Matches for cat:guide/concepts (cat:guide) have been highlighted.


MarkLogic Server 11.0 Product DocumentationConcepts Guide — Chapter 7
Clustering and Caching
You can combine multiple instances of MarkLogic to run as a cluster. The cluster has multiple machines (hosts), each running an instance of MarkLogic Server. Each host in a cluster is sometimes called a node, and each node in the cluster has its own copy of all of the configuration information for the entire cluster.
When deployed as a cluster, MarkLogic implements a shared-nothing architecture. There is no single host in charge; each host communicates with every other host, and each node in the cluster maintains its own copy of the configuration. The security database, as well as all of the other databases in the cluster, are available to each node in the cluster. This shared-nothing architecture has great advantages when it comes to scalability and availability. As your scalability needs grow, you simply add more nodes.
Clustering MarkLogic provides four key advantages:
- The ability to use commodity servers, bought for reasonable prices.
- The ability to incrementally add (or remove) new servers as need demands.
- The ability to maximize cache locality, by having different servers optimized for different roles and managing different parts of the data.
- The ability to include failover capabilities to handle server failures.
Cluster data can be replicated, as described in Failover and Database Replication.
This chapter has the following sections:
- MarkLogic E-nodes and D-nodes
- Communication Between Nodes
- Communication Between Clusters
- Cluster Management
- Caching
- Cache Partitions
- No Need for Global Cache Invalidation
- Locks and Timestamps in a Cluster
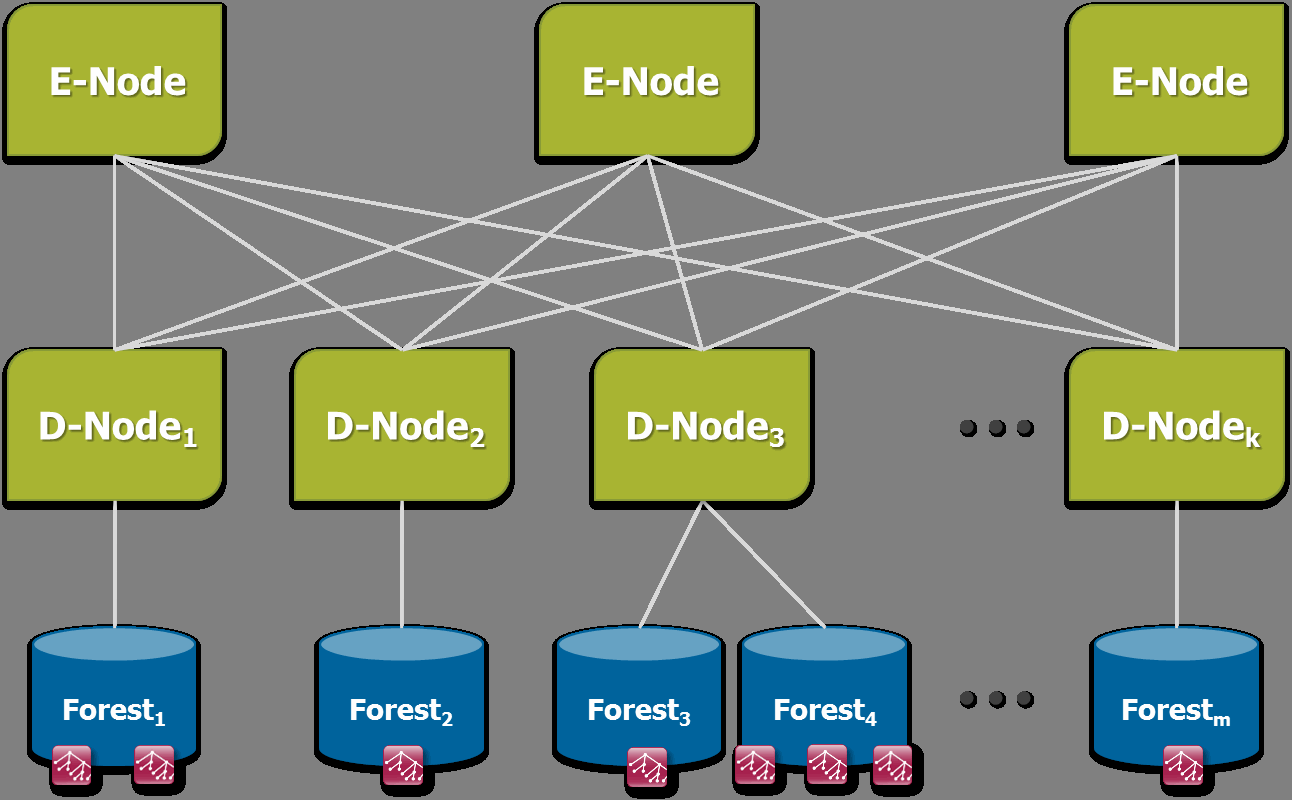
MarkLogic E-nodes and D-nodes
MarkLogic servers placed in a cluster are typically configured for one of two types of operations. They can be Evaluators (E-nodes) or they can be Data Managers (D-nodes). E-nodes listen on a socket, parse requests, and generate responses. D-nodes hold data along with its associated indexes, and support E-nodes by providing them with the data they need to satisfy requests and process updates.
