
MarkLogic 9 Product DocumentationMarkLogic Connector for Hadoop Developer's Guide — Chapter 1
Introduction to MarkLogic Connector for Hadoop
The Hadoop Connector is deprecated starting with MarkLogic release 9.0-12 and will be removed from the product in a future release.
The MarkLogic Server Hadoop MapReduce Connector provides an interface for using a MarkLogic Server instance as a MapReduce input source and/or a MapReduce output destination.
This chapter is an overview of the MarkLogic Connector for Hadoop, covering:
- Terms and Definitions
- Overview
- MarkLogic-Specific Key and Value Types
- Deploying the Connector with a MarkLogic Server Cluster
- Making a Secure Connection to MarkLogic Server with SSL
If you are not already familiar with Hadoop MapReduce, see Apache Hadoop MapReduce Concepts.
For installation instructions and an example of configuring and running a job, see Getting Started with the MarkLogic Connector for Hadoop.
Terms and Definitions
You should be familiar with the following terms and definitions before using the Hadoop MapReduce Connector.
| Term | Definition |
|---|---|
| Hadoop MapReduce | An Apache Software Foundation software framework for reliable, scalable, distributed parallel processing of large data sets across multiple hosts. The Hadoop core framework includes a shared file system (HDFS), a set of common utilities to support distributed processing, and an implementation of the MapReduce programming model. See Apache Hadoop MapReduce Concepts. |
| job | The top level unit of work for a MapReduce system. A job consists of an input data set, a MapReduce program, and configuration properties. Hadoop splits a job into map and reduce tasks which run across a Hadoop cluster. A Job Tracker node in the Hadoop cluster manages MapReduce job requests. |
| task | An independent subcomponent of a job, performing either map or reduce processing. A task processes a subset of data on a single node of a Hadoop cluster. |
| map task | A task which contributes to the map step of a job. A map task transforms the data in an input split into a set of output key-value pairs which can be further processed by a reduce task. A map task has no dependence on or awareness of other map tasks in the same job, so all the map tasks can run in parallel. |
| reduce task | A task which contributes to the reduce step of a job. A reduce task takes the results of the map tasks as input, produces a set of final result key-value pairs, and stores these results in a database or file system. A reduce task has no dependence on or awareness of other reduce tasks in the same job, so all the reduce tasks can run in parallel. |
| mapper | Programatically, a subclass of org.apache.hadoop.mapreduce.Mapper. The mapper transforms map input key-value pairs into map output key-value pairs which can be consumed by reduce tasks. An input pair can map to zero, one, or many output pairs. |
| reducer | Programmatically, a subclass of org.apache.hadoop.mapreduce.Reducer. The reducer aggregates map output into final results during the reduce step of a job. The value portion of an input key-value pair for reduce is a list of all values sharing the same key. One input key-value pair can generate zero, one, or many output pairs. |
| input source | A database, file system, or other system that provides input to a job. For example, a MarkLogic Server instance or HDFS can be used as an input source. |
| input split | The subset of the input data set assigned to a map task for processing. Split generation is controlled by the |
| input split query | When using MarkLogic Server as an input source, the query that determines which content to include in each split. By default, the split query is built in. In advanced input mode, the split query is part of the job configuration. |
| input query | When using MarkLogic Server as an input source, the query that generates input key-value pairs from the fragments/records in the input split. |
InputFormat |
The abstract superclass, The Apache Hadoop MapReduce API includes |
OutputFormat |
The abstract superclass, The Apache Hadoop MapReduce API includes |
| HDFS | The Hadoop Distributed File System, which can be used as an input source or an output destination in jobs. HDFS is the default source and destination for Hadoop MapReduce jobs. |
| shuffle | The process of sorting all map output values with the same key into a single (key, value-list) reduce input key-value pair. The shuffle happens between map and reduce. Portions of the shuffle can be performed by map tasks and portions by reduce tasks. |
| CDH | Cloudera's Distribution Including Apache Hadoop. One of the Hadoop distributions supported by the MarkLogic Connector for Hadoop. |
| HDP | Hortonworks Data Platform. One of the Hadoop distributions supported by the MarkLogic Connector for Hadoop. |
Overview
This section provides a high level overview of the features of the MarkLogic Connector for Hadoop. If you are not already familiar with Hadoop MapReduce, you should first read Apache Hadoop MapReduce Concepts.
Topics covered in this section:
- Job Building Tools Provided by the Connector
- Input and Output Selection Features
- MarkLogic Server Access via XDBC App Server
Job Building Tools Provided by the Connector
The MarkLogic Connector for Hadoop manages sessions with MarkLogic Server and builds and executes queries for fetching data from and storing data in MarkLogic Server. You only need to configure the job and provide map and reduce functions to perform the desired analysis.
