Matches for cat:guide/java have been highlighted.


MarkLogic Server 11.0 Product DocumentationJava Application Developer's Guide — Chapter 4
Asynchronous Multi-Document Operations
The Data Movement Software Development Kit (SDK) is a package in the Java Client API intended for manipulating large numbers of documents and/or metadata through an asynchronous interface that efficiently distributes workload across a MarkLogic cluster. This framework is best suited for long running operations and/or those that manipulate large numbers of documents.
You can use the Data Movement SDK out-of-the-box to insert, extract, delete, and transform documents in MarkLogic. You can also easily extend the framework to perform other operations.
The Java Client API also includes simpler interfaces for single-document operations and synchronous multi-document operations. For details, see Alternative Interfaces.
This chapter includes the following topics:
- Terms and Definitions
- Data Movement Feature Overview
- Data Movement Concepts
- Creating and Managing a Write Job
- Creating and Managing a Query Job
- Reading Documents from MarkLogic
- Applying an In-Database Transformation
- Deleting Documents from a Database
- Applying a Read or Write Transformation
- Job Control
- Failover Handling
- Working With Listeners
- Alternative Interfaces
Terms and Definitions
You should be familiar with the following terms and definitions when working with the Data Movement SDK.
| Term | Definition |
|---|---|
| job | An operation or large amount of work to be performed using the Data Movement SDK, such as loading documents into or reading documents from MarkLogic. For details, see Basic Data Movement Job Life Cycle. |
| batch | A small unit of work for a Data Movement job. For details, see Basic Data Movement Job Life Cycle. |
| batcher | An object that encapsulates the characteristics of a job and coordinates the work. The batcher is the job controller. It splits the work requested by a job into batches, coordinates distribution of work, and notifies listeners of events. For details, see Basic Data Movement Job Life Cycle. |
| listener | A callback object that is notified whenever an interesting job event occurs. You register listeners through a batcher. For details, see Working With Listeners. |
| write job | A job whose purpose is writing documents and optional metadata to MarkLogic. Write jobs are driven by a WriteBatcher. For details, see Job Types and Creating and Managing a Write Job. |
| query job | A job whose purpose is gathering a set of URIs for documents in the database, and dispatching batches of URIs to listeners for action. The listeners determine the outcome. For example, you can use a query job to read or delete documents from MarkLogic. For details, see Job Types and Creating and Managing a Query Job. |
| job ticket | An identifier for a job that can be used to retrieve status and other information about a job. |
| job report | A job status report. For details, see Checking the Status of a Job. |
| read transformation | A content, metadata, or search response transformation that is applied on MarkLogic server when you read a document from the database. For details, see Applying a Read or Write Transformation. |
| write transformation | A content or metadata transformation that is applied on MarkLogic server when you insert a document into the database. The transformation is applied before committing the content. For details, see Applying a Read or Write Transformation. |
| in-database transformation | A content or metadata transformation that is applied on MarkLogic server to content already in the database. The content is not fetched from MarkLogic to the client or sent from the client to MarkLogic. For details, see Applying an In-Database Transformation. |
| consistent snapshot | A consistent snapshot is a conceptual snapshot of the state of the database at a specific point in time. Consistent snapshots are useful for securing an unchanging view of the database for a long-running that accesses documents in the database. For details, see Using a Consistent Snapshot. |
Data Movement Feature Overview
The Data Movement SDK is designed to efficiently operate on large amounts of data. The operations are carried out asynchronously to facilitate spreading the workload across a cluster and to enable your application to continue other processing during a long-running job.
You can use the Data Movement SDK to perform the following operations out-of-the-box. You can easily customize the framework to perform other operations.
- Write data into MarkLogic.
- Read data from MarkLogic.
- Delete data from MarkLogic.
- Apply in-database transformations without fetching data to the client.
The Data Movement SDK provides the following additional benefits.
- A programmatic interface that enables easy integration into existing ETL and data flow tool chains.
- Asynchronous operation. Your application does not block while importing, exporting, deleting, or transforming data. You can incrementally change the workload. For example, as you receive data from an ETL stream, you can add the new input to a running import job.
- Control over workload characteristics, such as thread count and batch size.
- Data format flexibility. When importing documents, you can use any input source supported by Java, such as a file or a stream. The same applies to output when exporting documents.
- Data consistency. You can ensure that a long running export, delete, or transform job operates on the database state in effect when the job started.
- High performance and efficient use of client and server resources. You can tune client and server resource consumption through configuration. The API automatically distributes the server-side workload across your MarkLogic cluster.
Since the Data Movement SDK is part of the Java Client API, your data movement application can leverage the full power of the Java Client API to support high volume operations. For example, you can do the following:
- Use the full suite of search features in the Java Client API to select documents for export, deletion, or in-database transformation. For example, select documents using a string or structured query.
- Operate on documents and document metadata.
- Apply server-side XQuery or JavaScript transformations when importing or exporting documents. You can use the same transformation code and deployment for both data movement and lighter weight document operations.
If you prefer a command line interface, consider using the mlcp command line tool. Be aware that the Data Movement SDK offers some features unavailable to mlcp, and vice versa. For details, see Alternative Interfaces.
Data Movement Concepts
This section discusses the basic concepts behind the Data Movement SDK.
- Summary of Key Classes and Interfaces
- Basic Data Movement Job Life Cycle
- Job Types
- Object Lifetime Considerations
- How Work is Distributed Across a Cluster
Summary of Key Classes and Interfaces
The following table summarizes the classes and interfaces that drive work in Data Movement SDK. This is not a complete list of available classes and interfaces. For details, see the com.marklogic.client.datamovement package in the Java Client API Documentation.
Basic Data Movement Job Life Cycle
Data Movement is based on an asynchronous job model of interaction with MarkLogic. You create a job (represented by a Batcher object), configure its characteristics, and then start the job. Your application does not block while the job runs. Rather, you interact with the job asynchronously via one or more event listeners (represented by a BatchListener).
Once you configure and start a job, the underlying API manages distribution of the workload for you, both across the resources available to your client application and across your MarkLogic cluster.
The following diagram illustrates key operations and components common to all Data Movement jobs. Details vary depending on the type of job; for details on specific job types, see Job Types.
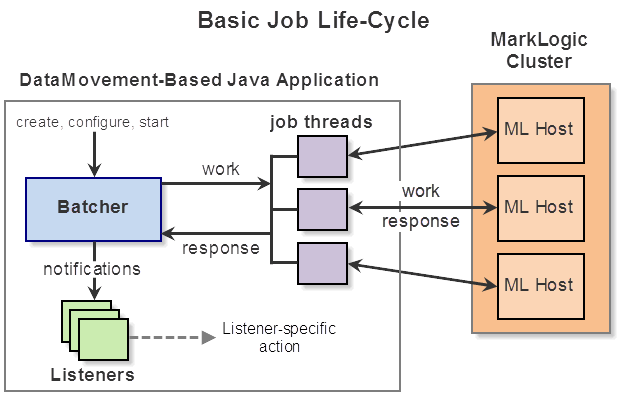
The following procedure describes the high level flow in more detail. The details vary, depending on the job type; see Job Types.
- Create a
DataMovementManagerto manage jobs. This object is intended to be long-lived, and can manage multiple jobs. TheDataMovementManageris not represented in the above diagram, but it is the agent through which you create, start, and stop jobs. - Create a batcher. The batcher acts as the job controller. The type of batcher you create determines the basic job flow (write or query); for details, see Job Types.
- Configure job characteristics such as batch size and thread count.
- Attach one or more listeners to interesting job events. The available events depend on the type of job.
- Start the job. The job runs asynchronously, so this is a non-blocking operation.
- Depending on the type of job, your application might periodically interact with the batcher to update the state of the running job. For example, periodically add documents to the work queue of a write job.
- The batcher interacts with MarkLogic on behalf of each batch of work using one of the configured job threads.
- Whenever an important job life cycle event occurs, the batcher notifies all listeners for that event. For example, a write job notifies batch success listeners whenever a batch of documents is successfully written to MarkLogic.
- Stop the job when you no longer need it. A job can run indefinitely. Graceful shutdown of a job includes waiting for in-progress batches to complete. For more details, see Job Control.
Job Types
The Data Movement SDK supports the following job types. The job type determines the detailed workflow and the kind of operation a job can perform.
Write Job
A write job sends batches of documents to MarkLogic for insertion into a database. You can insert both content and metadata.
Your code submits documents to the batcher (job controller), and the batcher submits a batch of documents to MarkLogic whenever a full batch of documents is queued by your application. The number of documents in a batch is a configuration parameter of the job.
Batches are processed in multiple client application threads and distributed across the cluster. The batcher notifies listeners of the success or failure of each batch.
The following diagram gives an overview of the key components and actions of a write job:
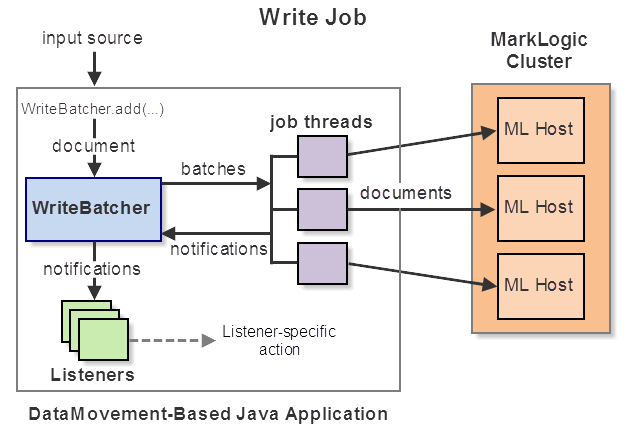
For more details, see Creating and Managing a Write Job.
Query Job
A query job creates batches of URIs and dispatches each batch to listeners. The batcher gets URIs either by identifying documents that match a query or from a list of URIs you provide as an Iterator.
When the job is driven by a query, the batches of URIs are obtained by evaluating the query on MarkLogic and fetching the URIs of subsets of the matching documents. This enables the job to handle large query result sets efficiently.
