Matches for cat:guide/database-replication (cat:guide/database-replication (cat:guide (forest-status))) have been highlighted.


MarkLogic Server 11.0 Product DocumentationDatabase Replication Guide — Chapter 1
Database Replication in MarkLogic Server
This chapter describes Database Replication in MarkLogic Server in general terms, and includes the following sections:
- Terms Used in this Guide
- Understanding Database Replication
- Example Database Replication Configurations
- Database Replication for Disaster Recovery
- Rolling Back to the Non-Blocking Timestamp
- Upgrading Clusters Configured with Database Replication
- Comparison of Database Replication with Flexible Replication
To enable Database Replication, a license key that includes Database Replication is required. For details on purchasing a Database Replication license, contact your MarkLogic sales representative.
Terms Used in this Guide
The following are the definitions for the Database Replication terms used in this guide:
- To Replicate is to create a copy of a document in another database and to keep that copy in sync (possibly with some time-lag/latency) with the original.
- A Local Cluster is the cluster of MarkLogic Server hosts at your current location.
- A Foreign Cluster is a remote cluster of MarkLogic Server hosts.
- A Master Database is the database being replicated. In any Database Replication scheme there is a Master database and at least one Replica database.
- A Master Forest is the forest being replicated. In any Database Replication scheme there is a Master forest and at least one Replica forest.
- A Master Cluster is shorthand for the cluster that hosts a Master Database.
- A Replica Database is the database that receives replicated data from the Master database.
- A Replica Forest is the forest that receives replicated data from the Master forest.
- A Replica Cluster is shorthand for the cluster that hosts a Replica Database.
- A Bootstrap Host is the MarkLogic Server host machine used by a foreign cluster to initiate communication with the local cluster.
- A Foreign Bind Port is the port used on each host to handle XDQP communication with foreign clusters.
- Asynchronous Replication refers to a configuration in which the Master does not wait for confirmation that the update has been received by the Replica before committing the transaction and proceeding with additional transactions. Database Replication is asynchronous.
- Transaction-aware refers to a configuration in which all updates that make up a transaction on the Master are applied as a single transaction on the Replica.
- Zero-day Replication refers to replicating the data from the Master database that existed before replication was configured.
Understanding Database Replication
Database Replication is the process of maintaining copies of forests on databases in multiple MarkLogic Server clusters. At a minimum, there will be a Master database and one Replica database. A Master database can replicate to multiple databases. A Replica database cannot serve as a Master database to another Replica.
All hosts participating in Database Replication must:
This section contains the following topics:
- Overview of Database Replication
- Bulk Replication
- Bootstrap Hosts
- Inter-cluster Communication
- Replication Lag
- Master and Replica Database Index Settings
Overview of Database Replication
Database replication operates at the forest level by copying journal frames from a forest in the Master database and replaying them on a corresponding forest in the foreign Replica database.
As shown in the illustration below, each host in the Master cluster connects to the remote hosts that are necessary to manage the corresponding Replica forests. Replica databases can be queried but cannot be updated by applications.
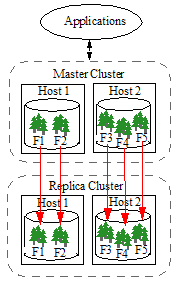
Bulk Replication
Any content existing in the Master databases before Database Replication is configured is bulk replicated into the Replica databases. Bulk replication is also used after the Master and foreign Replica have been detached for a sufficiently long period of time that journal replay is no longer possible. Once bulk replication has completed, journal replication will proceed.
The bulk replication process is as follows:
- The indexing operation on the Master database maintains a catalog of the current state of each fragment. The Master sends this catalog to the Replica database.
- The Replica compares the Master's catalog to its own and updates its fragments using the following logic:
- If the Replica has the fragment, it updates the nascent/deleted timestamps, if they are wrong.
- If the Replica has a fragment the Master doesn't have, it marks that fragment as deleted (it likely existed on the Master at some point in the past, but has been merged out of existence).
- If the Replica does not have a fragment, it adds it to a list of missing fragments to be returned by the Master.
- The Master iterates over the list of missing fragments returned from the Replica and sends each of them, along with their nascent/deleted timestamps, to the Replica where they are inserted.
For more information on fragments, see the Fragments chapter in the Administrator's Guide.
