
MarkLogic Server 11.0 Product DocumentationNode.js Application Developer's Guide — Chapter 11
Data Movement in the Node.js API
Node.js APIs can be used for data movement either with the out-of-the-box endpoints of the REST API or with a Data Service endpoint for bulk input and/or output.
- Concurrency and Large Data Sets in Node.js
- Node-client-api - 2.8.0
- Node-client-api - 2.9.0
- Node-client-api - 3.0.0
Concurrency and Large Data Sets in Node.js
Node.js provides concurrency through multiple waits for IO responses, instead of multiple threads. This strategy avoids the challenges and risks of multi-threaded programming for middle-tier clients that are IO rather than compute intensive.
In the Node.js API, that general architectural principle of Node.js means that better throughput for large data sets requires multiple concurrent requests to each e-node (instead of serial requests to one e-node).
In other words, while the Node.js client is submitting a request or processing a response, many other pending requests are waiting for the server to respond. Because the round trip over the network is typically much more expensive (especially in the cloud), the client can typically submit many requests, and/or process many responses, during the time required for a single round trip to the server.
This section summarizes the high level concepts for data movement using Node.js.
Optimal Concurrency
The optimal level of concurrency would provide full utilization of both the client and server.
From the client perspective, a new response becomes available to process at the moment that submitting a new request finishes. In essence, neither the single Node.js thread nor the request submitting or response processing routines ever wait. From the server perspective, thread and memory consumption is at the sweet spot, with allowance for other requests to the server. Clients should avoid exceeding the optimum concurrency level for either client or server.
Detection of Server Factors
To determine the appropriate level of concurrency, the client must become aware of server capacity, as reflected by the number of hosts for the database, the number of threads available on those hosts, and (for query management) the number of forests. The Node.js API objects for data movement calls the internal endpoints to inspect server state during initialization.
IO With Node.js Streams
Node.js provides streams as the standard representation for large data sets. Conforming to this standard, the Node.js API data movement functions are factories that return:
- An object of type
stream.Writableto the application for sending request input to the server. - An object of type
stream.Readableto the application for receiving response output from the server.
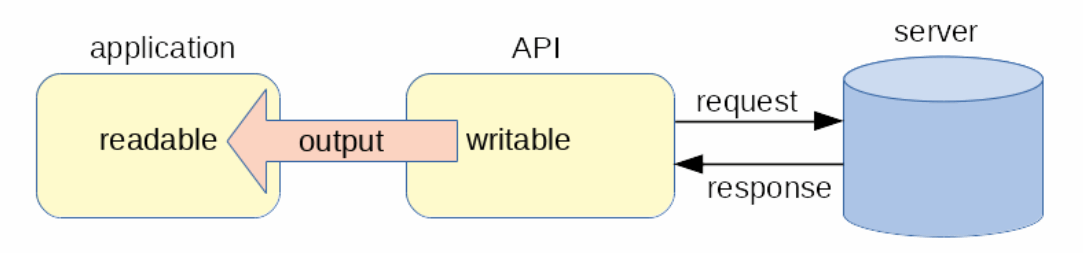
Typically, the Node.js API reads the input stream repeatedly, accumulating a batch of data in a buffer, and then making a batch request when the buffer is full or the input stream ends.
Typically, the Node.js API writes each item in a response batch separately to the output stream, and ends the output stream when the last response has been processed.
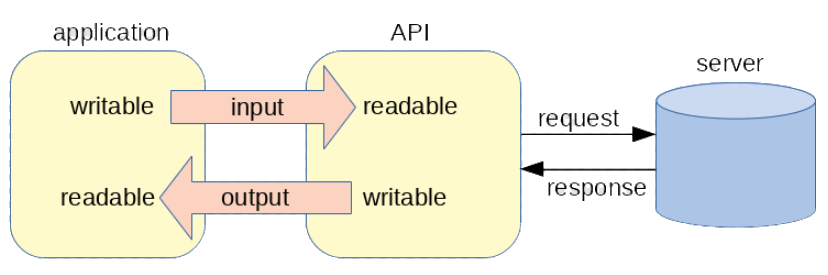
Where the data movement requires both input and output, the factory function returns: a duplex stream to the application, for sending request input to the server, and receiving response output from the server. By doing this, the client implementation in the Node.js API has a readable stream for receiving the request input from the application and a writable stream for sending the response output to the application.
Data Movement Functions
When using multiple data movement functions in a pipeline to handle special cases (instead of the provided conveniences), the application has the responsibility for configuring each function to share the available client and server concurrency.
Data movement functions take options such as - the batch size, the number of concurrent requests per forest or host, success and/or error callbacks for the batch. Each data movement function maintains state for its operations (similar to the use of the Operation object for single-request calls).
When processing data in memory, clients need to work with request or response data as JavaScript in-memory objects. Alternatively when, dispatching request or response data from other sources or sinks (such as other databases), clients can achieve better throughput by working with request or response data as JavaScript strings or buffers.