The action applied to a URI batch is dependent on the listener. For example, a listener might read the documents specified by batch from the database and then save them to the filesystem.
The following diagram gives an overview of the key components and actions of a typical query job.
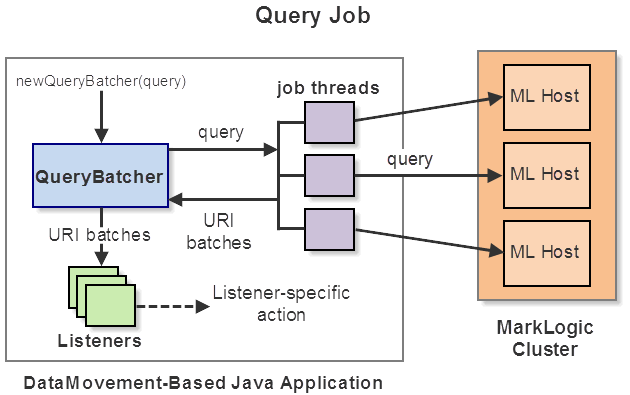
The Data Movement SDK pre-defines query job listeners that support the following actions:
- Read documents from MarkLogic (
ExportListenerandExportToWriterListener). - Delete documents from MarkLogic (
DeleteListener). - Apply an in-database transformation to documents in MarkLogic (
ApplyTransformListener). - Save the URIs of matched documents to a file or other output sink (
UrisToWriterListener).
You can also create custom listeners to accomplish these and other operations. The pre-defined listeners are meant to serve as guides for creating your own listeners. For more details, see Working With Listeners.
You can also create query jobs that operate on a pre-defined set of URIs, rather than querying MarkLogic to find URIs. In this case, the Batcher does not interact with MarkLogic to collect URIs, but your listeners can still interact with MarkLogic to act on the URIs.
For more details, see Creating and Managing a Query Job.
Object Lifetime Considerations
A DataMovementManager object is usually a long-lived object. For example, create one when your data movement application starts up, and keep it until your application exits. A DataMovementManager object is the agent through which you create, start, and stop jobs. It also manages the MarkLogic connection resources used by jobs (in the form of DatabaseClient objects).
A Batcher can be released after you stop the job. Jobs cannot be restarted, so a Batcher cannot be re-used once the job is stopped.
When you pass a Closeable handle to WriteBatcher.add or WriteBatcher.addAs, the batcher takes responsibility for closing the handle. All Closeable content and metadata handles held by the batcher will be closed as soon as possible after a batch is written.
How Work is Distributed Across a Cluster
This section describes how a Data Movement job distributes its workload across a MarkLogic cluster. You do not need to understand this to use the Data Movement SDK, but you might find it useful in understanding the impact of host failures and cluster topology changes.
When you create a DataMovementManager object using DatabaseClient.newDataMovementManager, the DataMovementManager is implicitly associated with the connection held by the creating client. This connection is used to discover which hosts in your MarkLogic cluster contain available forests for the target database.
When you create a batcher using the DataMovementManager, the batcher's default configuration includes this forest host data. The batcher distributes its work among these hosts, helping to ensure no single host becomes a chokepoint or gets overloaded.
The following diagram illustrates this discovery process and propagation of forest configuration to a batcher. Assume the job targets the database named mydb in cluster that contains three hosts (Host 1, Host 2, and Host 3). Only Host 1 and Host 2 contains forests from mydb.
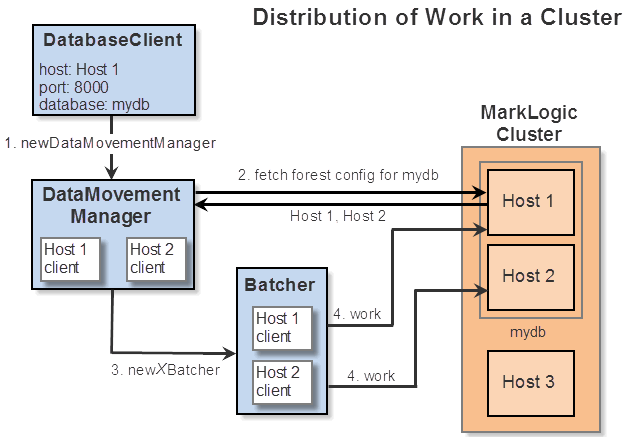
When a forest host becomes unavailable, the batcher attempts to recover by removing the failed host from its host list and redirecting work elsewhere. If the batcher runs out of viable hosts, the job stops.
If you change the forest topology of the database operated on by a job, the batcher will not be aware of this change unless you update the batcher forest configuration information. For details, see Updating Forest Configuration for a Job.
Creating and Managing a Write Job
A write job inserts documents into a database. The following topics describe creating and managing a write job. The flow of a write job is also illustrated in Job Types.
- Creating a Batcher and Configuring a Write Job
- Attaching Listeners to a Write Job
- Starting a Write Job
- Adding Documents and Metadata to a Job
- Stopping a Write Job
- Write Job Performance Considerations
- Example: Exporting Documents that Match a Query
Creating a Batcher and Configuring a Write Job
You can use a WriteBatcher object to load documents into MarkLogic. You can include both content and metadata. Use the batcher to configure runtime characteristics of the job, such as the batch size, and register listeners for batch success and failure events.
The following code snippet configures batch size and thread count. For additional configuration options see Attaching Listeners to a Write Job and the Java Client API Documentation..
// Assume "dmm" is a previously created DataMovementManager object. WriteBatcher batcher = dmm.newWriteBatcher(); batcher.withBatchSize(1000) .withThreadCount(10) /* ... additional configuration ... */ ;
The order in which you configure job characteristics and attach listeners is not significant, other than that listeners for the same event are invoked in the order in which they're attached.
For an end-to-end example, see Example: Loading Documents From the Filesystem.
Attaching Listeners to a Write Job
Whenever a WriteBatcher accumulates a batch of documents, it dispatches the batch to MarkLogic for writing. The success or failure of committing the batch to the database is reported back to the batcher, which in turn notifies appropriate listeners.
You can attach listeners to a WriteBatcher for the following events:
- Batch success: A batch success event occurs whenever all the documents in a batch are successfully committed to MarkLogic. Use
WriteBatcher.onBatchSuccessto attach a listener to this event. - Batch failure: A batch failure event occurs whenever at least one document in a batch cannot be committed to MarkLogic. Use
WriteBatcher.onBatchFailureto attach a listener to this event.
You are not required to attach a listener, but doing so gives your application access to information that may not be included in the default logging and error handling, as well as more control over your job. Tracking success and failure details can also assist in error recovery.
Listeners for the same event are invoked in the order in which they are attached to the batcher.
The following code snippet illustrates attaching a success and a failure listener, both in the form of a lambda function.
// Assume "dmm" is a previously created DataMovementManager object. WriteBatcher batcher = dmm.newWriteBatcher(); batcher.onBatchSuccess(batch-> {/* take some action */}) .onBatchFailure((batch,throwable) -> {/* take some action */}) // ...additional configuration... dmm.startJob(batcher);
To learn more about listeners, see Working With Listeners.
For an end-to-end example, see Example: Loading Documents From the Filesystem.
Starting a Write Job
Start a job using DataMovementManager.startJob. For example:
// Assume "dmm" is a previously created DataMovementManager object. WriteBatcher batcher = dmm.newWriteBatcher(); // ... configure the job and attach listeners ... JobTicket ticket = dmm.startJob(batcher);
You receive a JobTicket that can be used to check status or stop the job. You can also retrieve the ticket later from the batcher.
You should not change the configuration of a job after you start it, with the possible (rare) exception of updating the forest configuration if your cluster topology changes; for details, see Updating Forest Configuration for a Job. The job will run until you stop it or a fatal error occurs. For more details, see Job Control.
For an end-to-end example, see Example: Loading Documents From the Filesystem.
Adding Documents and Metadata to a Job
While the job is running, add documents to the job using WriteBatcher.add or WriteBatcher.addAs. You can add document content or a combination of content and metadata.
A WriteBatcher object is thread safe, so you can add data to the job from multiple threads.
Whenever your application adds enough documents to the batcher to compose a full batch, the batcher dispatches the batch to one of its job threads for uploading to MarkLogic. Each batch of documents is committed as a single transaction, so if any document in a batch cannot be committed, the whole batch fails. The success or failure of the batch is reported to appropriate attached listeners.
The batcher will always wait for a full batch by default. If your input rate is very slow, you can periodically flush partial batches using WriteBatcher.flushAsync.
The following code snippet adds files from a directory (signified by the DATA_DIR variable) to a job. For an end-to-end example, see Example: Loading Documents From the Filesystem.
try { Files.walk(Paths.get(DATA_DIR)) .filter(Files::isRegularFile) .forEach(p -> { String uri = "/dmsdk/" + p.getFileName().toString(); FileHandle handle = new FileHandle().with(p.toFile()); batcher.add(uri, handle); }); } catch (IOException e) { e.printStackTrace(); }
The batcher takes responsibility for closing any Closeable content or metadata handles you pass in. Such handles are closed by the batcher as soon as possible after the resource is written to MarkLogic.
If you have a resource that needs to be closed after writing, but is not closed by the handle, you should override the close method of your handle and dispose of your resource there.
Stopping a Write Job
Graceful shutdown of a write job should include draining the document queue before shutting down the job. You usually want to ensure that all documents that have been added to the job are fully processed (either committed to the database or rejected due to an error).
You can achieve graceful shutdown with the following steps:
- Stop any activity adding work to the job. That is, stop calling
WriteBatcher.addorWriteBatcher.addAs. As long as you keep adding work to the job, the batcher will keep dispatching work to job threads whenever a batch accumulates. - Call
WriteBatcher.flushAndWait. The batcher dispatches any partial batch in its work queue, and then waits for in-progress batches to complete. - Call
DataMovementManager.stopJob. The job is marked as stopped. Queued (but not yet started) tasks are cancelled. Subsequent calls toWriteBatcher.add,WriteBatcher.addAs,WriteBatcher.flushAndWait, andWriteBatcher.flushAsyncwill throw an exception.