The MarkLogic Connector for Hadoop API provides tools for building MapReduce jobs that use MarkLogic Server, such as the following:
InputFormatsubclasses for retrieving data from MarkLogic Server and supplying it to the map function as documents, nodes, and user-defined types. See InputFormat Subclasses.OutputFormatsubclasses for saving data to MarkLogic Server as documents, nodes and properties. See OutputFormat Subclasses.- Classes supporting key and value types specific to MarkLogic Server content, such as nodes and documents. See MarkLogic-Specific Key and Value Types.
- Job configuration properties specific to MarkLogic Server, including properties for selecting input content, controlling input splits, and specifying output destination and document quality. See Input Configuration Properties and Output Configuration Properties.
Input and Output Selection Features
Using MarkLogic Server for input is independent of using it for output. For example, you can use a MarkLogic Server database for input and save your results to HDFS, or you can use HDFS for input and save your results in a MarkLogic Server database. You can also use MarkLogic Server for both input and output.
The MarkLogic Connector for Hadoop supports two input modes, basic and advanced, through the mapreduce.marklogic.input.mode configuration property. The default mode is basic. In basic input mode, the connector handles all aspects of split creation, and your job configuration specifies which content in a split is transformed into input key-value pairs.
In advanced input mode, you control both the split creation and the content selection by writing an input split query and an input query. For details, see Using MarkLogic Server for Input. Basic mode provides the best performance.
When using MarkLogic Server for input, input data can come from either database content (documents) or from a lexicon.
MapReduce results can be stored in MarkLogic Server as documents, nodes, and properties. See Using MarkLogic Server for Output.
MarkLogic Server Access via XDBC App Server
The MarkLogic Connector for Hadoop interacts with MarkLogic Server through an XDBC App Server. When using MarkLogic Server for both input and output, the input server instance and output server instance can be different. The connector API includes configuration properties for identifying the server instances and input and output database.
The configured MarkLogic Server instance acts as an initial point of contact for the job, but the MarkLogic Connector for Hadoop spreads the query load across all nodes in the MarkLogic Server cluster that host a forest of the target database. The job communicates directly with each node, rather than bottlenecking on the single MarkLogic Server instance configured into the job. For details, see Deploying the Connector with a MarkLogic Server Cluster.
The MarkLogic Connector for Hadoop creates and manages the XDBC sessions for your application using XCC. Your application code need not manage App Server sessions.
MarkLogic-Specific Key and Value Types
A MapReduce job configuration specifies the input and output key and value types for map and reduce. The MarkLogic Connector for Hadoop provides MarkLogic specific key and value classes, as follows:
The MarkLogic Connector for Hadoop includes InputFormat and OutputFormat subclasses which predefine key-value pairs using the types listed above, such as NodeInputFormat. See InputFormat Subclasses and Using MarkLogic Server for Output.
The MarkLogic Server specific types can be used in conjuction with non-connector types, such as org.apache.hadoop.io.Text. For example, a job using NodeInputFormat always has map input key-value pairs of type (NodePath, MarkLogicNode), but can produce output key-value pairs of type (Text, IntWritable).
For input data, you can also combine the MarkLogic Server specific types with certain Apache Hadoop MapReduce types in the same key-value pair by using com.marklogic.mapreduce.KeyValueInputFormat or com.marklogic.mapreduce.ValueInputFormat. For details, see Using KeyValueInputFormat and ValueInputFormat.
The key and value types are usually configured programmatically through the org.apache.hadoop.mapreduce.Job API. For an example, see InputFormat Subclasses.
Deploying the Connector with a MarkLogic Server Cluster
This section covers the following topics:
- Relationship of MarkLogic Server to a Hadoop Cluster
- Jobs Use In-Forest Evaluation
- Using the Pre-Configured XDBC App Server on Port 8000
- Cluster-wide XDBC Configuration Requirements
For more information about clustering, see Clustering in MarkLogic Server in the Scalability, Availability, and Failover Guide.
Relationship of MarkLogic Server to a Hadoop Cluster
Although it is possible to deploy Hadoop MapReduce, HDFS, and MarkLogic Server on a single host for development purposes, production deployments usually involve a Hadoop cluster and a MarkLogic Server cluster, as shown below:
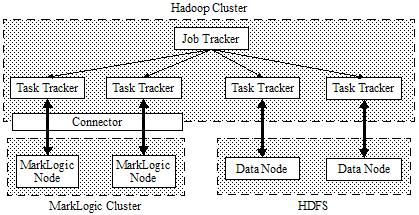
In a typical MapReduce/HDFS production deployment, a MapReduce Task Tracker runs on each data node host, though this is not required.
When using MarkLogic Server in a MapReduce job, whether or not to co-locate a Task Tracker with each MarkLogic Server node is dependent on your workload. Co-location reduces network traffic between the server and the MapReduce tasks, but places a heavier computational and memory burden on the host.
Jobs Use In-Forest Evaluation
To optimize performance, the MarkLogic Connector for Hadoop interacts with MarkLogic Server at the forest level. For example, if the reduce step of a job inserts a document into a MarkLogic Server database, the insert is an in-forest insert.
