
MarkLogic 10 Product DocumentationAdministrator's Guide — Chapter 25
Text Indexing
Before loading documents into a database, you have the option of specifying a number of parameters that will impact how the text components of those documents will be treated. This chapter describes those parameters and includes the following sections:
- Text Indexes
- Phrasing and Element-Word-Query Boundary Control
- Query Behavior with Reindex Settings Enabled and Disabled
Text indexes and phrasing parameters are set on a per-database basis.
Text Indexes
MarkLogic Server allows you to configure, at the database level, which types of text indexes are constructed and maintained during document loading and updating. Each type of index accelerates the performance of a certain type of query. You can specify whether or not each different type of index is maintained for a given database.
The index settings are designed to apply to an entire database. If you change any index settings on a database in which documents are already loaded, you must reindex your existing data, either by setting the reindexer enable setting to true for that database or by reloading the data.
Understanding your likely query set will help you determine which of these index types to maintain. The cost of supporting additional indexes is increased disk space and document load times. As more and more indexes are maintained, document load speed decreases. By default, MarkLogic Server builds a set of indexes that is designed to yield the fast query performance in general usage scenarios.
Text index types are configured on a per-database basis. This configuration should be completed before any documents are loaded into the specified database, although it can be changed later. If you change any index settings on a database in which documents are already loaded, you must reindex your existing data, either by setting the reindexer enable setting to true for that database or by reloading the data.
In addition to the standard indexes, you can configure indexes on individual elements and attributes in a database. You can create range indexes and/or lexicons on individual elements or attributes in a database. For information on these indexes, see Range Indexes and Lexicons. You can also create named fields which can explicitly include or exclude specified elements. For details on fields, see Fields Database Settings.
This section describes the text indexes in MarkLogic Server and includes the following subsections:
Understanding the Text Index Settings
The following table describes the different types of indexes available. The indexes are not mutually independent. If both the word search and stemmed search indexes are disabled, the configuration of the remaining indexes is irrelevant, as they all depend on the existence of the word and/or stemmed-search index.
| Index | Default Setting | Description |
|---|---|---|
| language | en | Specifies the default language for content in this database. Any content without an xml:lang attribute will be indexed in the language specified here. You should have a license key if you specify a non-English language; if you specify a non-english language and do not have a license for that language, the stemming and tokenization will be generic. |
stemmed searches |
Off (index is not built) | Controls whether searches return relevance ranked results by matching word stems. A word stem is the part of a word that is common to all of its inflected variants. For example, in English, "run" is the stem of "run", "runs", "ran", and "running". A stemmed search returns more matching results than the exact words specified in the query. A stemmed search for a word finds the same terms as an unstemmed search, plus terms that derive from the same meaning and part of speech as the search term. For example, a stemmed search for There are three types of stemming: basic (one stem per word), advanced (one or more stems per word), and decompounding (advanced plus smaller component words of large compound words). Without either this index or the word searches index, MarkLogic Server is unable to perform relevance ranking and will refuse to execute any If both the stemmed search and word search indexes are enabled, MarkLogic Server defaults to performing stemmed searches (unless an unstemmed search is explicitly specified). Turn this index off if you want to disable stemmed searches. If word and stemmed search indexes are both off, then full-text searches are effectively disabled. |
word searches (unstemmed) |
On (index is built) | Enables MarkLogic Server to return relevance ranked results which match exact words in text elements. Either this index or the stemmed search index is needed for MarkLogic Server to execute any For many applications, keeping this word search index off and the stemmed search index on is sufficient to return the desired results for queries. Turn this index on if you want to do exact word-only matches. If word and stemmed search indexes are both off, then full-text searches are effectively disabled. |
word positions |
Off (index is not built) | Speeds up the performance of proximity queries that use the Turn this index off if you are not interested in proximity queries or phrase searches and if you want to conserve disk space and decrease loading time. If you turn this option on, you might find that you no longer need |
fast phrase searches |
On (index is built) | Accelerates phrase searches by building additional indexes that describe sequences of words at load (or reindex) time. Without this index, MarkLogic Server will still perform phrase searches, just more slowly. Turn this index off if only a small percentage of your queries will contain phrase searches, and if conserving disk space and enhancing load speed is more important than the performance of those queries. |