If you are concerned that the JVM might exit before all work completes, you can call WriteBatcher.awaitCompletion after you call stopJob.
The following code snippet demonstrates a graceful shutdown.
DataMovementManager dmm = ...; WriteBatcher batcher = ...; // ... disable any input sources ... batcher.flushAndWait(); dmm.stopJob(ticket);
The following walkthrough explores the interactions between flush and stop in more detail to help you understand the tradeoff if you to shut a job down prematurely by just calling stopJob.
Suppose you have a write job with a batch size of 100, and the job is in the following state:
- Completed: Batches 1-3. That is, 300 documents have been written to MarkLogic and the listeners for these batches have completed their work.
- In-Progress: Batch 4 is being written to MarkLogic, but has not yet completed.
- In-Progress: Batch 5 has been written to MarkLogic, but the listeners have not completed their work.
- Not Started: 75 documents are sitting in the batcher's work queue, waiting for a full batch to accumulate.
Now, consider the following possible shutdown scenarios:
- Stop calling
WriteBatcher.addandWriterBatcher.addAs, then callWriteBatcher.flushAndWait, followed byDataMovementManager.stopJob. - You call
WriteBatcher.flushAndWait, followed byDataMovementManager.stopJob.- The
flushAndWaitcall creates a batch from the 75 documents in queue, then blocks until this batch and batches 4 and 5 complete. - Any batches that start between calling
flushAndWaitandstopJobwill complete, assuming the JVM does not exit. - Any partial batch that accumulates between the calls is discarded.
Calling
flushAsyncinstead offlushAndWaithas the same outcome, if the JVM does not exit before in-progress batches complete.
- The
- You call
DataMovementManager.stopJob.
Only sequence #1 ensures that no submitted documents are lost.
Write Job Performance Considerations
You should consider the following factors when configuring and tuning a write job:
Batch Size
The batch size configuration parameter of a WriteBatcher is the number of items that are sent to MarkLogic at once. The ideal batch size depends on many factors, including the size of the input documents and network latency. A batch size in the range 100-1000 works for most applications.
The following list calls out some factors you should consider when choosing a batch size:
- All items in a batch are sent to MarkLogic in a single request and committed as a single transaction.
- If your job updates existing documents, locks must be acquired on those documents and held for the lifetime of the transaction. A large batch size can thus potentially increase lock contention and affect overall application performance.
- Selecting a batch size is a speed vs. memory tradeoff. Each request to MarkLogic introduces overhead, but all the items in a batch must stay in memory until the batch is processed, so a larger batch size consumes more memory.
- Since the batcher will not send any queued items until a full batch accumulates, you should also consider the input rate of your application. A large batch size and a slow input rate can cause items to be in a pending state for a long time. You can avoid this by periodically calling
WriteBatcher.flushAsyncorWriteBatcher.flushAndWait.
Thread Count
The thread count configuration parameter of a WriteBatcher is the number of threads in the client JVM that will be dedicated to writing batches to MarkLogic. The threads operate in parallel, each servicing one batch at a time.
Ideally, you should choose a thread count that will keep most of the job threads busy and keep MarkLogic busy without overwhelming your cluster. You should usually configure at least as many client threads as hosts containing forests in the target database. The default is one thread per forest host.
Work Item Input Rate
Write job performance can be affected by the input rate. That is, by the rate at which you add documents to the batcher.
If you queue documents much faster than the batcher's job threads can process batches, you can overwhelm the batcher. When this happens, the batcher adopts a strategy that uses submitting threads instead of the busy job threads. This effectively throttles submitting threads and prevents the task queue from using too much memory, while still enabling the job to progress.
To tune performance, you can adjust the number of threads adding work to the batcher or the rate at which items are added.
Listener Design
When a batch succeeds or fails, the job thread that submitted the batch invokes all the appropriate listeners. If you register a listener that takes a long time to complete, it slows down the notification of other listeners for the same event, and slows down the rate at which the job can complete batches.
A listener can also slow down a job if it calls synchronized resources since lock contention can occur.
Example: Loading Documents From the Filesystem
The following example creates and configures a WriteBatcher job, and then feeds the job files all the files in a directory on the filesystem.
Though this example simply pulls input from the filesystem, it could come from any source supported by Java. For example, the application could asynchronously receive data from an ETL pipeline, a message queue, or periodically pull from a file system drop box.
The example attaches listeners to the batch success and batch failure events. The success listener logs the number of documents written so far, and the failure listener simply rethrows the failure exception. A production application would have more sophisticated listeners.
package examples; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import com.marklogic.client.io.*; import com.marklogic.client.datamovement.DataMovementManager; import com.marklogic.client.datamovement.WriteBatcher; import com.marklogic.client.DatabaseClientFactory; import com.marklogic.client.DatabaseClient; import com.marklogic.client.DatabaseClientFactory.DigestAuthContext; public class DMExamples { // replace with your MarkLogic Server connection information static String HOST = "localhost"; static int PORT = 8000; static String USER = "username"; static String PASSWORD = "password"; private static DatabaseClient client = DatabaseClientFactory.newClient( HOST, PORT, new DigestAuthContext(USER, PASSWORD)); private static String DATA_DIR = "/your/input/dir/"; // Loading files into the database asynchronously public static void importDocs() { // create and configure the job DataMovementManager dmm = client.newDataMovementManager(); WriteBatcher batcher = dmm.newWriteBatcher(); batcher.withBatchSize(5) .withThreadCount(3) .onBatchSuccess(batch-> { System.out.println( batch.getTimestamp().getTime() + " documents written: " + batch.getJobWritesSoFar()); }) .onBatchFailure((batch,throwable) -> { throwable.printStackTrace(); }); // start the job and feed input to the batcher dmm.startJob(batcher); try { Files.walk(Paths.get(DATA_DIR)) .filter(Files::isRegularFile) .forEach(p -> { String uri = "/dmsdk/" + p.getFileName().toString(); FileHandle handle = new FileHandle().with(p.toFile()); batcher.add(uri, handle); }); } catch (IOException e) { e.printStackTrace(); } // Start any partial batches waiting for more input, then wait // for all batches to complete. This call will block. batcher.flushAndWait(); dmm.stopJob(batcher); } public static void main(String[] args) { importDocs(); } }
Creating and Managing a Query Job
A query job takes either a query or a list of URIs as input, and distributes batches of URIs to listeners for action. The flow of a query job is outlined in Job Types.
The outcome of a query job is dependent on the actions taken by the listeners. This section covers the following topics common to all query jobs, regardless of the end goal.
- Creating and Configuring a Query Job
- Attaching Listeners to a Query Job
- Starting a Query Job
- Stopping a Query Job
- Using a Consistent Snapshot
- Performance Considerations for Query Jobs
To learn more about specific query job use cases, see the following topics:
- Reading Documents from MarkLogic
- Applying an In-Database Transformation
- Deleting Documents from a Database
Creating and Configuring a Query Job
To run a query job, use a QueryBatcher object created with DataMovementManager.newQueryBatcher. A QueryBatcher distributes batches of URIs to listeners registerd for the URIs ready event.
The set of URIs that a query job operates on can come from the following sources:
- A string query, structured query, or combined query. The job retrieves batches of URIs of matching documents from MarkLogic.
- A raw or unstructured query. Because it requires no transformation on the server, a raw query is faster than a structured query.
- An application-defined list of URIs (in the form of an
Iterator). The job splits these URIs into batches.
The following code snippet constructs a QueryBatcher based on a structured query. The query is a directory query on the path /dmsdk/.
// Assume "client" is a previously created DatabaseClient object. QueryManager qm = client.newQueryManager(); StructuredQueryBuilder sqb = qm.newStructuredQueryBuilder(); StructuredQueryDefinition query = sqb.directory(true, "/dmsdk/"); // Create the batcher DataMovementManager dmm = client.newDataMovementManager(); QueryBatcher batcher = dmm.newQueryBatcher(query);
The following code snippet takes a raw query (querydefRawCts).
QueryBatcher queryBatcher2 = dmManager.newQueryBatcher(querydefRawCts);
The raw CTS query is the representation of a query that executes most quickly. Although the Java API supports other kinds of raw queries, including a raw query that is equivalent to a structured query, raw queries are not as fast as a raw CTS query.
The following code snippet constructs a QueryBatcher based on a list of URIs.
// Assume "client" is a previously created DatabaseClient object. DataMovementManager dmm = client.newDataMovementManager(); String uris[] = {"/dmsdk/doc1.xml", "/dmsdk/doc3.xml", "/dmsdk/doc5.xml"}; QueryBatcher batcher = dmm.newQueryBatcher(Arrays.asList(uris).iterator());
You can configure runtime characteristics of the job, such as the batch size, thread count and whether or not to use a consistent snapshot of the documents in the database.
Whether or not to use a consistent snapshot is an important consideration for query jobs. For details, see Using a Consistent Snapshot.
The following code snippet sets the batch size and thread count, and imposes a consistent snapshot requirement for a previously created batcher.
batcher.withBatchSize(100) .withThreadCount(10) .withConsistenSnapshot() /* ... additional configuration ... */ ;
For more complete examples, see the following topics:
- Example: Exporting Documents that Match a Query
- Example: Applying an In-Database Transformation
- Deleting Documents from a Database
The order in which you configure job characteristics and attach listeners is not significant, other than that listeners for the same event are invoked in the order in which they're attached.
You should also attach at least one listener; for details, see Attaching Listeners to a Query Job.
Attaching Listeners to a Query Job
Whenever a QueryBatcher accumulates a batch of URIs, it dispatches the URIs to the listeners attached using QueryBatcher.onUrisReady. If you do not attach at least one onUrisReady listener, the job will not do anything meaningful.