As your user load grows, you can add more E-nodes. As your data size grows, you can add more D-nodes. A mid-sized cluster might have 2 E-nodes and 10 D-nodes, with each D-node responsible for about 10% of the total data.
A load balancer usually spreads incoming requests across the E-nodes. An E-node processes the request and delegates out to the D-nodes for any subexpression of the request involving data retrieval or storage. For example, if a request needs the top ten paragraphs most relevant to a query, the E-node sends the query constraint to every D-node with a forest in the database, and each D-node responds with the most relevant results for its portion of the data. The E-node coalesces the partial answers into a single unified answer: the most relevant paragraphs across the full cluster. An intra-cluster back-and-forth happens frequently as part of every request. It happens any time the request includes a subexpression requiring index work, document locking, fragment retrieval, or fragment storage.
For efficiency, D-nodes do not send full fragments across the wire unless they are truly needed by the E-node. For example, when doing a relevance-based search, each D-node forest returns an iterator containing an ordered series of fragment ids and scores extracted from indexes. The E-node pulls entries from each of the iterators returned by the D-nodes and decides which fragments to process, based on the highest reported scores. When the E-node wants to process a particular result, it fetches the fragment from the appropriate D-node.
Communication Between Nodes
Each node in a cluster communicates with all of the other nodes in the cluster at periodic intervals. This periodic communication, known as a heartbeat, circulates key information about host status and availability between the nodes in a cluster. Through this mechanism, the cluster determines which nodes are available and communicates configuration changes with other nodes in the cluster. If a node goes down for some reason, it stops sending heartbeats to the other nodes in the cluster.
The cluster uses the heartbeat to determine if a node in the cluster is down. A heartbeat from a given node communicates its view of the cluster at the moment of the heartbeat. This determination is based on a vote from each node in the cluster, based on each node's view of the current state of the cluster. To vote a node out of the cluster, there must be a quorum of nodes voting to remove a node. A quorum occurs more than 50% of the total number of nodes in the cluster (including any nodes that are down) vote the same way. Therefore, you need at least 3 nodes in the cluster to reach a quorum. The voting that each host performs is done based on how long it has been since it last had a heartbeat from the other node. If at half or more of the nodes in the cluster determine that a node is down, then that node is disconnected from the cluster. The wait time for a host to be disconnected from the cluster is typically considerably longer than the time for restarting a host, so restarts should not cause hosts to be disconnected from the cluster (and therefore they should not cause forests to fail over). There are configuration parameters to determine how long to wait before removing a node (for details, see XDQP Timeout, Host Timeout, and Host Initial Timeout Parameters).
Each node in the cluster continues listening for the heartbeat from the disconnected node to see if it has come back up, and if a quorum of nodes in the cluster are getting heartbeats from the node, then it automatically rejoins the cluster.
The heartbeat mechanism enables the cluster to recover gracefully from things like hardware failures or other events that might make a host unresponsive. This occurs automatically, without human intervention; machines can go down and automatically come back up without requiring intervention from an administrator. If the node that goes down hosts content in a forest, then the database to which that forest belongs goes offline until the forest either comes back up or is detached from the database. If you have failover enabled and configured for that forest, it attempts to fail over the forest to a secondary host (that is, one of the secondary hosts will attempt to mount the forest). Once that occurs, the database will come back online. For details on failover, see High Availability of Data Nodes With Failover in the Scalability, Availability, and Failover Guide.
Communication Between Clusters
Database replication uses inter-cluster communication. Communication between clusters uses the XDQP protocol. Before you can configure database replication, each cluster in the replication scheme must be aware of the configuration of the other clusters. This is accomplished by coupling the local cluster to the foreign cluster. For more information, see Inter-cluster Communication and Configuring Database Replication in the Database Replication Guide and Clusters in the Administrator's Guide.
Cluster Management
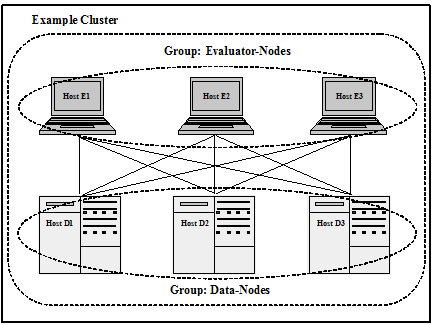
The MarkLogic Server software installed on each server is always the same regardless of its role in the cluster. If the server is configured to listen on a socket for incoming requests (HTTP, XDBC, WebDAV, etc), then it is an E-node. If it manages data (has one or more attached forests), then it is a D-node. In the MarkLogic administration pages you can create named groups of servers, each of which share the same configuration, making it easy to have an E Group and a D Group.
