Magnify the Score Boost for Documents With Quality
- Increase the Score for some Terms, Decrease for Others
Magnify the Score Boost for Documents With Quality
The following search will make any documents that have a quality set (set either at load time or with xdmp:document-set-quality) give much higher scores than documents with no quality set.
cts:search(fn:doc(), cts:word-query("my phrase"), (), 3.0)
For any documents that have a quality set to a negative number less than -1.0, this search will have the effect of lowering the score drastically for matches on those documents.
Increase the Score for some Terms, Decrease for Others
The following search will boost the scores for documents that satisfy one query while decreasing the scores for documents that satisfy another query.
cts:search(fn:doc(), cts:and-query(( cts:word-query("alfa", (), 2.0), cts:word-query("lada", (), 0.5) )) )
This search will boost the scores for documents that contain the word alfa while lowering the scores for document that contain the word lada. For documents that contain both terms, the component of the score from the word alfa is boosted while the component of the score from the word lada is lowered.