Matches for cat:guide (cat:guide/java) have been highlighted.


MarkLogic Server 11.0 Product DocumentationJava Application Developer's Guide — Chapter 3
Synchronous Multi-Document Operations
This chapter describes how to read and write multiple documents in a single request to MarkLogic Server using the Java Client API. You can operate on both document content and metadata. The interfaces described here are synchronous, meaning your application will block during the operation.
If you only need to work with one document at a time, you can use the simpler single document interfaces. For details, see Single Document Operations. If you have a potentially long running multi-document task, consider using the asynchronous interfaces described in Asynchronous Multi-Document Operations.
This chapter includes the following sections:
- Write Multiple Documents
- Read Multiple Documents by URI
- Read Multiple Documents Matching a Query
- Apply a Read Transformation
- Selecting a Batch Size
Write Multiple Documents
This section describes how to create or update content and/or metadata for multiple documents in a single request to MarkLogic Server. This section includes the following topics:
- Overview of Multi-Document Write
- Example: Loading Multiple Documents
- Understanding Metadata Scoping
- Understanding When Metadata is Preserved or Replaced
- Example: Controlling Metadata Through Defaults
- Example: Adding Documents to a Collection
- Example: Writing a Mixed Document Set
Overview of Multi-Document Write
You can perform a multi-document write by building up a DocumentWriteSet that describes the document content and metadata to write, and then passing it to a DocumentManager to execute the write operation.
For example, the following code snippet writes content for an XML document with URI doc1.xml and both content and metadata for a JSON document with URI doc2.json. For a complete example, see Example: Loading Multiple Documents.
import com.marklogic.client.document.DocumentManager;
import com.marklogic.client.document.DocumentWriteSet;
...
DocumentWriteSet batch = docMgr.newWriteSet();
batch.add("doc1.xml", doc1ContentHandle);
batch.add("doc2.json", doc2MetadataHandle, doc2ContentHandle);
docMgr.write(batch);A DocumentWriteSet represents a batch of document content and/or metadata to be written to the database in a single transaction. If any insertion or update in a write set fails, the entire batch fails. You should size each batch according to the guidelines described in Selecting a Batch Size.
A DocumentWriteSet has the following key features:
- Document content can be either heterogeneous or homogeneous, depending on the type of
DocumentManageryou use. For example, you can create or update any combination of XML, JSON, Text, and Binary documents in a single operation if you useGenericDocumentManager. - For each document, a batch can include just content, just metadata, or both. If you include only metadata for a document, then the document must already exist.
- You can create or update documents with the system default metadata, batch default metadata, or document-specific metadata. You can mix these metadata sources in the same operation. For details, see Understanding Metadata Scoping.
The write operation is carried out by a DocumentManager. If all documents in the write set are of the same type, then using a DocumentManager of the corresponding type has the following advantages:
- The database document type is implicitly set by the
DocumentManager. For example, anXMLDocumentManagersets the document type to XML for you and aJSONDocumentManagersets the document type to JSON for you. - You can use the
DocumentManagerto set batch-wide, type specific options. For example, you can useBinaryDocumentManager.setMetadataExtraction()to direct MarkLogic Server to extract metadata from each binary document and store it in the document properties.
If you create a heterogeneous write set that includes documents of more than one type, then you must use a GenericDocumentManager to perform the write. In this case, you must explicitly set the type of each document and you cannot use any type specific options, such as XML repair or Binary metadata extraction. For details, see Example: Writing a Mixed Document Set.
When you use bulk write, pre-existing document properties are preserved, but other categories of metadata are completely replaced. If you want to preserve pre-existing metadata, use a single document write. For details, see Understanding When Metadata is Preserved or Replaced.
You can apply a server-side write transformation to each document in a multi-document write. First, install your transform on MarkLogic Server, as described in Installing Transforms. Then, include a reference to the transform in your write call, similar to the following:
ServerTransform transform = new ServerTransform(TRANSFORM_NAME); docMgr.write(batch, transform);
Example: Loading Multiple Documents
This example provides a quick introduction to multi-document write. It creates two JSON documents in one transaction. The first document uses the system default metadata and the second document uses document-specific metadata.