fast case sensitive searches |
On (index is built) | Accelerates case sensitive searches by building both case sensitive and case insensitive indexes at load time. Without this index, MarkLogic Server will still perform case sensitive searches, just more slowly. Turn this index off if only a small percentage of your text searches will be case sensitive, and if conserving disk space and enhancing load speed is more important than the performance of those queries. |
fast reverse searches |
Off (index is not built) | Speeds up reverse query searches by indexing stored queries. Turn this option on to speed up searches that use cts:reverse-query. |
fast diacritic sensitive searches |
On (index is built) | Speeds up diacritic-sensitive searches by eliminating some false positive results. Turn this option off if you do not want to do diacritic-sensitive searches. |
fast element word searches |
On (index is built) | Accelerates searches that look for words in specific elements by building additional indexes at load time. Without this index, MarkLogic Server will still perform these searches, just more slowly. Turn this index off if only a small percentage of your queries rely on finding words within specific document elements, and if conserving disk space and enhancing load speed is more important than the performance of those queries. |
element word positions |
Off (index is not built) | Speeds up the performance of proximity queries that use the Turn this index off if you are not interested in proximity queries and if you want to conserve disk space and decrease loading time. |
fast element phrase searches |
On (index is built) | Accelerates phrase searches on elements by building additional indexes that describe sequences of words in elements at load (or reindex) time. Without this index, MarkLogic Server will still perform phrase searches, just more slowly. Turn this index off if only a small percentage of your queries will contain phrase searches at the element level, and if conserving disk space and enhancing load speed is more important than the performance of those queries. |
element value positions |
Off (index is not built) | Speeds up the performance of proximity queries that use the Turn this index off if you are not interested in proximity queries and if you want to conserve disk space and decrease loading time. |
attribute value positions |
Off (index is not built) | Speeds up the performance of proximity queries that use the Turn this index off if you are not interested in proximity queries and if you want to conserve disk space and decrease loading time. |
field value searches |
Off (index is not built) | Speeds up the performance of field value searches that use the Turn this index off if you are not interested in field value queries and if you want to conserve disk space and decrease loading time. |
field value positions |
Off (index is not built) | Speeds up the performance of proximity queries that use the Turn this index off if you are not interested in proximity queries and if you want to conserve disk space and decrease loading time. |
trailing wildcard searches |
Off (index is not built) | Speeds up wildcard searches where the search pattern contains the wildcard character at the end (for example, abc*). Turn this index on to speed up wildcard searches that match a trailing wildcard. The trailing wildcard search index uses roughly the same space as the three character searches index, but is more efficient for trailing wildcard queries. It does not speed up queries where the wildcard character is at the beginning of the term. |
trailing wildcard word positions |
Off (index is not built) | Speeds up the performance proximity queries that use trailing-wildcard word searches, such as wildcard queries that use the Turn this index on if you are using trailing wildcard searches and proximity queries together in the same search. |
fast element trailing wildcard searches |
Off (index is not built) | Faster wildcard searches with the wildcard at the end of the search pattern within a specific element, but slower document loads and larger database files. |
three character searches |
Off (index is not built) | Speeds up wildcard searches where the search pattern contains three or more consecutive non-wildcard characters (for example, When character indexing is turned on, performance is also improved for Turn this index on if you want to enable wildcard searches that match three or more characters. If you need wildcard searches to match only two or one characters, then you should enable two character searches and/or one character searches. |
three character word positions |
Off (index is not built) | Speeds up the performance of proximity queries that use three-character word searches, such as queries that use the Turn this index on if you are using wildcard searches and proximity queries together in the same search. |
two character searches |
Off (index is not built) | Enables wildcard searches where the search pattern contains two or more consecutive non-wildcard characters. For details on wildcard characters, see Understanding and Using Wildcard Searches in the Application Developer's Guide. When character indexing is turned on in the database, the system also delivers higher performance for Turn this index on to speed up wildcard searches that match two or more characters (for example, |
one character searches |