You can attach listeners to a QueryBatcher for the following events:
- URIs ready: This event occurs whenever the batcher accumulates a batch of URIs to be processed. Use
QueryBatcher.onUrisReadyto attach aQueryBatchListenerto this event. - Query failure: This event can occur when you use a query to derive the list of URIs for a job, and the query fails for some reason. Use
QueryBatcher.onQueryFailureto attach aQueryFailureListenerto this event.
You should attach at least one success listener and one failure listener to perform application-specific monitoring and business logic. A listener has access to information that may not be captured by the default logging from the Java Client API.
The action taken when a batch of URIs is available is up to the onUrisReady listeners. Data Movement SDK comes with listeners that support the following operations.
- Read documents from MarkLogic (
ExportListener,ExportToWriterListener). For details, seeReading Documents from MarkLogic. - Apply an in-database transformation to documents in MarkLogic (
ApplyTransformListener). For details, see Applying an In-Database Transformation. - Delete documents in MarkLogic (
DeleteListener). For details, see Deleting Documents from a Database. - Log or otherwise track progress of a query job (
ProgressListener).
You can also create your own listeners. The listeners that come with Data Movement SDK are meant to serve as a starting point for your customizations.
The following code snippet illustrates attaching listeners to a query job. This job prints the URIs in each batch to stdout.
// Assume "dmm" is a previously created DatabaseMovementManager object // and "query" is a previously created StructuredQueryDefinition. DataMovementManager dmm = client.newDataMovementManager(); QueryBatcher batcher = dmm.newQueryBatcher(query); batcher.onUrisReady(batch -> { for (String uri : batch.getItems()) { System.out.println(uri); } }) .onQueryFailure( exception -> exception.printStackTrace() ); // ...additional configuration... dmm.startJob(batcher);
The order in which you configure job characteristics and attach listeners is not significant, other than that listeners for the same event are invoked in the order in which they're attached.
To learn more about listeners, see Working With Listeners.
Starting a Query Job
Start a job using DataMovementManager.startJob. For example:
// Assume "client" is a previously created DatabaseClient object DataMovementManager dmm = client.newDataMovementManager(); QueryBatcher batcher = dmm.newQueryBatcher(someQuery); // ... configure the job and attach listeners ... JobTicket ticket = dmm.startJob(batcher);
You receive a JobTicket that can be used to check status or stop the job. You can also retrieve the ticket later from the batcher.
You should not change the configuration of a job after you start it. The job will run until you stop it or a fatal error occurs. For more details, see Job Control.
Stopping a Query Job
A query job will go on dispatching batches of URIs to its listeners until all batches have been dispatched or you call DataMovementManager.stopJob. Follow these steps to ensure the listeners complete processing all URI batches before shutdown:
- Call
QueryBatcher.awaitCompletion. This call blocks until all URIs are processed. You can set a time limit on how long to block, but the job will go on processing batches after the timeout expires. - Call
DataMovementManager.stopJob. The job will not start any additional batches. In-progress batches will run to completion unless the JVM exits. Resources are released as the in-progress work completes.
For example, suppose you have a query job that will ultimately fetch 10 batches of URIs from MarkLogic, and the job is in the following state:
- Completed: Batches 1-3. That is, the URIs were dispatched to listeners and the listeners completed their work.
- In-Progress: Batch 4 is awaiting query results from MarkLogic.
- In-Progress: Batch 5 has been dispatched to the listeners, but the listeners have not completed their work.
- Not Started: Batches 6-10 not yet assigned to any job threads.
If you call awaitCompletion, the call will block until batches 4-10 are completed.
If you instead call stopJob, batches 4 and 5 will complete (unless the JVM exits), but batches 6-10 will not be processed, even if they could have been started while waiting on batches 4 and 5.
The following code gracefully shuts down a query job after it completes all work:
DataMovementManager dmm = ...; QueryBatcher batcher = ...; batcher.awaitCompletion(); dmm.stopJob(ticket);
The following code shuts down a job without necessarily completing all work. Work in progress when you call stopJob completes, but no additional work is done. The call to awaitCompletion is optional, but can be useful to prevent the application from exiting before work is completed.
DataMovementManager dmm = ...; QueryBatcher batcher = ...; dmm.stopJob(ticket); batcher.awaitCompletion();
Using a Consistent Snapshot
Consistent snapshot is a configuration option for a query job that causes the query driving the job to be evaluated against the state of the database at the point in time when the job begins.
- When to Use a Consistent Snapshot
- How to Use a Consistent Snapshot
- The Problem Solved by a Consistent Snapshot
When to Use a Consistent Snapshot
You must use a consistent snapshot if your job meets the following criteria:
- The job is driven by a query (rather than an application-defined list of URIs), and
- The job (or other activity) modifies the database in way that can cause successive evaluations of the query to return different results.
Failing to use a consistent snapshot under these circumstances can cause inconsistent and unpredictable job results. For details, see The Problem Solved by a Consistent Snapshot.
For example, you should always use a consistent snapshot when using DeleteListener or ApplyTransformListener with a query-driven job.
You might also want to use a consistent snapshot when reading documents from the database if you need to capture a deterministic set of documents and there is a possibility of the database contents changing while your job runs.
How to Use a Consistent Snapshot
To enable the use of a consistent snapshot, call QueryBatcher.withConsistentSnapshot and ensure your database configuration supports point-in-time queries.
The following code snippet configures a query job to use a consistent snapshot:
QueryBatcher batcher = dmm.newQueryBatcher(someQuery); batcher.withConsistentSnapshot();
This causes the job to evaluate the query as a point-in-time query. You might have to change your database configuration to enable point-in-time queries by setting a merge timestamp. For details, see Enabling Point-In-Time Queries in the Admin Interface in the Application Developer's Guide.
You might also want to use a consistent snapshot in your listeners. For example, ExportListener and ExportToWriterListener have a withConsistentSnapshot method you can use to ensure the listeners capture exactly the same set of documents as were matched by the query.
The Problem Solved by a Consistent Snapshot
When you drive a query job using a query (rather than a static list of URIs), the batcher fetches the URIs for matching documents incrementally, rather than fetching them all at once and holding them in memory.
The batches are fetched using the same pagination model that the search interfaces use to fetch results incrementally, specifying the desired page by a starting position in the results plus a page length. The examples below illustrate the problems that can occur if the query results are changing as the job runs.
Suppose the initial query for a job matches documents with the following URIs, and that the batch (page) size is 3. When the job fetches the first page, it gets the URIs for doc1, doc2, doc3.
doc1 doc2 doc3 doc4 doc5 doc6 doc7 doc8 doc9 doc10 -------------- -------------- -------------- ----- page 1 page 2 page 3 page 4
While that batch of URIs is being processed, a change in the database causes doc3 to no longer match the query. Thus, the query results now look like the following:
doc1 doc2 doc4 doc5 doc6 doc7 doc8 doc9 doc10 -------------- -------------- --------------- page 1 page 2 page 3
When the job requests the next page of matches, beginning at position 4, it gets back the URIs for doc5, doc6, and doc7. Notice that doc4 has been skipped because it is now in the first page of results, which has already been processed from the perspective of the job.
A similar problem can occur if the database changes in a way that adds a new document to the query results. Imagine that, after the job processes the first batch of URIs, a new docA matches the query and is part of the first page, as follows:
doc1 doc2 docA doc3 doc4 doc5 doc6 doc7 doc8 doc9 doc10 -------------- -------------- -------------- ---------- page 1 page 2 page 3 page 4
When the job fetches page 2, the batch includes doc3 again, which has already been processed. If the job is applying an in-database transformation, this double processing could have an undesirable effect.
If you use a consistent snapshot of the database state at the beginning of a query job, then the query always matches the same documents.
You might also want to use a consistent snapshot in your query job listeners, depending on the operation.
Consider a query job that uses ExportListener to read documents from the database. Say the batcher is running at a consistent snapshot, but the listener is not. Some time after the start of the job, one of the documents matching the query is deleted. The deleted document URI will still be included in a batch because of the consistent snapshot. However, the listener will get an error trying to read the nonexistent document.
The following diagram illustrates this case. The job starts at some time T. The document is deleted at time T+1. At T+2, the job produces a batch that includes the URI for the deleted document and passes it to the listener. If the listener is not pinned to a point-in-time, then it will find the deleted document does not exist, which might result in an error.
T T+1 T+2 |-------+------------+-----------+-------| job doc process start deleted doc
If you call ExportListener.withConsistentSnapshot as well as QueryBatcher.withConsistentSnapshot, then both the query evaluation and the URI processing will be carried out against a fixed snapshot of the database.
ExportToWriterListener also has a withConsistentSnapshot method.
Performance Considerations for Query Jobs
You should consider the following factors when configuring and tuning a query job:
Batch Size
For a query-driven job, the batch size configuration parameter of a QueryBatcher is the number of URIs that are fetched from MarkLogic at once. For a URI iterator driven job, batch size is the number of URIs the batcher picks off the list at once. In both cases, the batch size determines the number of items sent to the listeners for processing.
The ideal batch size depends on many factors, including the size of the input documents and network latency. A batch size in the range 100-1000 works for most applications.
The following list calls out some factors you should consider when choosing a batch size:
- Selecting a batch size is a speed vs. memory tradeoff. Each request to MarkLogic introduces overhead, but all the items in a batch must stay in memory until the batch is processed, so a larger batch size consumes more memory.
- Consider how batch size interacts with the implementation of your listener. For example, ExportListener fetches all the documents in a batch from MarkLogic in a single request, so a large batch size causes the listener to hold many documents in memory. For more details, see Listener Design.
Thread Count
The thread count configuration parameter of a QueryBatcher is the number of threads in the client JVM that will be dedicated to processing URI batches. The threads operate in parallel, each servicing one batch at a time.
Ideally, you should choose a thread count that will keep most of the job threads busy. If your listener interacts with MarkLogic, you should ideally also keep MarkLogic busy without overwhelming the cluster. For a job that interacts with MarkLogic, you should usually have more client threads than hosts containing forests in the target database.
Listener Design
The performance of a query job is heavily depending on the processing performed by the QueryBatcher.onUrisReady listeners.