Three items are added to the DocumentWriteSet for this operation: JSON content for a document with URI doc1.json, metadata for a document with URI doc2.json, and content for a JSON document with URI doc2.json. The core of the example is the following lines that build up a DocumentWriteSet and send it to MarkLogicServer for committing to the database:
// Create and populate the batch of docs to write JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); batch.add("doc1.json", doc1); batch.add("doc2.json", doc2Metadata, doc2); // Perform the write operation jdm.write(batch);
The full example function is shown below. This example uses StringHandle for the content, but you can use other handle types, such as JacksonHandle or FileHandle.
package examples; import com.marklogic.client.io.*; import com.marklogic.client.document.JSONDocumentManager; import com.marklogic.client.document.DocumentWriteSet; import com.marklogic.client.DatabaseClientFactory; import com.marklogic.client.DatabaseClientFactory.DigestAuthContext; import com.marklogic.client.DatabaseClient; public class Example implements ConnInfo { // replace with your MarkLogic Server connection information static String HOST = "localhost"; static int PORT = 8000; static String USER = "username"; static String PASSWORD = "password"; static DatabaseClient client = DatabaseClientFactory.newClient( HOST, PORT, new DigestAuthContext(USER, PASSWORD)); /// Basic example of writing 2 JSON documents. public static void example1() { // Create some example content and metadata StringHandle doc1 = new StringHandle( "{\"animal\": \"dog\"}").withFormat(Format.JSON); StringHandle doc2 = new StringHandle( "{\"animal\": \"cat\"}").withFormat(Format.JSON); DocumentMetadataHandle doc2Metadata = new DocumentMetadataHandle(); doc2Metadata.setQuality(2); // Create and populate the batch of docs to write JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); batch.add("doc1.json", doc1); batch.add("doc2.json", doc2Metadata, doc2); // Perform the write operation jdm.write(batch); } public static void main(String[] args) { example1(); } }
Understanding Metadata Scoping
This topic describes how metadata is selected for documents created or updated with a multi-document write.
For performance reasons, pre-existing metadata other than properties is completely replaced during a bulk write operation, either with values supplied in the DocumentWriteSet or with system defaults.
Metadata in a bulk write can be drawn from 3 possible sources, as shown in the table below. The table lists the metadata sources from highest to lowest precedence, so a source supercedes those below it if both are present.
The metadata associated with a document is determined when you add the document to a DocumentWriteSet. This means that when you add default metadata, it only applies to documents subsequently added to the batch, not to documents already in the batch. Default metadata applies from the point it is added to the batch until a subsequent call to DocumentWriteSet.addDefaultMetadata(). Passing null to addDefaultMetadata() causes subsequent documents to revert to using system default metadata rather than batch default metadata.
The following code snippet illustrates the metadata interactions:
DatabaseClient client = ...; JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); // using system default metadata batch.add("doc1.json", doc1); // use system default metadata // using batch default metadata batch.addDefaultMetadata(defaultMetadata1); batch.add("doc2.json", doc2); // use batch default metadata batch.add("doc3.json", docSpecificMetadata, doc3); batch.add("doc4.json", doc4); // use batch default metadata // replace batch default metadata with new metadata batch.addDefaultMetadata(defaultMetadata2); batch.add("doc5.json", doc5); // use batch default metadata // revert to system default metadata batch.addDefaultMetadata(null); batch.add("doc6.json", doc6); // use system default metadata // Execute the write operation jdm.write(batch);
For a complete example, see Example: Controlling Metadata Through Defaults.
The following rules determine what metadata applies during document creation.
- Document-specific metadata always takes precedence over other metadata sources. Document-specific metadata is not merged with default metadata.
- System default metadata is used when there is no batch default metadata and no documents-specific metadata for a given document.
- Each time you add default metadata to a batch, the new default completely replaces any old default.
- When setting metadata for a document, any missing metadata category is either set to the system default metadata value or left unchanged, depending upon whether or not the batch includes a content update for the document. For details, see Understanding When Metadata is Preserved or Replaced.
For performance reasons, no merging of document-specific or batch default metadata occurs. For example, if a document-specific metadata part contains only a collections setting, it inherits quality, permissions and properties from the system default metadata, not from any preceding batch default metadata.