The first time you access the administration screens for a new MarkLogic instance, it asks if you want the instance to join a preexisting cluster. If so, you give it the name of any other server host in the cluster and what group it should be part of. The new system configures itself according to the settings of that group.
The following diagram illustrates how the concepts of clusters, hosts and groups are implemented in an example multi-host distributed architecture. The diagram shows a single cluster involving six hosts that are segmented into two groups:
Caching
On database creation, MarkLogic assigns default cache sizes optimized for your hardware, using the assumption that the server will be acting as both E-node and D-node. You can improve performance in a clustered environment by optimizing each group's cache sizes. With an E-node group, you can increase the size of the caches related to request evaluation at the expense of those related to data management. For a D-node, you can do the opposite. The table below describes some of the types of caches and how they should be changed in a clustered environment:
You should increase the size of the Expanded Tree Cache on E-nodes and greatly reduce it on D-nodes. D-nodes require some Expanded Tree Cache as a workspace to support background reindexing, so the cache should never be reduced to zero. Also, if the D-node group includes an admin port on 8001, which is a good idea in case you need to administer the box directly should it leave the cluster, it needs to have enough Expanded Tree Cache to support the administration work. A good rule of thumb: set the Expanded Tree Cache to 128 Megabytes on a D-node.
When an E-node needs a fragment, it first looks in its local Expanded Tree Cache. If the fragment is not there, the E-node asks the D-node to send it. The D-node first looks in its Compressed Tree Cache. If the fragment is not there, the D-node reads the fragment off disk and sends it over the wire to the E-node. Notice the cache locality benefits gained because each D-node maintains the List Cache and Compressed Tree Cache for its particular subset of data.
Cache Partitions
Along with setting each cache size, you can also set a cache partition count. Each cache defaults to one or two or sometimes four partitions, depending on your memory size. Increasing the count can improve cache concurrency at the cost of efficiency.
Cache partitioning works as follows: Before a thread can make a change to a cache, it needs to acquire a write lock for the cache in order to keep the update thread-safe. The lock is short-lived, but it still has the effect of serializing write access. If the cache had only one partition, all of the threads would need to serialize through a single write lock. With two partitions, there is effectively two different caches and two different locks, and double the number of threads can make cache updates concurrently.
A thread uses a cache lookup key to determine which cache partition to store or retrieve an entry. A thread accessing a cache first determines the lookup key, determines which cache has that key, and goes to that cache. There is no need to read-lock or write-lock any partition other than the one appropriate for the key.
You want to avoid having an excessive number of partitions because it reduces the efficiency of the cache. Each cache partition has to manage its own aging out of entries, and can only select to remove the most stale from itself, even if there is a more stale entry in another partition.
For more information on cache tuning, see the Query Performance and Tuning guide.
No Need for Global Cache Invalidation
A typical search engine forces its administrator to make a tradeoff between update frequency and cache performance because it maintains a global cache and any document change invalidates the cache. MarkLogic avoids this problem by managing its List Cache and Compressed Tree Cache at the stand level. As described in What's on Disk, stands are the read-only building blocks of forests. Stand contents do not change when new documents are loaded, only when merges occur, so there is no need for the performance-killing global cache invalidation when updates occur.
Locks and Timestamps in a Cluster
MarkLogic manages locks in a decentralized way. Each D-node has the responsibility for managing the locks for the documents under its forest(s). It does this as part of its regular data access work. For example, if an E-node running an update request needs to read a set of documents, the D-nodes with those documents will acquire the necessary read-locks before returning the data. It is not necessary for the D-nodes to immediately inform the E-node about their lock actions. Each D-node does not have to check with any other hosts in the cluster to acquire locks on its subset of data. (This is the reason all fragments for a document always get placed in the same forest.)
In the regular heartbeat communication sent between the hosts in a cluster, each host reports on which locks it is holding in order to support the background deadlock detection thread.
The transaction timestamp is also managed in a decentralized way. As the very last part of committing an update, the D-node or D-nodes making the change look at the latest timestamp from their point of view, increase it by one, and use that timestamp for the new data. Getting a timestamp doesn't require cluster-wide coordination. Other hosts see the new timestamp as part of the heartbeat communication sent by each host. Each host broadcasts its latest timestamp, and hosts keep track of the maximum across the cluster.
In the special cases where you absolutely need serialization between a set of independent updates, you can have the updates acquire the same URI write-lock and thus naturally serialize their transactions into different numbered timestamps.