Bootstrap Hosts
Each cluster in a Database Replication scheme contains one or more bootstrap hosts that are used to establish an initial connection to foreign clusters it replicates to/from and to retrieve more complete configuration information once a connection has been established. When a host initially starts up and needs to communicate with a foreign cluster, it will bootstrap communications by establishing a connection to one or more of the bootstrap hosts on the foreign cluster. Once a connection to the foreign cluster is established, cluster configuration information is exchanged between all of the local hosts and foreign hosts.
For details on selecting the bootstrap hosts for your cluster, see Coupling Clusters in the Administrator's Guide.
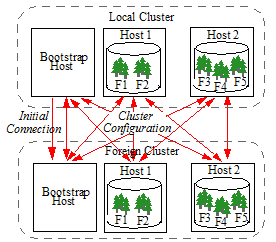
Inter-cluster Communication
Communication between clusters is done using the intra-cluster XDQP protocol on the foreign bind port. A host will only listen on the foreign bind port if it is a bootstrap host or if it hosts a forest that is involved in inter-cluster replication. By default, the foreign bind port is port 7998, but it can be configured for each host, as described in Changing the Foreign Bind Port. When secure XDQP is desired, a single certificate / private-key pair is shared by all hosts in the cluster when communicating with foreign hosts.
XDQP connections to foreign hosts are opened when needed and closed when no longer in use. While the connections are open, foreign heartbeat packets are sent once per second. The foreign heartbeat contains information used to determine when the foreign cluster's configuration has changed so updated information can be retrieved by the local bootstrap host from the foreign bootstrap host.
Replication Lag
Queries on a Replica database must run at a timestamp that lags the current cluster commit timestamp due to replication lag. Each forest in a Replica database maintains a special timestamp, called a Non-blocking Timestamp, that indicates the most current time at which it has complete state to answer a query. As the Replica forest receives journal frames from its Master, it acknowledges receipt of each frame and advances its nonblocking timestamp to ensure that queries on the local Replica run at an appropriate timestamp. Replication lag is the difference between the current time on the Master and the time at which the oldest unacknowledged journal frame was queued to be sent to the Replica.
You can set a lag limit in your configuration that specifies, if the Master does not receive an acknowledgement from the Replica within the time frame specified by the lag limit, transactions on the Master are stalled. The default lag limit is 15 seconds, and should work well for most installations. For the procedure to set the lag limit, see Configuring Database Replication.
Master and Replica Database Index Settings
Starting with MarkLogic version 9.0-7, indexing information is replicated by the Master database to the Replica system. This is done to insure that the index data on the replica is always in sync with the master database. If you want the option to switch over to the Replica database after a disaster, you still need to insure that the index settings are identical on the Master and Replica clusters.
If you need to update index settings after configuring Database Replication, make sure they are updated on both the Master and Replica databases. Changes to the index settings on the Master database will trigger reindexing, after which the reindexed documents will be replicated to the Replica. When a Database Replication configuration is removed for the Replica database (such as after a disaster), the Replica database will reindex, if necessary.
Example Database Replication Configurations
This section describes some of the possible Database Replication configurations.
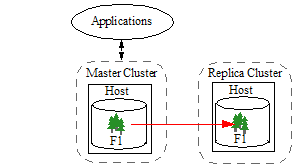
The most basic form of Database Replication consists of a two clusters, each containing a single database with a single forest, as shown below.
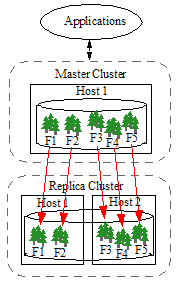
Master and Replica forests can be distributed differently across hosts in each cluster. For example, as shown below, all of the Master forests may reside on a single host and the Replica forests on two hosts.