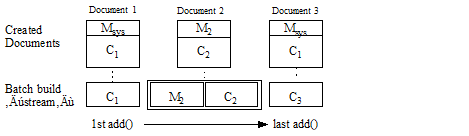
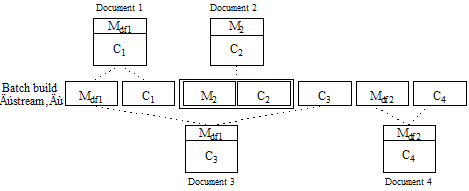
The following examples illustrate application of these rules. In these examples, Cn represents a content part for the Nth document, Mn represents document-specific metadata for the Nth document, Mdfn represents the Nth occurrence of batch default metadata, and Msys is the system default metadata. The batch build stream represents the order in which content and metadata is added to the batch.
The following input creates 3 documents. Documents 1 and Document 3 use system default metadata. Document 2 uses document-specific metadata.
The following input creates four documents, using a combination of batch default metadata and document-specific metadata. Document 1, Document 3, and Document 4 use batch default metadata. Document 2 uses document-specific metadata. Document 1 and Document 3 use the first block of batch default metadata, Mdf1. After Document 3 is added to the batch, Mdf2 replaces Mdf1 as the default metadata, so Document 4 uses the metadata in Mdf2.
Understanding When Metadata is Preserved or Replaced
This topic discusses when a multi-document write preserves or replaces pre-existing metadata. You can skip this section if your multi-document write operations only create new documents or you do not need to preserve pre-existing metadata such as permissions, document quality, collections, and properties.
When there is no batch default metadata and no document-specific metadata, all metadata categories other than properties are set to the system default values. Properties are unchanged.
In all other cases, either batch default metadata or document-specific metadata is used when creating a document, as described in Understanding Metadata Scoping.
When you update both content and metadata for a document in the same multi-document write operation, the following rules apply, whether applying batch default metadata or document-specific metadata:
- The metadata in scope is determined as described in Understanding Metadata Scoping.
- Any metadata category that has a value in the in-scope metadata completely replaces that category.
- Any metadata category other than properties that is missing or empty in the in-scope metadata is completely replaced by the system default value.
- If the in-scope metadata does not include properties, then existing properties are preserved.
- If the in-scope metadata does not include collections, then collections are reset to the default. There is no system default for collections, so this results in a document being removed from all collections if no default collections are specified for the user role performing the update.
When your write set includes metadata for a document, but no content, you update only the metadata for a document. In this case, the following rules apply:
- Any metadata category that has a value in the document-specific metadata completely replaces that category.
- Any metadata category that is missing or empty in the document-specific metadata is preserved.
The table below shows how pre-existing metadata changes if a multi-document write updates just the content, just the collections metadata (via document-specific metadata), or both content and collections metadata (via batch default metadata or document-specific metadata).
The results are similar if the metadata update modifies other metadata categories.
Example: Controlling Metadata Through Defaults
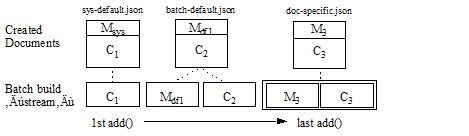
This example uses document quality to illustrate how default metadata affects the documents you create. The document quality setting used in this example result in creation of the following documents:
sys-default.jsonwith document quality 0, from the system default metadatabatch-default.jsonwith document quality 2, from Mdf1doc-specific.jsonwith document quality 1, from M3
The following graphic illustrates the construction of the batch and the documents created from it. In the picture, Mn represents metadata, Cn represents content. Note that the metadata is not literally embedded in the created documents; content and metadata are merely grouped here for illustrative purposes.
The following code snippet is the core of the example, building up a batch of document updates and inserting them into the database:
// Create and build up the batch JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); batch.add("sys-default.json", content1); batch.addDefault( defaultMetadata); batch.add("batch-default.json", content2); batch.add("doc-specific.json", docSpecificMetadata, content3); // Create the documents jdm.write(batch);
The full example function is shown below. This example uses StringHandle for the content, but you can use other handle types, such as JacksonHandle or FileHandle.