When MarkLogic Server is deployed across a cluster, the forests of a database can be distributed across multiple nodes. In this case, the in-forest evaluation of MapReduce related queries is also distributed across the MarkLogic Server nodes hosting the forests of the target database.
Therefore, every MarkLogic Server host that has at least one forest in a database used by a MapReduce job must be configured to act as both an e-node and a d-node. That is, each host must be capable of providing both query evaluation and data services. A pure d-node (for example, a host with a very small configured expanded tree cache) is not usable in a MapReduce job.
Using the Pre-Configured XDBC App Server on Port 8000
When you install MarkLogic Server, an App Server is pre-configured on port 8000 that is capable of handling XDBC requests. You can use this App Server with the MarkLogic Connector for Hadoop.
By default, the App Server on port 8000 is attached to the Documents database. To use this (or any other App Server) with an alternative database, set one or both of the following connector configuration properties, depending on whether your job uses MarkLogic for input, output, or both:
For example, if your job uses MarkLogic for input, your job configuration setting will include settings similar to the following:
<property> <name>mapreduce.marklogic.input.host</name> <value>my-marklogic-host</value> </property> <property> <name>mapreduce.marklogic.input.port</name> <value>8000</value> </property> <property> <name>mapreduce.marklogic.input.databasename</name> <value>my-input-database</value> </property>
Cluster-wide XDBC Configuration Requirements
Because the MarkLogic Connector for Hadoop uses an XDBC App Server and in-forest query evaluation, your cluster might need special configuration to support MapReduce jobs if you use an XDBC App Server other than the one pre-configured on port 8000.
If MarkLogic Server is used for input, each host that has at least one forest attached to the input database must have an XDBC App Server configured for that database. Additionally, the XDBC App Server must listen on the same port on each host.
The same requirement applies to using MarkLogic Server for output. The input App Server, database and port can be the same or different from the output App Server, database and port.
Hosts within a group share the same App Server configuration, so you only need additional App Servers if hosts with forests attached to the input or output database are in multiple groups.
When you use the MarkLogic Connector for Hadoop with a database that has forests on hosts in more than one group, you must ensure MarkLogic in all groups is configured with an XDBC App Server attached to the database, listening on the same port.
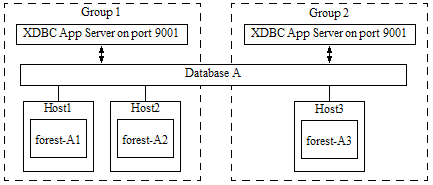
For example, the cluster shown below is properly configured to use Database A as a MapReduce input source. Database A has 3 forests, located on 3 hosts in 2 different groups. Therefore, both Group 1 and Group 2 must make Database A accessible on port 9001.
For details about the query evaluation, see Jobs Use In-Forest Evaluation. For information on related MapReduce job configuration properties, see Identifying the Input MarkLogic Server Instance and Identifying the Output MarkLogic Server Instance.
Making a Secure Connection to MarkLogic Server with SSL
The MarkLogic Connector for Hadoop supports making secure connections to the input and output MarkLogic Server instances. To configure secure connections:
- Enable SSL in the App Server, as described in General Procedure for Setting up SSL for an App Server in the Security Guide.
- Create an implementation of the
com.marklogic.mapreduce.SslConfigOptionsinterface in your job. Use one of the techniques described in Accessing SSL-Enabled XDBC App Servers in the XCC Developer's Guide to provide ajavax.net.ssl.SSLContextto the MarkLogic Connector for Hadoop. - Specify the
SslConfigOptionssubclass name from the previous step in the configuration property(s)mapreduce.marklogic.input.ssloptionsclassormapreduce.marklogic.output.ssloptionsclass. See the examples below. - Enable SSL use by setting the configuration property(s)
mapreduce.marklogic.input.usesslormapreduce.marklogic.output.usessltotrue.
You can set mapreduce.marklogic.input.ssloptionsclass and mapreduce.marklogic.output.ssloptionsclass either in a configuration file or programmatically. To set the property in a configuration file, set the value to your SslConfigOptions class name with .class appended to it. For example:
<property> <name>mapreduce.marklogic.input.ssloptionsclass</name> <value>my.package.MySslOptions.class</value> </property>
To set the property programatically, use the org.apache.hadoop.conf.Configuration API. For example:
import org.apache.hadoop.conf.Configuration; import com.marklogic.mapreduce.SslConfigOptions; public class ContentReader { static class MySslOptions implements SslConfigOptions {...} public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); ... conf.setClass("mapreduce.marklogic.input.ssloptionsclass", MySslOptions.class, SslConfigOptions.class); ... } }
For a complete example of using SSL with the MarkLogic Connector for Hadoop, see ContentReader. For a basic XCC application using SSL, see HelloSecureWorld in the XCC Developer's Guide.