In particular, most of the existing request functions return a ResultProvider, to let the application choose whether to get the response data as a Node.js Promise or as a Node.js Stream.
Node-client-api - 2.8.0
These features are introduced with the 2.8.0 release of the Node client APIs.
Ingesting Documents using - writeAll API
The Node.js API documents object adds a writeAll function equivalent to the DMSDK WriteBatcher with the following signature:
writeAll (options)
| Parameter | Data Type | Purpose |
|---|---|---|
| options | JavaScript literal object | Configures the write operation |
A stream. Writable in object mode that receives document descriptor input from the application for writing to the database. The properties of the options object:
An example for using the writeAll API has been added to the GitHub examples folder on node-client-api - https://github.com/marklogic/node-client-api/blob/develop/examples/writeAll-documents.js
JavaScript docs - https://docs.marklogic.com/jsdoc/documents.html#writeAll
Node-client-api - 2.9.0
These APIs are introduced with the 2.9.0 release of the Node client APIs.
Collecting Document uris - queryAll API
The Node.js API documents object adds a queryAll() function, equivalent to the DMSDK QueryBatcher, with the following signature:
| Parameter | Data Type | Purpose |
|---|---|---|
| query | ctsQuery object | a query built by the ctsQuery Builder |
| options | JavaScript literal object | configures the query operation |
The return value:
a stream.Readable that sends document URI output read from the database to the application in string mode or (for arrays of strings) object mode.
The properties of the options object:
An example for using the queryAll API has been added to the Github examples folder for node-client-api - https://github.com/marklogic/node-client-api/blob/develop/examples/queryAll-documents.js
MarkLogic Node.js Client API docs - https://docs.marklogic.com/jsdoc/documents.html
Exporting Documents - readAll API
The Node.js API documents object adds a readAll() function equivalent to the DMSDK ExportListener with the following signature:
| Parameter | Data Type | Purpose |
|---|---|---|
| options | JavaScript literal object | configures the read operation |
The return value:
a stream.Duplex that receives document URI input from the application in string mode or (for arrays of strings) object mode and sends document descriptors with content and/or the document URI as output to the application in object mode.
The properties of the options object:
| Properties | Data Type | Purpose |
|---|---|---|
| onBatchError | function(progress, uris, error) | |
| onCompletion | function(summary) | |
| inputKind | 'string'|'array' | Indicates whether the input stream should accept: |
| batchSize | int | The number of documents in each request where the inputKind is 'string' Defaults to the number recommended by Performance Engineering (possibly 250). |
| concurrentRequests | JavaScript object literal | Controls the maximum number of concurrent requests that can be pending at the same time. Specified as a multiple of either forests or hosts with the following properties: Defaults to the setting recommended by Performance Engineering (possibly 8 per forest). |
| categories | categoriesSpecification | Specifies what data to retrieve from the server and write to the output stream. The option has the same enumeration as the categories parameter of |
| transform | transformSpecification | The same as the transform parameter of documents.read() |
| consistentSnapshot | boolean|Timestamp | Controls whether to get an immutable view of the result set:
The existing |
| onInitialTimestamp | function(timestamp) | Receives the timestamp from the first request. If the consistentSnapshot option is not set to true, throws an error. |
| outputStreamType | 'chunked'| 'object' | Same as the parameter of the existing ResultProvider.stream() function. |
An example for using the readAll API has been added to the Github examples folder for node-client-api: https://github.com/marklogic/node-client-api/blob/develop/examples/readAll-documents.js
MarkLogic Node.js Client API docs: https://docs.marklogic.com/jsdoc/documents.html
queryToReadAll
queryToReadAll - a convenience function that combines the query and read operations
The Node.js API documents object adds a queryToReadAll() convenience function that combines the query and read operations.
This function has the following signature:
queryToReadAll(query, options)
The parameters: the same as the queryAll() and readAll() functions.
The return value:
a stream.Readable in object mode that returns document descriptors with the content and/or document uri as output to the application in object mode.
The properties of the options object are the same as those of the queryAll() function except:
An example for using the readAll API has been added to the examples folder on node-client-api: https://github.com/marklogic/node-client-api/blob/master/examples/queryToReadAll-documents.js
JS docs: https://docs.marklogic.com/jsdoc/documents.html#queryToReadAll
Node-client-api - 3.0.0
These APIs are introduced with the 3.0.0 release of the Node client APIs:
- Reprocessing Documents - transformAll API
- Deleting Documents - removeAllUris API
- Exporting Rows - queryAll API
- Signature Changes
Reprocessing Documents - transformAll API
The Node.js API documents object adds a transformAll() function equivalent to the DMSDK ApplyTransformListener with the following signature:
transformAll(stream,options)
| Parameter | Data Type | Purpose |
|---|---|---|
| *stream | Stream | Provides the input to the transformAll API. |
| options | JavaScript literal object | Configures the transform operation. |
The return value: a stream.Writable that receives document URI input from the application in string mode or (for arrays of strings) object mode.