package examples; import com.marklogic.client.io.*; import com.marklogic.client.document.JSONDocumentManager; import com.marklogic.client.document.DocumentWriteSet; import com.marklogic.client.DatabaseClientFactory; import com.marklogic.client.DatabaseClient; public class Example { // replace with your MarkLogic Server connection information static String HOST = "localhost"; static int PORT = 8000; static String USER = "user"; static String PASSWORD = "password"; static DatabaseClient client = DatabaseClientFactory.newClient( HOST, PORT, new DigestAuthContext(USER, PASSWORD)); static void example2() { // Synthesize input content StringHandle content1 = new StringHandle( "{\"number\": 1}").withFormat(Format.JSON); StringHandle content2 = new StringHandle( "{\"number\": 2}").withFormat(Format.JSON); StringHandle content3 = new StringHandle( "{\"number\": 3}").withFormat(Format.JSON); // Synthesize input metadata DocumentMetadataHandle defaultMetadata = new DocumentMetadataHandle().withQuality(1); DocumentMetadataHandle docSpecificMetadata = new DocumentMetadataHandle().withQuality(2); // Create and build up the batch JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); batch.add("sys-default.json", content1); batch.addDefault( defaultMetadata); batch.add("batch-default.json", content2); batch.add("doc-specific.json", docSpecificMetadata, content3); // Create the documents jdm.write(batch); // Verify results System.out.println( "sys-default.json quality: Expected=0, Actual=" + jdm.readMetadata("sys-default.json", new DocumentMetadataHandle()).getQuality() ); System.out.println("batch-default.json quality: Expected=" + defaultMetadata.getQuality() + ", Actual=" + jdm.readMetadata("batch-default.json", new DocumentMetadataHandle()).getQuality() ); System.out.println("doc-specific.json quality: Expected=" + docSpecificMetadata.getQuality() + ", Actual=" + jdm.readMetadata("batch-default.json", new DocumentMetadataHandle()).getQuality() ); } public static void main(String[] args) { example2(); } }
Example: Adding Documents to a Collection
This example demonstrates using batch default metadata to add all documents to the same collection during a multi-document write. For general information about working with metadata, see Reading, Modifying, and Writing Metadata.
Since the metadata in this example request only includes settings for collections metadata, other metadata categories such as permissions and quality use the system default settings. You can add individual documents to a different collection using document-specific metadata or by including additional batch default metadata that uses a different collection; see Example: Controlling Metadata Through Defaults.
The code snippet below inserts 2 JSON documents into the database with a collection named April 2014.
// Synthesize input metadata DocumentMetadataHandle defaultMetadata = new DocumentMetadataHandle().withCollections("April 2014"); // Create and build up the batch JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); batch.addDefault(defaultMetadata); batch.add("coll-doc1.json", content1); batch.add("coll-doc2.json", content2); jdm.write(batch);
The full example is shown below. This example uses StringHandle for the content, but you can use other handle types, such as JacksonHandle, XMLHandle, or FileHandle.
package examples; import com.marklogic.client.io.*; import com.marklogic.client.query.MatchDocumentSummary; import com.marklogic.client.query.QueryManager; import com.marklogic.client.query.StructuredQueryBuilder; import com.marklogic.client.document.JSONDocumentManager; import com.marklogic.client.document.DocumentWriteSet; import com.marklogic.client.DatabaseClientFactory; import com.marklogic.client.DatabaseClient; public class Example { // replace with your MarkLogic Server connection information static String HOST = "localhost"; static int PORT = 8000; static String USER = "username"; static String PASSWORD = "password"; static DatabaseClient client = DatabaseClientFactory.newClient( HOST, PORT, new DigestAuthContext(USER, PASSWORD)); /// Inserting all documents in a batch into the same collection public static void example3() { // Synthesize input content StringHandle content1 = new StringHandle( "{\"number\": 1}").withFormat(Format.JSON); StringHandle content2 = new StringHandle( "{\"number\": 2}").withFormat(Format.JSON); // Synthesize input metadata DocumentMetadataHandle defaultMetadata = new DocumentMetadataHandle().withCollections("April 2014"); // Create and build up the batch JSONDocumentManager jdm = client.newJSONDocumentManager(); DocumentWriteSet batch = jdm.newWriteSet(); batch.addDefault(defaultMetadata); batch.add("coll-doc1.json", content1); batch.add("coll-doc2.json", content2); jdm.write(batch); // Verify results by finding all documents in the collection QueryManager qm = client.newQueryManager(); StructuredQueryBuilder builder = qm.newStructuredQueryBuilder(); SearchHandle results = qm.search( builder.collection("April 2014"), new SearchHandle()); for (MatchDocumentSummary summary : results.getMatchResults()) { System.out.println(summary.getUri()); } } public static void main(String[] args) { example3(); } }
Example: Writing a Mixed Document Set
This example uses GenericDocumentManager to create a batch that contains documents with a mixture of document types in a single operation. The batch contains a JSON document, an XML document, and a binary document. The following code snippet demonstrates construction of a mixed document batch:
GenericDocumentManager gdm = client.newDocumentManager(); DocumentWriteSet batch = gdm.newWriteSet(); batch.add("doc1.json", jsonContent); batch.add("doc2.xml", xmlContent); batch.add("doc3.jpg", binaryContent); gdm.write(batch);
When you use GenericDocumentManager, you must either use handles that imply a specific document or content type, or explicitly set it. In this example, the JSON and XML contents are provided using a StringHandle, and the document type is specified using withFormat().The binary content is read from a file on the local filesystem, using FileHandle.withMimeType() to explicitly specify the a MIME type of image/jpeg, which implies a binary document.