When a batch of URIs is ready for processing, the batcher invokes each onUrisReady listener, in the order in which they were register. If you register a listener that takes a long time to complete, it delays the execution of other listeners for the same event, and slows down the rate at which the job can complete batches.
A listener can also slow down a job if it calls synchronized resources since lock contention can occur.
If one of your listeners is too slow, you can design it to do its processing in a separate thread, allowing control to return to the job and other listeners to execute.
Listener performance can be affected by batch size. For example, an ApplyTransformListener performs all the transformations for a batch of URIs as a single transaction. An open transaction holds locks on fragments with pending updates, potentially increasing lock contention and affecting overall application performance. If you run into lock contention, you might be able to address it by using a smaller batch size.
Reading Documents from MarkLogic
To read documents and/or metadata from MarkLogic using the Data Movement SDK, use a QueryBatcher and attach an ExportListener, ExportToWriterListener, or equivalent custom QueryBatchListener to onUrisReady. An export listener also has attached listeners. These listeners take action when the export listener has a document available for processing.
This section only details how to use ExportListener and ExportToWriterListener to read documents from MarkLogic with a query job. However, you can create your own listener for reading documents.
For more details, see the following topics:
- Using ExportListener to Read Documents
- Using ExportToWriterListener to Read Documents
- Example: Exporting Documents that Match a Query
This section assumes you are familiar with query job basics. If not, review Creating and Managing a Query Job.
Using ExportListener to Read Documents
When an ExportListener receives a batch of URIs from a QueryBatcher, it reads these documents from MarkLogic, and then dispatches each document to its own listener(s). Attach per-document listeners using ExportListener.onDocumentReady. For example, you might register a document listener that writes a document to the filesystem.
The following diagram illustrates the flow between QueryBatcher, ExportListener, and document listeners.
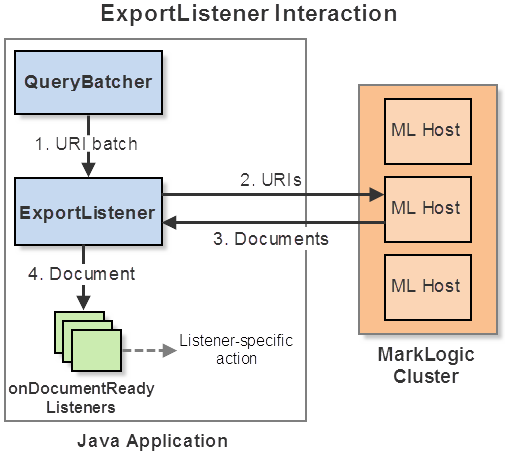
You can configure aspects of the ExportListener document read operation such as the following. For a complete list, refer to the Java Client API Documentation.
- Fetch metadata such as collections or properties, as well as document content. See
ExportListener.withMetadataCategory. - Use a consistent snapshot to fetch documents as they were when the query job started. See
ExportListener.withConsistenSnapshotand Using a Consistent Snapshot. - Apply a server-side read transform to each document before returning it to the client application. See
ExportListener.withTransform.
The ExportListener uses the interfaces described in Synchronous Multi-Document Operations to fetch the documents, so the listener blocks during the fetch. Each fetched document (and its metadata) is made available to the listeners as a DocumentRecord. This is the same interface used by the synchronous interfaces, such as the multi-document read shown in Read Multiple Documents by URI.
The following code snippet attaches a document listener in the form of a lambda function to an ExportListener. The document listener simply writes the return document to a known place in the filesystem (DATA_DIR), with a filename corresponding to the last path step in the URI.
// ...construct a query... QueryBatcher batcher = dmm.newQueryBatcher(query); batcher.onUrisReady( new ExportListener() .onDocumentReady(doc-> { String uriParts[] = doc.getUri().split("/"); try { Files.write( Paths.get(DATA_DIR, "output", uriParts[uriParts.length - 1]), doc.getContent(new StringHandle()).toBuffer()); } catch (Exception e) { e.printStackTrace(); } })) // ...additional configuration...
For a more complete example, see Example: Exporting Documents that Match a Query.
Using ExportToWriterListener to Read Documents
When you create an ExportToWriterListener, you must supply a Writer that will receive the documents read from MarkLogic. When an ExportToWriterListener receives a batch of URIs from a QueryBatcher, it reads these documents from MarkLogic, and then calls Writer.write on each document.
If sending the contents of each document to the writer as-is does not meet the needs of your application, you can register an output listener to prepare custom input for the writer. Use ExportToWriterListener.onGenerateOutput to register such a listener.
The following diagram illustrates the flow when you register an onGenerateOutput listener.
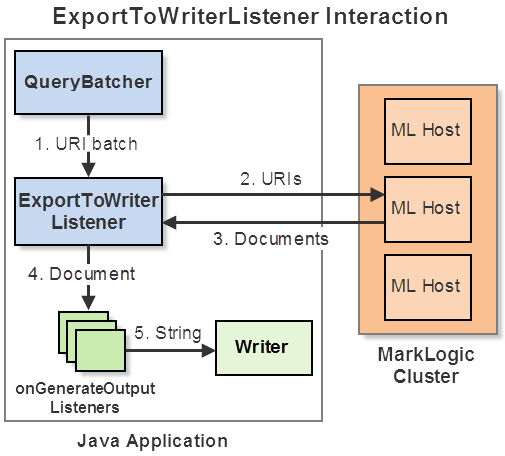
If you do not register an onGenerateOutput listener, then the flow in the above diagram skips Step 4. That is, the ExportToWriterListener sends content of each document directly to the Writer; metadata is ignored.
You can configure aspects of the ExportToWriterListener document read operation such as the following. For a complete list, refer to the Java Client API Documentation.
- Fetch metadata such as collections or properties, as well as document content. See
ExportToWriterListener.withMetadataCategory. You should register anonGenerateOutputListenerif you fetch metadata because the default flow with no listener ignores metadata. - Use a consistent snapshot, fetching documents as they were when the query job started. See
ExportToWriterListener.withConsistenSnapshotand Using a Consistent Snapshot. - Apply a server-side read transform to each document before returning it to the client application. See
ExportToWriterListener.withTransformand Applying a Read or Write Transformation. - Prepend a string to the output sent to the
Writerfor each document. This prefix is included whether or not control flow goes through anonGenerateOutputListener. SeeExportToWriterListener.withRecordPrefix. - Append a string to the output sent to the
Writerfor each document. This suffix is included whether or not control flow goes through anonGenerateOutputListener. SeeExportToWriterListener.withRecordSuffix.
The ExportToWriterListener uses the interfaces described in Synchronous Multi-Document Operations to fetch the documents, so the listener blocks during the fetch. Each fetched document (and its metadata) is made available to the onGenerateOutput listeners as a DocumentRecord. This is the same interface used by the synchronous interfaces, such as the multi-document read shown in Read Multiple Documents by URI.
The following example creates an ExportToWriterListener that is configured to fetch documents and collection metadata. The onGenerateOutput listener generates a comma-separated string containing the document URI, first collection name, and the document content. ExportToWriterListener.withRecordSuffix is used to emit a newline after each document is processed. The end result is a three-column CSV file.
FileWriter writer = new FileWriter(outputFile)); ExportToWriterListener listener = new ExportToWriterListener(writer) .withRecordSuffix("\n") .withMetadataCategory(DocumentManager.Metadata.COLLECTIONS) .onGenerateOutput( record -> { try{ String uri = record.getUri(); String collection = record.getMetadata(new DocumentMetadataHandle()) .getCollections().iterator().next(); String contents = record.getContentAs(String.class); return uri + "," + collection + "," + contents; } catch (Exception e) { e.printStackTrace(); } } );
For the complete example, see ExportToWriterListenerTest in com.marklogic.client.test.datamovement. The test source is available on GitHub. For more details, see Downloading the Library Source Code.
Example: Exporting Documents that Match a Query
The following function uses QueryBatcher and ExportListener to read documents from MarkLogic and save them to the filesystem. The job uses a structured query to select the documents to be exported. Further explanation follows the code sample.
// Assume "client" is a previously created DatabaseClient object. private static String EX_DIR = "/your/directory/here"; private static DataMovementManager dmm = client.newDataMovementManager(); // ... public static void exportByQuery() { // Construct a directory query with which to drive the job. QueryManager qm = client.newQueryManager(); StructuredQueryBuilder sqb = qm.newStructuredQueryBuilder(); StructuredQueryDefinition query = sqb.directory(true, "/dmsdk/"); // Create and configure the batcher QueryBatcher batcher = dmm.newQueryBatcher(query); batcher.onUrisReady( new ExportListener() .onDocumentReady(doc-> { String uriParts[] = doc.getUri().split("/"); try { Files.write( Paths.get(EX_DIR, "output", uriParts[uriParts.length - 1]), doc.getContent( new StringHandle()).toBuffer()); } catch (Exception e) { e.printStackTrace(); } })) .onQueryFailure( exception -> exception.printStackTrace() ); dmm.startJob(batcher); // Wait for the job to complete, and then stop it. batcher.awaitCompletion(); dmm.stopJob(batcher); }
The query driving the job is a simple directory query that matches all documents in the directory /dmsdk/, such as the documents inserted in Example: Loading Documents From the Filesystem:
QueryManager qm = client.newQueryManager(); StructuredQueryBuilder sqb = qm.newStructuredQueryBuilder(); StructuredQueryDefinition query = sqb.directory(true, "/dmsdk/");
You can use any string, structured, or combined query. For details on query construction, see Searching.
The ExportListener.onDocumentsReady listener attached by the example writes each document to the filesystem, using the last path step in the URI as the file name. That is, if the document URI is /dmsdk/doc1.xml, then a file named doc1.xml is written to the output directory. The output directory is EX_DIR/output/, where EX_DIR is a variable holding the path of your choice.
new ExportListener() .onDocumentReady(doc-> { String uriParts[] = doc.getUri().split("/"); try { Files.write(Paths.get(EX_DIR, "output", uriParts[uriParts.length - 1]), doc.getContent(new StringHandle()).toBuffer()); } catch (Exception e) { e.printStackTrace(); } }))
The ExportListener.onQueryFailure listener is just a lambda function that emits a stack trace. You would use a more sophisticated listener in a production application.