The properties of the options object:
Example and JS Docs for transformAll API
An example for using the transformAll API has been added to the examples folder on node-client-api: https://github.com/marklogic/node-client-api/blob/develop/examples/transformAll-documents.js
JS docs: https://docs.marklogic.com/jsdoc/documents.html
queryToTransformAll
The Node.js API documents object adds a queryToTransformAll() convenience function that combines the query and transform operations.
This function has the following signature:
queryToTransformAll(query, options)
The parameters: the same as the queryAll() and transformAll() functions.
The properties of the options object are the same as those of the queryAll() and transformAll() functions except:
Example and JS Docs for queryToTransformAll API
An example for using the queryToTransformAll API has been added to the examples folder on node-client-api: https://github.com/marklogic/node-client-api/blob/develop/examples/queryToTransformAll-documents.js
Deleting Documents - removeAllUris API
The Node.js API documents object adds a removeAllUris() function equivalent to the DMSDK DeleteListener with the following signature:
removeAllUris(stream,options)
| Parameter | Data Type | Purpose |
|---|---|---|
| *stream | Stream | Provides the input to the removeAllUris API. |
| options | JavaScript literal object | Configures the remove operation. |
The return value: a stream.Writable that receives document URI input from the application in string mode or (for arrays of strings) object mode.
The properties of the options object:
Example and JS Docs for removeAllUris API
An example for using the transformAll API has been added to the examples folder on node-client-api: https://github.com/marklogic/node-client-api/blob/develop/examples/removeAllUris-documents.js
JS docs: https://docs.marklogic.com/jsdoc/documents.html
queryToRemoveAll
The Node.js API documents object adds a queryToRemoveAll() convenience function that combines the queryAll and removeAllUris operations. This function has the following signature:
queryToRemoveAll(query, options)
The parameters: the same as the queryAll() and removeAllUris() functions
The properties of the options object are the same as those of the queryAll() and removeAllUris() functions except:
Example and JS Docs for queryToRemoveAll API
An example for using the queryToRemoveAll API has been added to the examples folder on node-client-api: https://github.com/marklogic/node-client-api/blob/develop/examples/queryToRemoveAll-documents.js
Exporting Rows - queryAll API
The Node.js API rows object adds a queryAll() function equivalent to the DMSDK RowBatcher with the following signature:
queryAll(batchView, options)
a stream.Readable that sends rows read from the database to the application in the configured mode
The properties of the options object:
| Properties | Data Type | Purpose |
|---|---|---|
| onBatchError | function(progress, error) | Responding to any error while while reading a batch of rows. |
| onCompletion | function(summary) | |
| batchSize | int | Controls the number of rows retrieved in each request Streaming arrays of strings will likely be more performant when piping the output to another other data movement function, in part because each request will read from a single forest. Throws an error if larger than the maximum batch size (possibly 100,000) as determined by Performance Engineering |
| concurrentRequests | JavaScript object literal | Controls the maximum number of concurrent requests that can be pending at the same time. Specified as a multiple of either forests or hosts with the following properties: Defaults to the setting recommended by Performance Engineering (possibly 4 per forest). |
| consistentSnapshot | boolean|Timestamp | Controls whether to get an immutable view of the result set:
|
| onInitialTimestamp | function(timestamp) | Receives the timestamp from the first request. If the consistentSnapshot option is not set to true, throws an error |
| queryType | 'json'|'dsl' | Identifies the representation for a string batch view. Throws an error for a ModifyPlan or object batch view. Similar to the RowsOptions.queryType property of the existing rows.query() function. |
| columnTypes | 'rows'|'header' | Same as the RowsOptions.columnTypes property of the existing rows.query() function. |
| rowStructure | 'object'|'array' | Same as the RowsOptions.structure property of the existing rows.query() function. |
| rowFormat | 'json'|'xml'|'csv' | Same as the RowsOptions.format property of the existing rows.query() function. |
| outputStreamType | 'chunked'| 'object'|'sequence | Same as the streamType parameter of the existing rows.queryAsStream() function. |
An example for using the queryAll API has been added to the examples folder on node-client-api - https://github.com/marklogic/node-client-api/blob/develop/examples/queryAll-rows.js
Signature Changes
The Node.js writeAll function adds an additional parameter and the new API will be as follows:
writeAll(stream, options)
| Parameter | Data Type | Purpose |
|---|---|---|
| *stream | Stream | Provides the input to the writeAll API. |
| options | JavaScript literal object | Configures the write operation. |
The return value and options parameter remains the same.
The Node.js readAll function adds an additional parameter and the new API will be as follows:
readAll(stream, options)
| Parameter | Data Type | Purpose |
|---|---|---|
| *stream | Stream | Provides the input to the readAll API. |
| options | JavaScript literal object | Configures the read operation. |