Off (index is not built) | Speeds up wildcard searches where the search pattern contains only a single non-wildcard character. For details on wildcard characters, see Understanding and Using Wildcard Searches in the Application Developer's Guide. When character indexing is turned on in the database, the system also delivers higher performance for Turn this index on if you want to enable wildcard searches that match one or more characters (for example, |
fast element character searches |
Off (index is not built) | Turn this index on to improve performance of wildcard searches that query specific XML elements or JSON properties. Also, speeds up element-based wildcard searches. Turn this index on to improve performance of wildcard searches that query specific elements. For details on wildcard characters, see Understanding and Using Wildcard Searches in the Application Developer's Guide. |
word lexicons |
Off (index is not built) | Maintains a lexicon of all of the words in a database, with uniqueness determined by a specified collation. For details on lexicons, see Range Indexes and Lexicons and the chapter on lexicons in the Application Developer's Guide. For details on collations, see the Language Support in MarkLogic Server chapter in the Search Developer's Guide. Speeds up wildcard searches. Works in combination with any other available wildcard indexes to improve search index resolution and performance. When used in conjunction with the |
uri lexicon |
On (index is built) | Maintains a lexicon of all of the URIs used in a database. The URI lexicon speeds up queries that constrain on URIs. It is like a range index of all of the URIs in the database. To access values from the URI lexicon, use the cts:uris or cts:uri-match APIs. |
collection lexicon |
On (index is built) | Maintains a lexicon of all of the collection URIs used in a database. The collection lexicon speeds up queries that constrain on collections. It is like a range index of all of the collection URIs in the database. To access values from the collection lexicon, use the cts:collections or cts:collection-match APIs. |
Viewing Text Index Configuration
To view text index configuration for a particular database, complete the following procedure:
- Click on the Databases icon on the left tree menu.
- Locate the database for which you want to view text index configuration settings, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to view the settings.
- Scroll down until the text index settings are visible. The following screen shots show the default configuration of text indexing for a database:



Configuring Text Indexes
To configure text indexes for a particular database, complete the following procedure:
- Click on the Databases icon on the left tree menu.
- Locate the database for which you want to view text index configuration settings, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to view the settings.
- Scroll down until the text indexing controls are visible.
- Configure the text indexes for this database by selecting the appropriate radio buttons for each index type.
Click on the
trueradio button for a particular text index type if you want that index to be maintained. Click on thefalseradio button for a particular text index type if you do not want that index to be maintained.If word searches and stemmed searches are disabled (that is, the
falseradio button is selected forword searchesand off is selected forstemmed searches), the settings for the other text indexes are ignored, as explained above. - Leave the rest of the parameters unchanged.
- Scroll to the top or bottom of the right frame and click OK.
Phrasing and Element-Word-Query Boundary Control
MarkLogic Server allows you to specify how XML element constructors impact text phrasing and element-word-query boundaries for searches. This section has the following parts:
Phrasing Control
By default, MarkLogic Server assumes that any XML element constructor acts as a phrase boundary. This means that phrase searches (for example, searches for sequences of terms) will not match a sequence of terms that contains one or more XML element constructors. Phrasing control lets you specify which XML elements should be transparent to phrase boundaries (for example, a bold or italic element), and which XML elements should be ignored for phrase purposes (for example, footnotes or graphic captions).
For example, consider the following sample XML fragment:
<paragraph> These two words <italic>are italicized</italic>. The italic element <footnote>Elements are defined in the W3C XML standard.</footnote> is a standard part of this document's schema. </paragraph>
By default, MarkLogic Server would extract the following five sequences of text for phrase matching purposes (ignoring punctuation and case for simplicity):
- these two words
- are italicized
- the italic element
- elements are defined in the w3c xml standard
- is a standard part of this document's schema
If you then attempted to match the phrases words are italicized or element is a standard part against this XML fragment, no matches would be found, because of the embedded XML element constructors.
In fact, a human looking at this XML fragment would realize that the italic element should be transparent for phrasing purposes, and that the footnote element is a completely independent text container. Seen from this viewpoint, the XML fragment shown above contains only two text sequences (again, ignoring punctuation and case for simplicity):
- these two words are italicized the italic element is a standard part of this document's schema
- elements are defined in the w3c xml standard
In this case, words are italicized and element is a standard part would each properly generate a match. But a search for the w3c xml standard is a standard would not result in a match.