Applying an In-Database Transformation
You can use the Data Movement SDK to orchestrate in-place transformations of documents already in the database by using an ApplyTransformListener with a QueryBatcher. This section includes the following topics:
- Applying an In-Database Transformation with QueryBatcher
- Example: Applying an In-Database Transformation
Applying an In-Database Transformation with QueryBatcher
An in-database transformation is driven by a client-side query job, but carried out entirely inside MarkLogic, without fetching any documents to the client. Use a QueryBatcher with an ApplyTransformListener attached to the batcher's onUrisReady event. You could also create a custom transform listener.
This section assumes you are familiar with query job basics. If not, review Creating and Managing a Query Job.
The following diagram illustrates the default flow of query job that performs an in-database transformation.
By default, the output of the transform replaces the original document in MarkLogic.You can configure the listener to run the transform without updating the source document by calling ApplyTransformListener.withApplyResult. For example, you could use this approach if your transform computes an aggregate over the documents matching a query and stores the result elsewhere in the database.
The transform to be applied by the job must be installed on MarkLogic before you can use it. Data Movement SDK uses the same transform framework as the single document operations and synchronous multi-document operations. For details on authoring and installing a transform, see Content Transformations.
You identify the transform by supplying a ServerTransform object when you create the ApplyTransformListener for the job.
The following example applies a previously installed transformation to a set of URIs using a query job. The contents of the three target documents are replaced by the documents created by the transform function.
private static DataMovementManager dmm = client.newDataMovementManager(); // ... public static void inPlaceTransform(String txName) { ServerTransform txform = new ServerTransform(txName); String uris[] = {"/dmsdk/doc1.xml", "/dmsdk/doc3.xml", "/dmsdk/doc5.xml"}; QueryBatcher batcher = dmm.newQueryBatcher(Arrays.asList(uris).iterator()); batcher.withConsistentSnapshot() .onUrisReady( new ApplyTransformListener().withTransform(txform)) .onQueryFailure( exception -> exception.printStackTrace() ); dmm.startJob(batcher); batcher.awaitCompletion(); dmm.stopJob(batcher); }
For a more complete example, see Example: Applying an In-Database Transformation.
All the transformed documents associated with a batch of URIs are committed as a single transaction, so if the transformation of any document fails, the whole batch fails. The absence of a targeted document in the database is not treated as an error and does not cause the batch to fail. Such documents are simply skipped.
If you use a query to select the documents to be transformed, then you should use QueryBatcher.withConsistentSnapshot with ApplyTransformListener. For details, see Using a Consistent Snapshot.
You can attach listeners to an ApplyTransformListener to receive notifications about batch success, batch failure, and skipped document events. These listeners use the QueryBatchListener interface. Use the following methods to attach listeners:
ApplyTransformListener.onSuccess: Register a listener that is called whenever all the documents corresponding to a batch of URIs have been successfully transformed or skipped. The URIs of the batch of transformed documents are accessible through the registered listener'sgetItemsmethod.ApplyTransformListener.onSkipped: Register a listener that is called whenever one or more documents corresponding to a batch of URIs were not found in the database. The URIs of the missing documents are accessible throughgetItemsmethod of the batch passed to the listener.ApplyTransformListener.onBatchFailure: Register a listener that is called whenever an entire batch of transformations is rejected due to an error transforming at least one document.
Example: Applying an In-Database Transformation
The example in this section applies an in-database XQuery transformation using QueryBatcher and ApplyTransformListener.
The following XQuery module implements a trivial transform that inserts a <now/> XML child element into the input document if the root element is <data/>. (This matches the document structure created by Example: Loading Documents From the Filesystem.) The element value is the current xs:dateTime when the transform is applied. For more details, see Writing Transformations.
xquery version "1.0-ml"; module namespace dmex = "http://marklogic.com/rest-api/transform/dm-in-place"; (: Add an element named "now" that contains the current dateTime. :) declare function dmex:transform( $context as map:map, $params as map:map, $content as document-node()) as document-node() { if (fn:empty($content/data)) then $content else document { let $root := $content/* return element {fn:name($root)} { element now { fn:current-dateTime() }, $root/@*, $root/node() } } };
The following server-side Javascript module implements a trivial transform that adds a property named writeTimestamp corresponding to the current dateTime to the document stored in the database. If the input document is not JSON, the content is unchanged.
function insertTimestamp(context, params, content)
{
if (context.inputType.search('json') >= 0) {
const result = content.toObject();
result.writeTimestamp = fn.currentDateTime();
return result;
} else {
/* Pass thru for non-JSON documents */
return content;
}
};
exports.transform = insertTimestamp;If you any of the above codes to a file (namefile.xqy or namefile.sjs), you can install it on MarkLogic with code similar to the following. This function expects the transform name (which is subsequently used to identify the transform during operations), and the name of the file containing the code as input. It reads the file from EX_DIR/ext/txFilename and installs it under the specified name.
// Assume "client" is a previously created DatabaseClient object. // The example also assumes the following context: private static String EX_DIR = "/your/data/dir/here/"; private static DataMovementManager dmm = client.newDataMovementManager(); // Helper function for installing transformations. public static void installTransform(String txName, String txFilename) { FileHandle txImpl = new FileHandle().with( Paths.get(EX_DIR, "ext", txFilename).toFile()); TransformExtensionsManager txmgr = client.newServerConfigManager() .newTransformExtensionsManager(); txmgr.writeXQueryTransform(txName, txImpl); // Or, if you use a servser-side JavaScript module txmgr.writeJavascriptTransform(txName, txImpl); }
For more details, see Installing Transforms.
Assuming the transformation is installed, the following function creates a query job to apply it to a set of documents specified by a URI list. You could also apply it to documents matching a query.
public static void inPlaceTransform(String txName) { ServerTransform txform = new ServerTransform(txName); String uris[] = { "/dmsdk/doc1.xml", "/dmsdk/doc3.xml", "/dmsdk/doc5.xml"}; QueryBatcher batcher = dmm.newQueryBatcher(Arrays.asList(uris).iterator()); batcher.onUrisReady( new ApplyTransformListener().withTransform(txform)) .onQueryFailure( exception -> exception.printStackTrace() ); dmm.startJob(batcher); batcher.awaitCompletion(); dmm.stopJob(batcher); }
The example accepts the transform name as input and constructs a ServerTransform object from this name. The ServerTransform is required to configure the ApplyTransformListener. For more details, see Using Transforms.
ServerTransform txform = new ServerTransform(txName); ... new ApplyTransformListener().withTransform(txform)
Whenever a batch of URIs is ready for processing, the ApplyTransformListener applies the transform to all the documents in the batch.
If the job was driven by a query rather than a list of URIs, you would include a call to QueryBatcher.withConsistentSnapshot in the job configuration. You should use a consistent snapshot when running query driven jobs that modify the database. For details, see Using a Consistent Snapshot.
Deleting Documents from a Database
You can use the Data Movement SDK to delete documents stored in MarkLogic by using a DeleteListener with a QueryBatcher. This section assumes you are familiar with query job basics. If not, review Creating and Managing a Query Job.
As with any query job, the target URIs are fetched to the client so that the delete operation can be distributed across the cluster. No documents are fetched to the client. You can select the documents to be deleted by specifying a query or supplying a list of URIs.
A job that deletes documents alters the state of the database in a way that affects query results. If you use a query to select the documents for deletion, you should enable merge timestamps on the database and use a consistent snapshot. For more details, see Using a Consistent Snapshot.
All the deletions associated with a batch of URIs are committed as a single transaction, so if the deletion of any document fails, the whole batch fails. Note that the absence of a targeted document in the database is not treated as an error and does not cause the batch to fail.
The following example deletes all documents where the data element has a value of 5:
// Assume "client" is a previously created DatabaseClient object and // "dmm" is a previously created DataMovementManager. public static void deleteDocs() { QueryManager qm = client.newQueryManager(); StructuredQueryBuilder sqb = qm.newStructuredQueryBuilder(); StructuredQueryDefinition query = sqb.value(sqb.element("data"),5); QueryBatcher batcher = dmm.newQueryBatcher(query); batcher.withConsistentSnapshot() .onUrisReady(new DeleteListener()) .onQueryFailure( exception -> exception.printStackTrace() ); dmm.startJob(batcher); batcher.awaitCompletion(); dmm.stopJob(batcher); }
Applying a Read or Write Transformation
You can apply a server-side transformation to documents when you insert them into MarkLogic with a write job. Similarly, you can apply a server-side transformation to documents when you read them from MarkLogic using a query job.
Applying a read or write transformation uses the same framework as an in-database transformation (and other Java Client API document operations), but the flow is different. A write transform is applied to content received from the client; this content may not already be present in the database. A read transform is applied to content just before it is returned to the client, leaving the document in the database unchanged.
You must install a transformation in MarkLogic before you can use it in a job. Other Java Client API document operations use the same transformation framework, including single document operations and synchronous multi-document operations. Authoring and installation of transformations are discussed in Content Transformations.
Configure a write transformation using WriteBatcher.withTransform. Supply a ServerTransform object that represents a previously installed transformation. When creating the ServerTransform, you must use the name under which the transform is installed on MarkLogic.
The following code snippet configures a WriteBatcher with a write transform.
DataMovementManager dmm = ...; WriteBatcher batcher = dmm.newWriteBatcher(); batcher.withBatchSize(5) .withThreadCount(3) .withTransform(new ServerTransform(txName)) // ...additional configuration ;
For a query job, the listener determines whether or not to support a transform because the action performed by the job is determined by the listener. For example, ExportListener and ExportToWriterListener both have a withTransform method through which you can specify a server-side read transform. However, a transform makes no sense in the context of a DeleteListener, so it has no such method.
The following code snippet configures an ExportListener with a read transform.
