
MarkLogic Server 11.0 Product DocumentationJava Application Developer's Guide — Chapter 16
Creating Data Services Using the MarkLogic Java Development Tools
Data Services is a convenient way to integrate MarkLogic into an existing enterprise environment. A data service is a fixed interface over the data managed in MarkLogic expressed in terms of the consuming application. Data services can run queries ("Find eligible insurance plans for an applicant"), updates ("Flag this claim as fraudulent"), or both ("Adjust the rates of plans that haven't made claims in the last year"). A MarkLogic cluster can support dozens or even hundreds of different data services operating over the data and metadata managed in a data hub.
- Advantages of Data Services
- Where Data Service Fit Within the Enterprise Stack
- How it Works
- Prerequisites
- Relation to the Java Client API
- Creating a Proxy Service
- Setting Up an App Server for the Proxy Service
- Creating the Proxy Service Directory
- Declaring the Proxy Service
- Declaring the Endpoint
- Providing the Module for an Endpoint Proxy
- Deploying a Proxy Service
- Generating the Proxy Service Class
- Using a Proxy Service Class
- Publishing Your Data Service for Use in Other Projects
A data service is different from a generic query interface, like JDBC or ODBC, which typically operates at the physical layer of the database. Architecturally, a data service is more like a remote procedure call or a stored procedure. The data service allows the service developer to obscure the physical layout of the data and constrain or enhance queries and updates with business logic.
MarkLogic provides a rich scripting environment as part of the DBMS. The developer implements data services using either JavaScript or XQuery. MarkLogic supports JavaScript and XQuery runtimes. MarkLogic optimizes this code to run close to the data, minimizing data transfer and leveraging cluster-wide indexes and caches.
Advantages of Data Services
- Avoid unnecessary round-trips by encapsulating the data logic, ensuring that service implementations run close to the data.
- Reduce custom plumbing code by handling network and data marshalling transparently.
- Reduce the potential for API drift as requirements and implementations change by enforcing strongly typed interfaces.
The Java Client API supports physical operations on the database. In particular, the Java Client API provides DocumentManager (and its derivations) and QueryManager to write, read, or query for documents and their metadata at the Uris identifying the documents in the database. Where a transaction must span multiple requests, the client uses a physical Transaction object.
Proxy services complement these physical operations with logical operations. The Java middle-tier invokes endpoints, passing and receiving values. The endpoint is entirely responsible for the implementation of the operation against the database - including the reading and writing of values. Where an operation must interleave middle-tier and e-node tasks, the client uses a logical session represented by a SessionState object (as described later).
The Java Client API and proxy services connect with the database in the same way. Both use the DatabaseClientFactory class to instantiate a DatabaseClient object for use in requests.
A REST server used for the Java Client API can coexist with proxy services, provided the user abides by the following conditions:
- Do not try to use proxy services on port 8000.
- You must avoid filename collisions by using a different directory than the one used by the REST API.
One way to avoid such collisions would be to establish a convention such as using a "/ds" directory for all data services.
Note: The middle-tier client cannot specify the database explicitly when creating a DatabaseClient but, instead, must use the default database associated with the App Server.
Where Data Service Fit Within the Enterprise Stack
The diagram below illustrates how MarkLogic Data Services fits within the enterprise development stack.
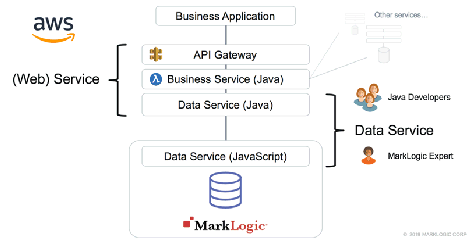
Enterprise middle-tier business logic generally integrates many services: data services from a MarkLogic cluster as well as services from other providers. This service orchestration and business logic happen at a layer above the data infrastructure, outside of a particular service provider. The flexibility to mix and match services and to decouple providers and consumers is one of the benefits of a service-oriented architecture:
How it Works
You declare a function signature for each endpoint that implements a data service.