A Master cluster can replicate forests to multiple Replica clusters. In the example shown below, the Master maintains a copy of each forest on two clusters:
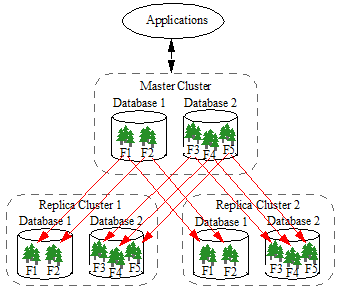
In the example shown below, the Master maintains a single copy of Database 1 on Replica Cluster 1 and a single copy of Database 2 on Replica Cluster 2:
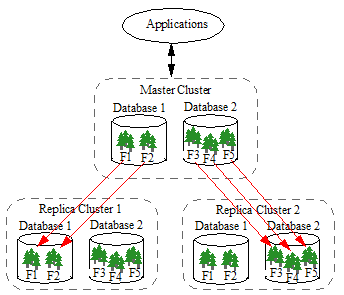
A cluster can contain both Master and Replica databases. On Cluster A in the example shown below, Database 1 is the Master database and Database 2 is the Replica database.
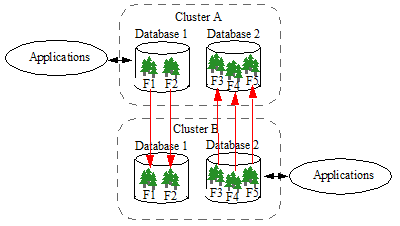
Database Replication for Disaster Recovery
The purpose of Database Replication is to make data continuously available to mission-critical applications with minimal impact to application performance. In a typical disaster recovery scheme, clusters are located in data centers at different geographical locations. In the event of a disaster in the location of the Master cluster, the data can be made available by the Replica cluster
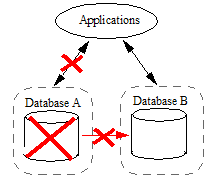
In this section, the original Master and Replica databases are referred to as Database A and Database B, respectively.
There are two basic approaches to a disaster recovery operation, each of which involves redirecting the applications to Database B. Before executing your applications on Database B, the database must be rolled back, as described in Rolling Back to the Non-Blocking Timestamp.
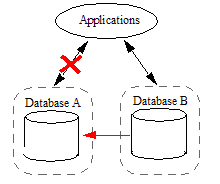
- Simply disable Database Replication on Database B so that it is no longer a Replica and can accept updates.
- Reconfigure Database B as the Master database and replicate updates to a third foreign database (Database C).
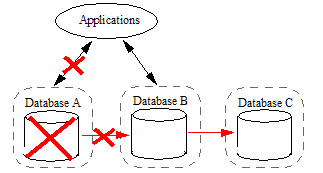
When Database A is returned to service, you can resynchronize it with Database B by either:
- Configuring Database A as a Replica of Database B. In this case, Database B will automatically bulk replicate to Database A.
- Running a backup operation on Database B and restoring Database A from the backup file, as described in Backing Up and Restoring a Database in the Administrator's Guide.
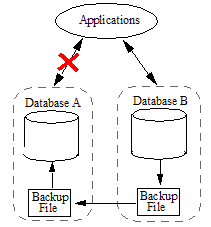
Once the data has been restored on the Database A, you can redirect the applications from Database B back to Database A.
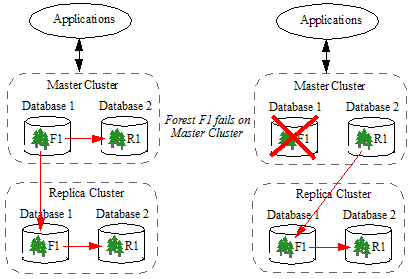
Database Replication can be used in combination with the local-disk failover feature described in High Availability of Data Nodes With Failover and Configuring Local-Disk Failover for a Forest in the Scalability, Availability, and Failover Guide. For example, the Master and Replica clusters shown below are configured for both local-disk failover and Database Replication. Should, for example, the F1 forest in the Master cluster become unavailable, then the R1 forest resumes replication to the F1 forest in the Replica cluster.
Rolling Back to the Non-Blocking Timestamp
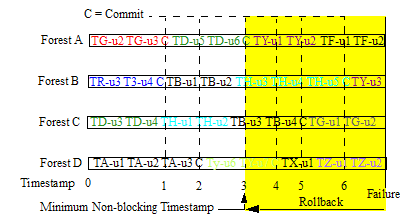
After you fail over your applications to a Replica database, each Replica forest will likely have committed its last transaction at different timestamps. If the Replica database has multiple forests and relationships exist between those forests, this inconsistency may cause problems. In order to return the database to a transactionally consistent state, all forests must be rolled back to the minimum non-blocking timestamp.