Document type specific options such as XML repair and binary document metadata extract cannot be performed using GenericDocumentManager. You must use a document type specific document manager and a homogeneous batch to use these features.
The full example, including setting of the document/MIME types, is shown below. To run this example in your environment, you need a binary file to subsitute for /some/jpeg/file.jpg. If your file is not a JPEG image, change the MIME type in the call to FileHandle.withMimeType().
package examples; import java.io.File; import com.marklogic.client.io.*; import com.marklogic.client.document.GenericDocumentManager; import com.marklogic.client.document.DocumentWriteSet; import com.marklogic.client.DatabaseClientFactory; import com.marklogic.client.DatabaseClient; public class standalone { // replace with your MarkLogic Server connection information static String HOST = "localhost"; static int PORT = 8000; static String USER = "user"; static String PASSWORD = "password"; static DatabaseClient client = DatabaseClientFactory.newClient( HOST, PORT, new DigestAuthContext(USER, PASSWORD)); /// Inserting documents with different document types static void example4() { // Synthesize input content StringHandle jsonContent = new StringHandle( "{\"key\": \"value\"}").withFormat(Format.JSON); StringHandle xmlContent = new StringHandle( "<data>some xml content</data>").withFormat(Format.XML); String filename = new String("/some/jpeg/file.jpg"); FileHandle binaryContent = new FileHandle().with(new File(filename)).withMimetype("image/jpeg"); // Create and build up the batch GenericDocumentManager gdm = client.newDocumentManager(); DocumentWriteSet batch = gdm.newWriteSet(); batch.add("doc1.json", jsonContent); batch.add("doc2.xml", xmlContent); batch.add("doc3.jpg", binaryContent); gdm.write(batch); // Verify results System.out.println("doc1.json exists as: " + gdm.exists("doc1.json").getFormat().toString()); System.out.println("doc2.xml exists as: " + gdm.exists("doc2.xml").getFormat().toString()); System.out.println("doc3.jpg exists as: " + gdm.exists("doc3.jpg").getFormat().toString()); } public static void main(String[] args) { example4(); } }
Read Multiple Documents by URI
You can retrieve multiple documents by URI in a single request by passing multiple URIs to DocumentManager.read(). For example, the following code snippet reads 3 documents from the database:
DocumentPage documents = docMgr.read("doc1.json", "doc2.json", "doc3.json"); while (documents.hasNext()) { DocumentRecord document = documents.next(); // do something with the contents }
The multi-document read operation returns a DocumentRecord for each matched URI. Use the DocumentRecord to access content and/or metadata about each document. By default, only content is available. To retrieve metadata, use DocumentManager.setMetadataCategories(). For example, the following code snippet retrieves both content and document quality for three documents:
DatabaseClient client = DatabaseClientFactory.newClient(...); JSONDocumentManager jdm = client.newJSONDocumentManager(); jdm.setMetadataCategories(Metadata.QUALITY); DocumentPage documents = jdm.read("doc1.json", "doc2.json", "doc3.json"); while (documents.hasNext()) { DocumentRecord document = documents.next(); DocumentMetadataHandle metadata = document.getMetadata(new DocumentMetadataHandle()); System.out.println( document.getUri() + ": " + metadata.getQuality()); // do something with the content }
For more information about metadata categories, see Reading, Modifying, and Writing Metadata.