From a set of such declarations, the development tools generate a Java proxy service class that encapsulates the execution of the endpoints including the marshalling and transport of the request and response data. The middle-tier business logic can then call the methods of the generated class.
A MarkLogic data service consists of three main components:
- Endpoint Declaration: This is a JSON document used to specify the name of the service as well as the names and data types of the inputs and outputs.
- Endpoint Proxy: Code that exposes the service definition in Java, automatically invoking the services remotely against a MarkLogic cluster for the caller.
- Endpoint Module: This is the implementation of a data service in MarkLogic as a JavaScript or XQuery module.
By declaring the data tier functions needed by the middle-tier business logic, the endpoint declaration establishes a division of responsibility between the Java middle-tier developer and the data service developer. The endpoint declaration acts as a contract for collaboration between the two roles.
It is the responsibility of the end point service developer to limit access to the Data Services assets by adding the necessary security asserts (using xdmp.securityAssert or xdmp:security-assert functions ) to test for privileges.
Prerequisites
To create a proxy service, you need a Java JDK environment with Gradle and the following MarkLogic software components:
- Current version of MarkLogic Server
- Current version of MarkLogic Client Java API
- Current version of ml-gradle
The MarkLogic Java development tools are available as a Gradle plugin.
This document assumes that you are familiar with Java and Gradle.
If you are unfamiliar with Gradle, the ml-gradle project lists some resources for getting started:
Installing and learning Gradle
Typically, you create one Gradle project directory for all of the work on proxy services for one content database.
Relation to the Java Client API
The MarkLogic Java Client API includes development tooling and runtime proxies so that a Java application can access custom data services in a MarkLogic cluster. The Java application calls strongly typed services running in the databases as if they were "out of the box" Java methods. The API handles the underlying network protocol and data marshalling.
Creating a Proxy Service
From the proxy service source files, you generate Java methods that call endpoint modules deployed to the modules database:
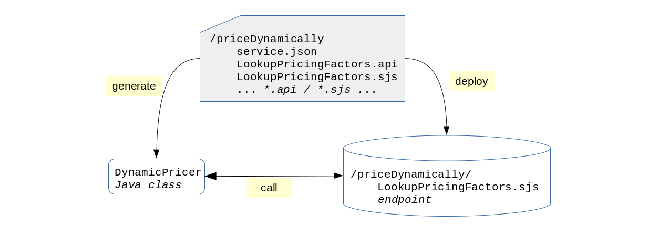
The development process consists of the following steps:
- Set up a MarkLogic App Server
- Create a proxy service directory within the Gradle project directory
- Create a file to declare the service
- Create files to declare one or more endpoint proxies for the service
- Implement the module for each endpoint proxy
- Deploy the proxy service directory to the modules database of the App Server
- Generate the Java Class from the proxy service declaration.
Setting Up an App Server for the Proxy Service
Typically, you set up a single App Server for all of the proxy services for a content database.
The App Server configuration must have the following characteristics:
You cannot use the following App Servers, created by default when you install MarkLogic:
- The REST/HTTP/XDBC App Server on port 8000
- The Admin API App Server on port 8001
- The REST Management API App Server on port 8002
As noted above, you are also able to use a REST server (that is, an App Server created for the Client REST API).
Data services can reside on REST and non-REST App Servers.
To make creation and configuration of the App Server and its modules database, you should manage a repeatable operation in a version control system. You can also put resources in the Gradle project directory and use ml-gradle to operate on those resources.
See Getting started for a step-by-step guide to this Gradle procedure.
As an easy expedient when learning about MarkLogic, you can instead configure the App Server and modules database manually. As a long-term practice, however, we recommend a repeatable approach using Gradle.
Creating the Proxy Service Directory
For each proxy service, you create a separate subdirectory under the Gradle project directory.