For example, the illustration below shows four forests and their committed transactions. Updates for each transaction are identified by the convention 'T#-u#' and commits are identified by a 'C'. Each forest completed its last commit at a different point in time when the failure of the Master database occurred. In this example, Forest A has only committed transactions up to timestamp 3 while Forest B has committed transactions up to timestamp 6. This means that, in order to return the database to a transactionally consistent state, all forests must be rolled back to at least timestamp 3.

The procedure described in this section can also be applied to the Master database, should you want to roll it back to some point after the last merge timestamp. When the Master database is rolled back, the rollback will be replicated to the Replica databases.
For example, the database you want to restore has four forests, as shown below. You use the xdmp:forest-status function to locate the nonblocking-timestamp value for each forest and roll back all of your forests to the minimum nonblocking-timestamp value. In this example, the minimum nonblocking-timestamp is the timestamp of the last committed transaction in Forest A.
The following procedure describes how to restore to the minimum non-blocking timestamp using the XQuery API.
- Use the admin:database-get-merge-timestamp function to get the current merge timestamp. Save this value so it can be reset after you have completed the rollback operation.
- Use the admin:database-set-merge-timestamp function to set the merge timestamp to any time before the failure of the master database. This will preserve fragments in merge after this timestamp until you have rolled back your forest data.
- Use the xdmp:forest-rollback function to roll back the forests to the minimum
nonblocking-timestampreturned by the xdmp:forest-status function for each forest that is in theopenoropen replicastate.For example, you can use the following query to rollback your forest data for the Documents database:
xquery version "1.0-ml"; let $db := xdmp:database("Documents") let $timestamp := xdmp:database-nonblocking-timestamp($db) let $rollback := xdmp:forest-rollback( xdmp:forest-open-replica( xdmp:database-forests($db)), $timestamp) return "Roll back done" - Use admin:database-set-merge-timestamp function to set the merge timestamp back to the value you saved in Step 1.
When the Security database is replicated, amps and triggers refer to Modules database IDs in the Master cluster. When failing over to the Security database on the Replica cluster, use the sec:amps-change-modules-database and trgr:triggers-change-modules-database
Starting in 9.0-7 for triggers and 10.0-2 for amps, Database names can be used in the trigger and amp creation apis, thus making it easy to support the same functionality on replica clusters for databases with the same names.
Upgrading Clusters Configured with Database Replication
If the Security database isn't replicated, then there shouldn't be anything special you need to do other than upgrade the two clusters.
If the security database is replicated, do the following:
- Upgrade the Replica cluster and run the upgrade scripts. This will update the Replica's Security database to indicate that it is current. It will also do any necessary configuration upgrades.
- Upgrade the Master cluster and run the upgrade scripts. This will update the Master's Security database to indicate that it is current. It will also do any necessary configuration upgrades.
If the effective version of the replica database is higher than the master database, database replication should still work. If the effective version of replica database is lower than the master database, database replication will be paused.
Comparison of Database Replication with Flexible Replication
MarkLogic Server provides two types of replication: Database Replication, as described in this guide, and Flexible Replication, as described in the Flexible Replication Guide. You should choose a replication type based on your application and high-availability requirements
Depending on your requirements, one type of replication might have an advantage over the other.
The key differences between the these two types of replication are:
- Replicate all or part of the Master database -- Database Replication replicates the entire Master database to the Replica database. Flexible Replication replicates Content Processing Framework (CPF) domains and allows you to write XQuery filters that enable you to modify the replicated documents in some manner, determine whether to replicate a change, or select which parts of a document will be replicated. As a consequence, Flexible Replication enables you to replicate select content from the Master database.
- Performance -- Flexible Replication uses CPF and generates information in the properties of each replicated document. Database Replication simply copies and replays journal frames. If you replicate a complete database, you can expect less overhead with Database replication than with Flexible Replication.
- Transactional -- Database Replication replicates as soon as a document is inserted or updated and ensures that a single multi-document transaction in the Master database replicates as a single multi-document transaction to the Replica database. Flexible Replication replicates documents after each transaction without consideration of transactional grouping in the Master database. For example, if you have a transaction that commits 10 documents to the Master database and some sort of failure occurs, with Flexible Replication it is possible for the Replica to end up with 5 documents from that transaction on the Replica. With Database Replication, the Replica will either have no documents or all 10 of them.