Multi-document read also supports server side transformations and transaction controls. For more details on these features, see Apply a Read Transformation and Multi-Statement Transactions.
Applying a transform creates an additional in-memory copy of each document on the server, rather than streaming each document directly out of the database, so memory consumption is higher.
Read Multiple Documents Matching a Query
Use com.marklogic.client.document.DocumentManager.search() to retrieve all documents that match a query. This section covers the following topics:
- Overview of Multi-Document Read by Query
- Example: Read Documents Matching a Query
- Add Query Options to a Search
- Return Search Results
- Read Documents Incrementally
- Extracting a Portion of Each Matching Document
Overview of Multi-Document Read by Query
To retrieve all documents from the database that match a query, use DocumentManager.search().
The search methods of DocumentManager differ from QueryManager.search() methods in that DocumentManager search returns document contents while QueryManager search returns search results and facets. Though you can retrieve search results along with contents using DocumentManager.search(), and you can retrieve document contents using QueryManager.search(), the interfaces are optimized for different use cases.
You can pass a string, structured, or combined query or a QBE to DocumentManager.write(). For example, the following code snippet reads all documents that contain the phrase bird:
JSONDocumentManager jdm = client.newJSONDocumentManager(); QueryManager qm = client.newQueryManager(); StringQueryDefinition query = qm.newStringDefinition().withCriteria("bird"); DocumentPage documents = jdm.search(query, 1); while (documents.hasNext()) { DocumentRecord document = documents.next(); // do something with the contents }
Documents are returned as a DocumentPage that you can use to iterate over returned content and metadata. You might have to call DocumentManager.search() multiple times to retrieve all matching documents. The number of documents per DocumentPage is controlled by DocumentManager.setPageLength(). For details, see Read Documents Incrementally.
To return search results along with matching documents, include a SearchHandle in your call to DocumentManager.search(). For details, see Return Search Results. For example:
docMgr.search(query, 1, new SearchHandle());
You can apply server-side content transformations to matching documents by configuring a ServerTransform on the QueryDefinition. For details, see Apply a Read Transformation.
Example: Read Documents Matching a Query
This example demonstrates using a query to retrieve documents from the database using DocumentManager.search(). Though you can use any query type, this example focuses on Query By Example.You should be familiar with QBE basics. For details, see Prototype a Query Using Query By Example.
The following QBE matches documents with an XML element or JSON property named kind that has a of value bird:
| Format | Query |
|---|---|
| XML | <q:qbe xmlns:q="http://marklogic.com/appservices/querybyexample"> <q:query> <kind>bird</kind> </q:query> </q:qbe> |
| JSON | { "$query": { "kind": "bird" } } |
The following example code uses the above query to retrieve matching documents. Only document content is returned because no metadata categories are set on the DocumentManager.
The number of documents matching the input query is available using DocumentPage.getTotalResults(). This number is equivalent to @total on a search response and is only an estimate. The document URI, document type, and contents are available on each DocumentRecord in the DocumentPage.
package examples; import com.marklogic.client.DatabaseClient; import com.marklogic.client.DatabaseClientFactory; import com.marklogic.client.document.DocumentPage; import com.marklogic.client.document.DocumentRecord; import com.marklogic.client.document.JSONDocumentManager; import com.marklogic.client.io.Format; import com.marklogic.client.io.StringHandle; import com.marklogic.client.query.QueryManager; import com.marklogic.client.query.RawQueryByExampleDefinition; public class QueryExample { // replace with your MarkLogic Server connection information static String HOST = "localhost"; static int PORT = 8000; static String USER = "user"; static String PASSWORD = "password"; static DatabaseClient client = DatabaseClientFactory.newClient( HOST, PORT, new DigestAuthContext(USER, PASSWORD)); public static void qbeExample() { JSONDocumentManager jdm = client.newJSONDocumentManager(); QueryManager qm = client.newQueryManager(); // Build query String queryAsString = "{ \"$query\": { \"kind\": \"bird\" }}"; StringHandle handle = new StringHandle(); handle.withFormat(Format.JSON).set(queryAsString); RawQueryByExampleDefinition query = qm.newRawQueryByExampleDefinition(handle); // Perform the multi-document read and process results DocumentPage documents = jdm.search(query, 1); System.out.println("Total matching documents: " + documents.getTotalSize()); for (DocumentRecord document: documents) { System.out.println(document.getUri()); // Do something with the content using document.getContent() } } public static void main(String[] args) { qbeExample(); client.release(); } }
To perform the equivalent operation using an XML QBE, use an XMLDocumentManager. Note that the format of a QBE (XML or JSON) can affect the kinds of documents that match the query. For details, see Scoping a Search by Document Type in the Search Developer's Guide.