Each proxy service directory holds all of the resources required to support the proxy service, including:
- The service declaration
- The endpoint proxy declarations
- The module called by each endpoint proxy
- Any server-side libraries to support the endpoint modules
For easier deployment to the modules database using ml-gradle, you should create the proxy service directory under the src/main/ml-modules/root project subdirectory. If you are working under a MarkLogic ReST server application, you should use the following proxy service directory: src/main/ml-modules/root/ds.
For instance, a project might choose to provide the priceDynamically service in the following proxy service directory:
src/main/ml-modules/root/inventory/priceDynamically
Declaring the Proxy Service
The proxy service directory must contain exactly one service declaration file. The service declaration file must have the name service.json
The service declaration consists of a JSON object with the following properties:
Service Declaration File PropertiesThe following example declares the /inventory/priceDynamically/ directory as the address of the endpoints in the modules database and declares com.some.business.inventory.DynamicPricer as the generated Java class:
{ "endpointDirectory" : "/inventory/priceDynamically/", "$javaClass" : "com.some.business.inventory.DynamicPricer" }
Conventionally, the value of the endpointDirectory property should be the same as the path of the proxy service directory under the special ml-gradle src/main/ml-modules/root directory (so, the service directory for this service.json file would conventionally be src/main/ml-modules/root/inventory/priceDynamically).
The endpoint directory value should include the leading / and should resemble a Linux path.
After declaring the service, you populate it with endpoint proxy declarations
Declaring the Endpoint
The name, parameters, and return value for each endpoint is declared in a file with the .api extension in the service directory. The file contains a JSON data structure with the following properties:
Endpoint PropertiesThe endpoint declaration is used both to generate a method in a Java class to call on the middle-tier and to unmarshal the request and marshal the response when the App Server executes the endpoint module.
The .api file for proxy endpoint must be loaded into the modules database with the endpoint module.
The following sections provide more detail about the params and return declarations
Structure of a Parameter Definition
A parameter definition in the params property is an array with the following properties:
Parameter Definitions| Property | Declares |
|---|---|
| name | The name of the parameter |
| desc | Optional; a description of the parameter to include in JavaDoc. |
| datatype | The datatype of the parameter (see Server Data Types for Values). |
| nullable | Optional; whether the parameter can be null (defaulting to false). |
| multiple | Optional; whether the parameter can have more than one value (defaulting to false). |
Structure of the Return Type Definition
The return property of an endpoint declaration is an object with the following properties:
Return Type Definitions| Property | Declares |
|---|---|
| desc | Optional; a description of the return to include in JavaDoc. |
| datatype | The datatype of the return (see Server Data Types for Values). |
| nullable | Optional; whether the return can be null (defaulting to false). |
| multiple | Optional; whether the return can have more than one value (defaulting to false). |
Example of an Endpoint Proxy
The following example declares that the lookupPricingFactors endpoint has two required parameters as well as a required return value:
{ "functionName" : "lookupPricingFactors", "params" : [ { "name" : "productCode", "datatype" : "string" }, { "name" : "customerId", "datatype" : "unsignedLong" } ], "return" : { "datatype" : "jsonDocument" }}
Server Data Types for Values
You can specify atomic or node server data types for parameters and return values:
Server Data TypesThe data types with direct equivalents in the Java language atomics are represented with those Java classes by default. These data types include boolean, double, float, int, long, string, unsignedInt, and unsignedLong. For instance, a Java Integer represents an int. Likewise, the unsigned methods of the Java Integer and Long classes can manipulate the unsignedInt and unsignedLong types.
By default, a Java String represents the other atomic types (including date, dateTime, and dayTimeDuration, decimal and time).
Other server atomic data types can be passed as a string and cast using the appropriate constructor on the server.
A binaryDocument value is represented as an InputStream by default. All other node data types are represented as a Reader by default.