DataMovementManager dmm = ...; QueryBatcher batcher = dmm.newQueryBatcher(query); batcher.onUrisReady( new ExportListener() .withTransform(new ServerTransform(txName)) .onDocumentReady(...)) .onQueryFailure(...);
Job Control
- Checking the Status of a Job
- Pausing and Restarting a Job
- Graceful Termination of a Job
- Terminating a Job Prematurely
- Updating Forest Configuration for a Job
- Working with a Load Balancer
- Restricting the Hosts Used by a Job
Checking the Status of a Job
When you start a job, you receive a JobTicket. You can use the JobTicket to retrieve the type and id of a job, and to get a job report (using DataMovementManager.getJobReport). The job report provides statistics such as the number of successfully processed batches. The meaning of the statistics depends on the type of job; refer to the javadoc for JobReport for details.
The following code snippet retrieves a job report from the ticket for a write job:
DataMovementManager dmm = ...; WriterBatcher batcher = dmm.newWriteBatcher(); //... JobTicket ticket = dmm.startJob(batcher); //... JobReport report = dmm.getJobReport(ticket);
You can also retrieve batch-level information about a job within a listener. For example, a WriteBatcher.onBatchSuccessListener can call WriteBatch.getJobWritesSoFar.
A JobReport gathers its statistics by querying listeners that are automatically attached to query and write job batchers. For example, a WriteJobReportListener is automatically attached to the onBatchSuccess and onBatchFailure events when you create a WriteBatcher.
You can use the implementation of these listeners as a starting point for your own reporting, and even replace the default reporting listeners with your own. For more information on replacing listeners, see Working With Listeners.
Pausing and Restarting a Job
The Data Movement SDK does not support restarting jobs. Once you call DataMovementManager.stopJob, you cannot perform additional work with the job.
You can effectively mimic pausing and restarting a write job by controlling the flow of work into the job. For example, the following steps pause and restart a write job:
- Stop any activity that calls
WriteBatcher.addorWriteBatcher.addAs. - Call
WriteBatcher.flushAndWaitorWriteBatcher.flushAsync. This ensure any partial batch is processed and in-progress batches get completed. - When you're ready to resume work, start calling
WriteBatcher.addandWriteBatcher.addAsagain.
After Step 2, above, the job is effectively paused since it has finished all available work and new work is not arriving.
A query job always runs until all URIs are processed unless you shut it down prematurely. However, you can effectively pause a query job by blocking the listener(s). For example, you could create a listener that conditionally blocks on an object by calling Object.wait. For a timed pause, pass a timeout period to wait. You can use Object.notifyAll to reactivate all listeners and resume processing.
Graceful Termination of a Job
Graceful termination means shutting down a job in a way that leaves it in a deterministic state. For example, if you were to abruptly terminate a write job, some queued documents might not be written to the database.
Graceful termination usually means draining the work queue of a job before calling DataMovementManager.stopJob. These steps differ between write jobs and query jobs. For details on shutting down each type of job, see the following topics:
A job cannot be restarted after calling DataMovementManager.stopJob.
Terminating a Job Prematurely
If you need to stop a job without waiting for work to be completed, you can call DataMovementManager.stopJob without first calling methods that drain the work queue like WriteBatcher.flushAndWait or QueryBatcher.awaitCompletion.
If you do not follow the graceful shutdown procedure, you cannot guarantee that queued work will be started or in-progress work will be completed after calling stopJob. Any work that started prior to calling stopJob will be allowed to complete as long as the JVM does not exit.
For example, if documents have been added to a write job, but a full batch has not yet accumulated, the partial batch will not be processed.
For details on shutting down each type of job, see the following topics:
A job cannot be restarted after calling DataMovementManager.stopJob.
Updating Forest Configuration for a Job
This section describes how to update a batcher's understanding of which hosts in a cluster include forests for the database on which the job operates. You are unlikely to need to do this unless you have a very long running job and change your cluster topology.
As mentioned in How Work is Distributed Across a Cluster, when you create a batcher, the DataMovementManager initializes the batcher with information about which hosts in your MarkLogic cluster contain forests in the database targeted by the job. The batcher uses this forest configuration information to determine how to distribute work across the cluster.
If you change the database forest locations in such a way that this list of forest hosts becomes inaccurate, the batcher will not be aware of the change. For example, if you add a forest to a host that previously contained no forests for the database, the batcher will not direct work to the new host.
To refresh a batcher's forest model, pass the output of DataMovementManager.readForestConfiguration to Batcher.withForestConfig. When you call DataMovementManager.readForestConfig(), the DataMovementManager queries the cluster for the current forest configuration and returns the new configuration. For example:
DataMovementManager dmm = ...; WriteBatcher batcher = ...; dmm.startJob(batcher); // some time later... batcher.withForestConfig(dmm.readForestConfig());
Working with a Load Balancer
By default, a job tries to connect directly to multiple hosts in your cluster in order to efficiently distribute work. However, if there is a load balancer sitting between your client application and your MarkLogic cluster, these direct connections may not be possible.
In such a case, you must configure your DatabaseClient objects to specify a GATEWAY connection, instead of the default DIRECT connection. For example:
DatabaseClient client = DatabaseClientFactory.newClient( "localhost", 8000, "MyDatabase", new DatabaseClientFactory.DigestAuthContext("myuser", "mypassword"), DatabaseClient.ConnectionType.GATEWAY);
You cannot use a FilteredForestConfiguration with a GATEWAY connection since all traffic will be routed through the gateway.
You should configure your load balancer timeout periods to be consistent with your MarkLogic cluster timeouts. For more details, see Connecting Through a Load Balancer.
For details on failover handling, see Failover When Connecting Through a Load Balancer.
Restricting the Hosts Used by a Job
By default, a job tries to connect to all hosts in your cluster that contain forests in the database. This optimizes the performance of your job. However, if you need to restrict host list for a reason other than connecting through a load balancer, you can use FilteredForestConfiguration to configure that list.
If you connect to MarkLogic through a load balancer, see Working with a Load Balancer, instead of using FilteredForestConfiguration.
You can configure a white list (hosts allowed) or a black list (host disallowed). The Java Client API uses the same mechanism internally to manage failover.
The following example restricts a job to connecting to MarkLogic through only the hosts good-host-1 and good-host-2:
// Assume "dmm" is a previously created DataMovementManager object. batcher.withForestConfig( new FilteredForestConfiguration( dmm.readForestConfig() ).withWhiteList("good-host-1", "good-host-2") );
Note that limiting a job to connect to a restricted host list can negatively impact the performance of your job.
Failover Handling
Failover occurs when a forest or a host in a cluster becomes unavailable due to events such as a forest restart or a host becoming unreachable. The unavailable host might become available again or be replaced by a failover host that is configured for the database as described in High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide. The Data Movement SDK attempts to recover from such events with no data loss.
This section covers the following topics:
- Default Failover Handler
- Failover When Connecting Through a Load Balancer
- Interaction with In-Database Transform
- Failover Handling in Custom Listeners
Default Failover Handler
The Data Movement SDK provides a default error handling listener, HostAvailabilityListener, for managing failover events. Whenever you create a QueryBatcher or a WriteBatcher object, a HostAvailabilityListener is attached to it. You can also use HostAvailabilityListener as an example for creating your own failover handler.
This discussion applies when you connect directly to MarkLogic. If you connect through a load balancer, see Failover When Connecting Through a Load Balancer.
When the HostAvailabilityListener detects an unavailable host, the Data Movement SDK responds as follows:
- Check to see if the configured minimum number of hosts remain in the forest configuration (minus the failed host). If not, stop the job with an error. If so, proceed with the recovery procedure.
- To avoid repeated occurrences of the same error, remove the failed host from the forest configuration on which the job operates. The failed host is considered suspended for a configurable time period and will not be used by the job while in this state.
- Schedule an asynchronous task to re-acquire the forest configuration from MarkLogic when the suspension time period expires. This enables the failed host to come back into rotation or be replaced by a failover host.
- Retry the failed batch with one of the hosts remaining in the forest configuration modified in Step 2.
Use HostAvailabilityListener.withSuspendTimeForHostUnavailable to configure the suspension time period. The default suspension period is 10 minutes.
Use HostAvailabilityListener.withMinHosts to configure the minimum number of host required to enable retrying a failed batch.
Use HostAvailabilityListener.withHostUnavailableExceptions to configure the exceptions that trigger the retry flow. By default, HostAvailabilityListener acts on the following exceptions classes: SocketException, SSLException, UnknownHostException.
For example, the following code configures the default HostAvailability listener attached to a batcher with a suspension period of 5 minutes and a two host minimum:
HostAvailabilityListener.getInstance(batcher) .withSuspendTimeForHostUnavailable(Duration.ofMinutes(5)) .withMinHosts(2);
If the behavior of HostAvailabilityListener does not meet the needs of your application, you can use it as a basis for developing your own failover handler. To review the implementation on GitHub or download a local copy of the source code, see Downloading the Library Source Code.
Failover When Connecting Through a Load Balancer
When you connect to MarkLogic through a load balancer, you must configure your DatabaseClient objects to use a GATEWAY connection, as described in Working with a Load Balancer.
When you use a GATEWAY connection, all traffic goes through the load balancer host, so it is not possible for the job to modify its host list if a host in your MarkLogic cluster becomes unavailable, as described in Default Failover Handler.
Instead, HostAvailabilityListener retries against the load balancer for some time. When the MarkLogic cluster successfully recovers from the host failure, batches submitted through the load balancer start succeeding again.
If the MarkLogic cluster is not able to recover within the timeout period, then the job fails. If the load balancer host becomes unavailable, your job is cancelled.
Interaction with In-Database Transform
When you attach an ApplyTransformListener to a QueryBatcher, the retry mechanism described in Default Failover Handler applies only to the process of fetching batches of URIs from MarkLogic by default because the Java Client API cannot assume it is safe to retry the intended in-database transformation or deletion.
If a failover event occurs while fetching a batch of URIs, HostAvailabilityListener retries the failed URI fetch, just as it does when handling failovers for reading and writing documents. If a failover event occurs after a batch of URIs is dispatched to an attached onUrisReady listener such as an ApplyTransformListener, the batch will fail by default if a failover event occurs.