To use a string, structured, or combined query instead of a QBE, change the QueryDefinition. The search operation and results processing are unaffected by the type of query. For more details on query construction, see Searching.
For example, to use a string query to find all documents containing the phrase bird, replace the query building section of the above example with the following:
StringQueryDefinition query = qm.newStringDefinition().withCriteria("bird");
To return metadata in addition to content, set one or more metadata categories on the DocumentManager prior to the search. Use DocumentPage.getMetadata() to access it. For example, the following changes to the above example returns the quality of each document, along with the contents.
jdm.setMetadataCategories(Metadata.QUALITY); DocumentPage documents = jdm.search(query, 1); System.out.println("Total matching documents: " + documents.getTotalSize()); for (DocumentRecord document: documents) { System.out.println(document.getUri() + "quality: " + document.getMetadata( new DocumentMetadataHandle()).getQuality()); // Do something with the content using document.getContent() }
Use QueryDefinition.setOptionsName() to include persistent query options in your search; for details, see Add Query Options to a Search. For example, to apply persistent query options previously installed under the name myOptions, pass the options name during query creation:
RawQueryByExampleDefinition query = qm.newRawQueryByExampleDefinition(handle, "myOptions");
Add Query Options to a Search
You can customize your multi-document read using query options in the same way you use them with QueryManager.search():
- Pre-install persistent query options and configure them by name into your
QueryDefinition. - Embed dynamic query options into a combined query or QBE. Note that QBE supports only a limited set of query options.
For example, if you previously installed persistent query options under the name myOptions, then you can use them in a multi-document read as follows:
JSONDocumentManager jdm = client.newJSONDocumentManager(); QueryManager qm = client.newQueryManager(); StringQueryDefinition query = qm.newStringDefinition("myOptions").withCriteria("bird"); DocumentPage documents = jdm.search(query, 1);
For details, see Query Options and Apply Dynamic Query Options to Document Searches.
Return Search Results
When you use QueryManager.search() to find matching documents, you receive a search response that can contain snippets, facets, and other match details. This information is not returned by default with DocumentManager.search(), but you can request it by including a SearchHandle in your call. When you include a SearchHandle, you receive both a search response and the matching documents.
For example, the following code snippet requests search results in addition the content of matching documents.
SearchHandle results = new SearchHandle().withFormat(Format.XML); DocumentPage documents = jdm.search(query, 1, results); for (MatchDocumentSummary match : results.getMatchResults()) { // process snippets, facets, and other result info }
Read Documents Incrementally
When you read documents using DocumentManager.search(), the page size defined on the DocumentManager determines how many documents are returned. You can use this feature, plus the start parameter of DocumentManager.search() to incrementally read matching documents. The defualt page size is 10 documents. Incrementally reading batches of documents limits resource consumption on both the client and server.
For example, the following function sets the page size and reads all matching documents in batches of no more than 5 documents.
public static void pagingExample() { JSONDocumentManager jdm = client.newJSONDocumentManager(); QueryManager qm = client.newQueryManager(); StringQueryDefinition query = qm.newStringDefinition().withCriteria("bird"); // Retrieve 5 documents per read jdm.setPageLength(5); // Fetch and process documents incrementally int start = 1; DocumentPage documents = null; while (start == 1 || documents.hasNextPage()) { // Read and process one batch of matching documents documents = jdm.search(query, start); for (DocumentRecord document : documents) { // process the content } // advance starting position to the next page of results start += documents.getPageSize(); } }
Extracting a Portion of Each Matching Document
This section illustrates how to use the extract-document-data query option with the Java Client API to return selected portions of each matching document instead of the whole document. For details about the option components, see Extracting a Portion of Matching Documents in the Search Developer's Guide.