The array and object data types differ from the jsonDocument data type in not having a document node at the root, which can provide a more natural and efficient JSON value for manipulating in SJS (Server-Side JavaScript).
Mapping Values to Alternative Java Classes
Instead of the default Java representation, an alternative Java class may represent some server data types. For example, a String can represent a date by default, but you can choose to use java.time.LocalDate instead.
To specify an alternative Java class, supply the fully qualified class name in the $javaClass property of a parameter or return type. You must still specify the server data type in the datatype property.
The following table lists server data types with their available alternative representations:
The following example represents the occurred date parameter as a Java LocalDate and represents the returned JSON document as a Jackson JsonNode.
{ "functionName" : "produceReport", "params":[ { "name":"id", "datatype":"int" }, { "name":"occurred", "datatype":"date", "$javaClass":"java.time.LocalDate" } ], "return" : { "datatype":"jsonDocument", "$javaClass":"com.fasterxml.jackson.databind.JsonNode"} } }
Calling Endpoints in a Session
Ordinarily, the database server does not keep any state associated with a call to an endpoint (with the obvious but important exception of documents persisted in the database). When the middle-tier sends all of the input needed for a data tier operation, the operation can be completed in a single request. This approach typically maximizes performance and minimizes load.
Some operations, however, use sessions that coordinate multiple requests. Examples of such operations include:
- Interleaving middle-tier and data tier operations (such as multi-statement transactions in which the middle-tier logic must be inserted between the initial database change and a subsequent database change)
- Implementing Host affinity with an e-node when working with a load balancer to exploit query caches on the e-node.
You can handle these edge cases by calling the endpoints in a session. If an endpoint needs to participate in a session, its declaration must include exactly one parameter with the session data type. The session parameter may be nullable but not multiple (and may never be a return value).
// A simple example of the use of "session" in an .api declaration: { "functionName" : "SessionChecks", "params" : [ { "name" : "api_session", "datatype" : "session", "desc" : "Holds the session object" }, ... }
If at least one endpoint has a session parameter, the generated class provides a newSessionState() factory that returns a SessionState object. The expected pattern of use:
- Construct a new session object when needed.
- Pass the same session object on each call that should execute in the same session.
Where endpoint modules need to participate in the same session, you must declare a session parameter for each of the corresponding endpoint proxies and document the expectations for coordination in the middle-tier consumer code. For instance, if one session endpoint starts a multi-statement transaction, another continues work in the same multi-statement transaction, and a third commits the transaction, the documentation should explain that each call would use the same session, as well as the sequence in which to make the calls.
The proxy service does not end the session explicitly. Instead, the session eventually times out (as controlled by the configuration of the App Server). The middle-tier code is responsible for calling an endpoint module to commit a multi-statement transaction before the session expires.
Providing the Module for an Endpoint Proxy
A JavaScript MJS module can be invoked through the /v1/invoke endpoint. This is the preferred method.
A data service endpoint can be implemented as a JavaScript MJS module. This is the preferred method.
You implement the data operations for an endpoint proxy in an XQuery or Server-Side JavaScript endpoint module. The proxy service directory of your project must contain exactly one endpoint module for each endpoint declaration in your service.
An endpoint module must have the same base name as the endpoint declaration. In addition, it must have either an .xqy (XQuery) or .sjs (JavaScript) extension, depending on the implementation language.
The App Server handles marshalling and unmarshalling for the endpoint. That is, the endpoint does not interact directly with the transport layer (which, internally, is currently HTTP).
The endpoint module must define an external variable for each parameter in the endpoint declaration. In an SJS endpoint, use a var statement at the top of the module with no initialization of the variable. In an XQuery endpoint, use an external variable with the server data type corresponding to the parameter data type.
The endpoint module must also return a value with the appropriate data type.