To handle this more complex situation, the Java Client API supports the following types of listener for failover handling:
HostAvailabilityListener: If a failover event occurs while fetching a batch of URIs,HostAvailabilityListenerretries the failed URI fetch, just as it does when handling failovers for reading and writing documents.NoResponseListener: Handles the case where no response is received from MarkLogic. The defaultNoResponseListenerhandles the case where no response is received while fetching URIs. This listener is register by default for all listeners created by the Java Client API.BatchFailureListener<QueryBatch>forHostAvailabilityListener: Implements the retry logic when a qualifying exception is raised while fetching URIs. Such a retry listener is associated with all listeners created by the Java Client API, includingApplyTransformListener.BatchFailureListener<QueryBatch> for NoResponseListener: Implements the retry logic when no response is received from MarkLogic during the transform operation. The Java Client API adds this listener to listeners for idempotent operations, such as DeleteListener. It is not added toApplyTransformListenerby default
If you know that your transform is idempotent and can safely be repeated, then you can enable failover handling for the no response case by attaching a retry listener to the NoResponseListener. For example:
ApplyTransformListener txformListener = new ApplyTransformListener() .withTransform(txform); QueryBatcher batcher = ...; NoResponseListener noResponseListener = NoResponseListener.getInstance(batcher); if (noResponseListener != null) { BatchFailureListener<QueryBatch> retryListener = noResponseListener.intializeRetryListener(txformListener); if (retryListener != null) { txformListener.onFailure(retryListener); } }
If your in-database transform is not idempotent, but you want to retry in some no-response cases, you implement your own BatchFailureListener. For details, see Conditionally Retry.
Failover Handling in Custom Listeners
This section describes how to implement failover handling in a custom listener. Your listener can respond to failover events in the following ways:
- Never retry. Allow the batch to fail. You do not need to write any special code to address this case. This is the default behavior of
ApplyTransformListener. - Always Retry. If the operation performed by the listener is idempotent, such as document write or delete, then you can always safely retry.
DeleteListenerimplements this approach. - Conditionally Retry. You must implement a custom
BatchFailureListenerfor this case.
Always Retry
If you create a custom QueryBatchListener that should always retry on a qualifying error, override the initializeListener method to do the following:
- Obtain the
HostAvailabilityListenerfrom the batcher.HostAvailabilityListener hostAvailabilityListener = HostAvailabilityListener.getInstance(queryBatcher);
- Obtain a
RetryListenerby callingHostAvailabilityListener.intializeRetryListener.BatchFailureListener<QueryBatch> retryListener = hostAvailabilityListener.initializeRetryListener(this);
- Register the
RetryListeneras anonFailureListenerof your custom listener.if ( retryListener != null ) onFailure(retryListener);
- Obtain a
NoResponseListenerfrom the batcher.NoResponseListener noResponseListener = NoResponseListener.getInstance(queryBatcher);
- Obtain a
RetryListenerby callingNoResponseListener.initializeRetryListener.BatchFailureListener<QueryBatch> noResponseRetryListener = noResponseListener.initializeRetryListener(this);
- Register the
RetryListeneras anonFailurelistener of your custom listener.if ( noResponseRetryListener != null ) onFailure(noResponseRetryListener);
The RetryListener for the noResponseListener is required to handle cases where a host becomes unavailable without returning any response from MarkLogic, rather than raising an error.
The following code puts these steps together into an implementation of initializeListener for a custom query batch listener:
public class myListener : extends Object implements QueryBatchListener { // ... @Override public void initializeListener(QueryBatcher queryBatcher) { HostAvailabilityListener hostAvailabilityListener = HostAvailabilityListener.getInstance(queryBatcher); if ( hostAvailabilityListener != null ) { BatchFailureListener<QueryBatch> retryListener = hostAvailabilityListener.initializeRetryListener(this); if ( retryListener != null ) onFailure(retryListener); } NoResponseListener noResponseListener = NoResponseListener.getInstance(queryBatcher); if ( noResponseListener != null ) { BatchFailureListener<QueryBatch> noResponseRetryListener = noResponseListener.initializeRetryListener(this); if ( noResponseRetryListener != null ) onFailure(noResponseRetryListener); } } };
See the implementation of com.marklogic.client.datamovement.DeleteListener for a complete example. To review the implementation on GitHub or download a local copy of the source code, see Downloading the Library Source Code.
Conditionally Retry
If you only want to retry your operation under certain circumstances, do the following:
- Create a class that implements
BatchFailureListener<QueryBatch>. Implement your retry logic in theprocessFailuremethod. - Attach an instance of your
BatchFailureListeneras anonFailurelistener of your custom listener.
To initiate a retry from your batch failure listener, invoke QueryBatcher.retry. This enables a retry if an error occurs when fetching URIs. For example:
public void processFailure(QueryBatch batch, Throwable throwable) { // ... batch.getBatcher().retry(batch); // ... }
To create a custom availability listener, override QueryBatchListener.intializeListener. The default implementation of this method does nothing. Your implementation should be similar to the following:
@Override public void initializeListener(QueryBatcher queryBatcher) { HostAvailabilityListener hostAvailabilityListener = HostAvailabilityListener.getInstance(queryBatcher); if ( hostAvailabilityListener != null ) { BatchFailureListener<QueryBatch> retryListener = hostAvailabilityListener.initializeRetryListener(this); if( retryListener != null ) onFailure(retryListener); } }
The batcher calls the initializeListener method on each attached QueryBatchListener.
The retry listener should call QueryBatchListener.retryListener in its processFailure method to re-attempt the failed operation. That is, to retry in cases where a batch of URIs is successfully retrieved from MarkLogic, but a failure occurs during the in-database operation. For an example, see the implementation of HostAvailabilityListener.RetryListener.processFailure.
Working With Listeners
A listener is a callback through which your application responds to interesting job state changes, such as when a write job successfully inserts a batch of documents, or a query job prepares a batch of URIs for processing.
This section covers the following listener-related topics:
- Guidelines for Creating Listeners
- Attaching Multiple Listeners to a Job
- Removing or Replacing a Listener
Guidelines for Creating Listeners
Data Movement SDK pre-defines several listener classes that are fully functional, but also meant to serve as a starting place for you to implement your own listeners.
For example, Data Movement SDK includes an ExportToWriterListener class for reading documents from the database and sending the contents as a string to a Writer. You might create a custom listener that also emits metadata, or one that generates zip file entries instead of strings.
When creating your own listeners, keep the following points in mind:
- All listener code must be thread safe because listeners are executed asynchronously across all job threads. For example, you should not have multiple listeners updating a shared collection unless the collection is thread safe (
Collections.synchronizedMap<T>,Collections.synchronizedList<T>,ConcurrentHashMap,ConcurrentLinkedQueue, etc.). - In query jobs driven by a query (rather than a fixed set of URIs), each
QueryBatchListenerhas access to the host and forest that contain the documents identified by a URI batch. Your job will be more efficient if you use the same host for your per batch operations. SeeQueryBatch.getClientandQueryBatch.getForest.
The thread safety requirement also applies to listener listeners. For example, if you attach document ready event listeners to an ExportListener (ExportListener.onDocumentReady) that code must also be thread safe.
Attaching Multiple Listeners to a Job
You can attach listeners to multiple events, and you can attach multiple listeners to a single event. When there are multiple listeners for an event, they are invoked serially, in the order in which they were attached to the job. An event is not complete until all listeners complete their processing.
For example, when you create a WriteBatcher, the DataMovementManager automatically attaches a WriteJobReportListener to the batch success event. When you attach your own batch success or failure event listeners using WriteBatcher.onBatchSuccess, it doesn't replace the WriteJobReportListener. Rather, the batch success event now has multiple listeners.
You can probe the listeners attached to a job using methods such as WriteBatcher.getBatchSuccessListeners and QueryBatcher.getQueryFailureListeners.
Removing or Replacing a Listener
You can add a listener to a batcher using the appropriate onEvent method, such as WriteBatcher.onBatchSuccess. You should not attach a listener to a running job.
To remove or replace a listener, you must retrieve the list of listeners attached to an event, modify the list, and set the listener list on the batcher to the value of the new list.
Note that the Data Movement SDK attaches a default set of listeners to WriteBatcher and QueryBatcher in support of job reporting, error recovery, and job management. If you replace or remove the entire set of listeners attached to an event, you will lose these automatically attached listeners.
The WriteBatcher and QueryBatcher interfaces include setters and getters for their respective event listener lists. For example, the QueryBatcher interface includes getUrisReadyListeners and getQueryFailureListeners methods.
The listener classes provided by Data Movement SDK, such as ExportListener, do not expose any kind of listener id. You can only distinguish them on the listener list by probing the type.
The following code snippet demonstrates removing a custom batch success listener from a WriteBatcher.
WriteBatchListener oldListeners[] = batcher.getBatchSuccessListeners(); ArrayList<WriteBatchListener> newListeners = new ArrayList<WriteBatchListener>(); for (WriteBatchListener listener : oldListeners) { if (!(listener instanceof MyWriteBatchListener)) { newListeners.add(listener); } } batcher.setBatchSuccessListeners( Stream.of(batcher.getBatchSuccessListeners()) .filter(listener -> !(listener instanceof MyWriteBatchListener)) .toArray(WriteFailureListener[]::new) );
Alternative Interfaces
If your application is not working with large workloads or does not require an asynchronous interface, consider using the interfaces described in the following sections:
- Single Document Operations. Synchronous document operations on one document at a time. You can create, read, update and delete documents.
- Synchronous Multi-Document Operations. Synchronous document operations on multiple documents. You can create, read, update, and delete documents. You might find this interface simpler if you do not require asynchrony or the level of control provided by the Data Movement SDK.
If you want to move data into, out of, or between MarkLogic clusters using the command line, consider the mlcp tool. This tool provides many of the capabilities and performance characteristics of the Data Movement interfaces. For details, see the mlcp User Guide.