The following example code snippet uses a combined query to specify that the search should only return the portions of matching documents that match the path /parent/body/target.
String rawQuery = "<search xmlns=\"http://marklogic.com/appservices/search\">" + " <qtext>content</qtext>" + " <options xmlns=\"http://marklogic.com/appservices/search\">" + " <extract-document-data selected=\"include\">" + " <extract-path>/parent/body/target</extract-path>" + " </extract-document-data>" + " <return-results>false</return-results>" + " </options>" + "</search>"; StringHandle qh = new StringHandle(rawQuery).withFormat(Format.XML); GenericDocumentManager gdm = client.newDocumentManager(); QueryManager qm = client.newQueryManager(); RawCombinedQueryDefinition query = qm.newRawCombinedQueryDefinition(qh); DocumentPage documents = gdm.search(query, 1); System.out.println("Total matching documents: " + documents.getTotalSize()); for (DocumentRecord document: documents) { System.out.println(document.getUri()); // Do something with the content using document.getContent() }
You can also use a JSON raw query to search the portions of matching documents that match the path /parent/body/target.
portions of matching documents that match the path /parent/body/target.
String rawQuery =
"{\"options\": {" +
"\"extract-document-data\": {" +
"\"selected\": \"include\"," +
"\"extract-path\": \"/parent/body/target\" } },
\"qtext\" : \"content\" }";
StringHandle qh = new StringHandle(rawQuery).withFormat(Format.JSON);
GenericDocumentManager gdm = client.newDocumentManager();
QueryManager qm = client.newQueryManager();
RawCombinedQueryDefinition query = qm.newRawCombinedQueryDefinition(qh);
DocumentPage documents = gdm.search(query, 1);
System.out.println("Total matching documents: " + documents.getTotalSize());
for (DocumentRecord document: documents) {
System.out.println(document.getUri());
// Do something with the content using document.getContent()
If one of the matching documents looked like the following:
{"parent": { "a": "foo", "body": { "target":"content" }, "b": "bar"} }
Then the search returns the following sparse projection for this document. There will be one item in the extracted array (or one extracted element in XML) for each projection in a given context.
{ "context":"fn:doc(\"/extract/doc2.json\")", "extracted":[{"target":"content"}] }
If you set the selected attribute to all, include-with-ancestors, or exclude, then the resulting document just contains the extracted content. For example, if you set selected to include-with-ancestors in the previous example, then the projected document conains the following. Notice that there are no context or extracted wrappers.
{"parent":{"body":{"target":"content1"}}}
You can also use extract-document-data to embed sparse projections in the search result summary returned by QueryManager.search. For details, see Extracting a Portion of Matching Documents.
Apply a Read Transformation
When you perform a multi-document read using DocumentManager.read() or DocumentManager.search(), you can apply a server-side document read transformation by configuring a ServerTransform into your DocumentManager.
The transform function is called on the returned documents, but not on metadata. If you include search results when reading documents with DocumentManager.search(), the transform function is called on both the returned documents and the search response, so the transform must be prepared to handle multiple kinds of input.
For more details, see Content Transformations.
The following example code demonstrates applying a read transform when reading documents that match a query.
ServerTransform transform = new ServerTransform(TRANSFORM_NAME); docMgr.setReadTransform(transform); docMgr.search(query, start);
Applying a transform creates an additional in-memory copy of each document, rather than streaming each document directly out of the database, so memory consumption is higher.
Selecting a Batch Size
The best batch size for reading and writing multiple documents in a single request depends on the nature of your data. A batch size of 100 is a good starting place for most document collections. Experiment with different batch sizes of data characteristic to your application until you find one that fits within the limits of your MarkLogic Server installation and acceptable request timeouts.
If you need to ingest or retrieve a very large number of documents, you can also consider MarkLogic Content Pump (mlcp), a command line tool for loading and retrieving documents from a MarkLogic database. For details, see Loading Content Using MarkLogic Content Pump in the Loading Content Into MarkLogic Server Guide.
For additional tuning tips, see the Query Performance and Tuning Guide.