For the lookupPricingFactors endpoint whose declaration appears earlier, the SJS endpoint module would resemble the following fragment:
'use strict'; var productCode; // an xs.string value var customerId; // an xs.unsignedLong value ... /* the code that produces a JSON document as output */
The equivalent XQuery endpoint module would resemble the following fragment:
xquery version "1.0-ml"; declare variable $productCode as xs:string external; declare variable $customerId as xs:unsignedLong external; declare option xdmp:mapping "false"; ... (: the code that produces a JSON document as output :)
As a convenience, you can use the initializeModule Gradle task to create the skeleton for an endpoint module from an endpoint declaration. You specify the path (relative to the project directory) for the endpoint declaration with the endpointDeclarationFile property and the module extension (which can be either sjs or xqy) with the moduleExtension property.
Your Gradle build script should apply the com.marklogic.ml-development-tools plugin. You can execute the Gradle task using any of the following techniques:
- By setting the properties in the gradle.properties file and specifying the initializeModule task on the gradle command line
- By specifying the properties with the -P option as well as the initializeModule task on the gradle command line
- By supplying a build script with a custom task of the com.marklogic.client.tools.gradle.ModuleInitTask type
For the command-line approach, the Gradle build script would resemble the following example:
plugins { id 'com.marklogic.ml-development-tools' version '4.1.1' }
On Linux, the command-line for initializing the lookupPricingFactors.sjs SJS endpoint module from the lookupPricingFactors.api endpoint declaration might resemble the following example:
gradle \ -PendpointDeclarationFile=src/main/ml-modules/root/inventory/priceDynamically/lookupPricingFactors.api \ -PmoduleExtension=sjs \ initializeModule
Once each .api endpoint declaration file has an equivalent endpoint module to implement the endpoint, you can load the proxy service directory into the modules database and generate the proxy service Java class. (The Java code generation checks the endpoint module in the service directory to determine how to invoke the endpoint.)
Deploying a Proxy Service
You must load the resources from the proxy service directory into the module database of the App Server. Deploy your resources to the same database directory as the value of the endpointDirectory property of the service declaration file (service.json).
To load a directory into the modules database, you can use either of the mlLoadModules or mlReloadModules tasks provided by ml-gradle. You supply the properties required for deployment including the following:
- mlHost - required
- mlAppServicesUsername - required if not admin and mlPassword not set
- mlAppServicesPassword - required if not admin and mlUsername not set
- ml|AppServicesPort - required if not 8000
- mlModulesDatabaseName - required
- mlModulePermissions - required
- mlNoRestServer - required to be true, so that mlDeploy will not create a REST API server by default.
- mlReplaceTokensInModules - typically false
If you did not create the proxy service directory under the src/main/ml-modules/root project subdirectory, you must specify the parent directory for the root directory with the mlModulePaths property.
You can supply properties using a gradle.properties file or a task.
After you have configured the properties, the command to load the modules would resemble the following example (or the equivalent with mlReloadModules):
gradle mlLoadModules
Generating the Proxy Service Class
A proxy service class is a Java interface for calling the endpoint modules for your service on the MarkLogic e-node. You generate the proxy service class from the resources in the proxy service directory.
The proxy service class has the name specified by the $javaClass property of the service declaration file (service.json). The class has one method for each endpoint declaration with an associated endpoint module in the proxy service directory.
To generate the class, you use the generateEndpointProxies Gradle task. You specify the path (relative to the project directory) of the service declaration file (service.json) with the serviceDeclarationFile property. You can also specify the output directory with the javaBaseDirectory property or omit the property to use the default (which is the src/main/java subdirectory of the project directory).
Your Gradle build script should apply the com.marklogic.ml-development-tools plugin. You can execute the task using any of the following techniques:
- By setting the properties in the gradle.properties file and specifying the generateEndpointProxies task on the gradle command line
- By specifying the properties with the -P option as well as the generateEndpointProxies task on the gradle command line
- By supplying a build script with custom task of the com.marklogic.client.tools.gradle.EndpointProxiesGenTask type
- By supplying a build script with the endpointProxiesConfig extension configuration and specifying the generateEndpointProxies task on the gradle command line
For the custom task approach, the Gradle build script for generating a class with a method for each endpoint in the priceDynamically service might resemble the following example:
plugins { id 'com.marklogic.ml-development-tools' version '4.1.1' } task generateDynamicPricer(type: com.marklogic.client.tools.gradle.EndpointProxiesGenTask) { serviceDeclarationFile = 'src/main/ml-modules/root/inventory/priceDynamically/service.json' }
The command-line to execute the custom task would resemble the following example:
gradle generateDynamicPricer
You only need to regenerate the proxy service class when the list of endpoints or the name, parameters, or return value for an endpoint changes. You do not need the regenerate the proxy service class after changing the module that implements the endpoint.
Using a Proxy Service Class
In general, you can work with your generated proxy service Java class in the same way as with manually written Java source files.
The generated class has an on() static method that is a factory for constructing the class. The on() method requires a DatabaseClient for the App Server. You construct the database client by using the DatabaseClientFactory class of the Java API.
Note: You cannot specify the database explicitly when creating the DatabaseClient but, instead, must use the default database associated with the App Server.
Compiling a Proxy Service Class
After generating the proxy service class, you compile it in the usual way. In particular, by generating the proxy service class in the conventional directory for Gradle (which is src/main/java) and declaring a dependency on the MarkLogic Java API in the build script, you can use Gradle to compile the generated class without other configuration.
Testing a Proxy Service Class
After deploying your proxy service to the MarkLogic modules database, you can test your proxy service Java class in the same manner as any other Java class.
To write functional tests that confirm the endpoint modules work correctly, you can use any general-purpose test framework (for instance, JUnit). The test framework should:
- Call the on() static factory method to construct an instance.
- Call the appropriate method to invoke the endpoint module.
- Inspect the returned value to confirm the operation of the endpoint module.
Because the generated proxy service class is available as a Java interface, you can replace the implementation with a mock implementation of the interface for testing a middle-tier consumer.
Documenting a Proxy Service Class
The generated class has JavaDoc comments based on the desc properties from the service declaration and endpoint declarations. You can generate JavaDoc for the middle-tier consumer of the proxy service class in the usual way.
Packaging a Proxy Service
Finally, you can create a jar file with the compiled executable proxy service class in the usual way.
Publishing Your Data Service for Use in Other Projects
Users of Data Services need to know how to publish a Data Service for use in another project, and developers that require the end-points provided by a Data Service need to have a way to access them in their own projects.
This section shows you how to use the ml-gradle tool to enable publication of your Data Services.
Modifying the Source project to Enable Publication
The procedure is to modify the build.gradle file for the source project to publish the Data Services implementation to a Maven repository, as in:
plugins {
...
id 'maven-publish'
...
}
configurations {
...
myDataServiceBundle
}
task myDataServiceJar(type: Jar) {
baseName = 'myDataService'
description = "..."
from("src/test/ml-modules/root/ds/myDataService") {
into("myDataService/ml-modules/root/ds/myDataService")
}
destinationDir file("build/libs")
}
publishing {
publications {
...
MainMyDataService(MavenPublication) {
artifactId "myDataService"
artifact myDataServiceJar
}
...
}
}Using the Maven Bundle in Other Projects
After the bundle for the Data Service endpoint implementation has been published to a Maven repository, other projects can use the bundle by configuring build.gradle to use the mlBundle task provided by the ml-gradle tool:
plugins {
...
id "com.marklogic.ml-gradle" version "..."
...
}
dependencies {
...
mlBundle group: '...', name: 'myDataService', version: '...'
...
}For more information, see the Bundles section of our ml-gradle documentation:
Following the standard approach for Gradle and Maven repositories, the client interface can be published and consumed as a Java jar.