MarkLogic Server lets you achieve this type of phrasing control by specifying particular XML element names as phrase-through, phrase-around, and element-word-query-through elements:
Phrase controls are configured on a per-database basis. You should complete this configuration before loading any documents into the specified database; otherwise, in order for the changes to take effect with your existing content, you must either reload the content or reindex the database after changing the configuration.
Element Word Query Throughs
Element-word-query-throughs allow you to specify elements that should be included in text searches that use cts:element-word-query on a parent element. For example, consider the following XML fragment:
<a> <b>hello</b> <c>goodbye</c> </a>
If you perform a cts:element-word-query on <a> searching for the word hello, the search does not find any matches in this fragment. The following query shows this pattern:
cts:search(fn:doc(), cts:element-word-query(xs:QName("a"), "hello"))
This query does not find any matches because cts:element-word-query only searches for text nodes that are immediate children of the element <a>, not text nodes that are children of any child nodes of <a>. Because hello is in a text node that is a child of <b>, it does not satisfy the cts:element-word-query.
If you add an element-word-query-through for the element <b>, however, then the cts:element-word-query on <a> searching for the word hello returns a match. The element-word-query-through on <b> causes the text node children of <b> behave like the text node children of its parent (in this case, <a>).
If an element is specified as a phrase-through, then it also behaves as an element-word-query-through, and therefore you do not need to specify it as an element-word-query-through.
Procedures
Use the following procedures to configure phrase controls for a particular database:
- Viewing Phrasing and Element-Word-Query Settings
- Configuring Phrasing and Element-Word-Query Settings
- Deleting a Phrasing or Element-Word-Query Setting
Viewing Phrasing and Element-Word-Query Settings
To view element-word-query-through, phrase-through, and phrase-around settings for a particular database, complete the following procedure in the Admin Interface:
- Click on the Databases icon on the left tree menu.
- Locate the database for which you want to view element-word-query-through, phrase-through, or phrase-around settings, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to view the settings.
- Click the Element-Word-Query-Throughs, Phrase-Throughs, or Phrase-Arounds icon, depending on which one you want to view.
- The configuration page displays.
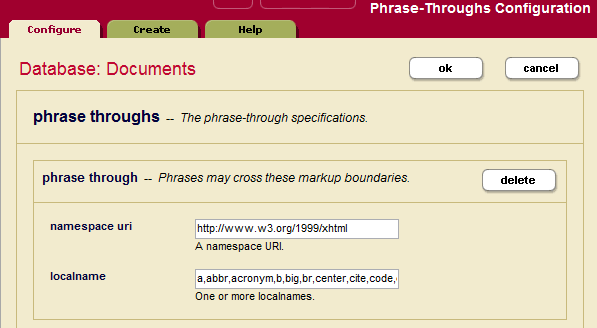
The following example shows that the Documents database has been configured with a number of phrase-through elements, including the <abbr>, <acronym>, <b>, <big>, <br> and <center> elements of the XHTML namespace:
Configuring Phrasing and Element-Word-Query Settings
To configure element-word-query-through, phrase-through, and phrase-around settings for a particular database, perform the following procedure in the Admin Interface:
- Click the Databases icon in the left tree menu.
- Locate the database for which you want to configure element-word-query-through, phrase-through, or phrase-around settings, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to configure the settings.
- Click the Element-Word-Query-Throughs, Phrase-Throughs, or Phrase-Arounds icon, depending on which one you want to configure.
The remainder of this procedure will assume that you have chosen to configure phrase-through settings. If you wish to configure phrase-around or element-word-query-through settings, the steps are completely analogous, once you have clicked on the corresponding icon.
- Click the Create tab at the top right. The Phrase-Throughs Configuration page displays:
- Enter the namespace URI of the XML element that you are specifying as a phrase-through element.
Every XML element is associated with a namespace. For the phrase-through setting to be precise, you must specify the namespace of the XML element. Leaving the namespace URI field blank specifies the universal unnamed namespace.
Alternatively, you can specify that the element is namespace independent by putting an asterisk (*) in the namespace URI field.
- Enter the element name in the local name field.
The local name is the name of the XML element that you are specifying as a phrase-through element. If you want to specify more than one element that is associated with the specified namespace, you can provide a comma-separated list of element names.
- To add more phrase-throughs, click the More Items button and repeat steps 6 and 7 for each phrase-through element as needed.
- Scroll to the top or bottom and click OK.
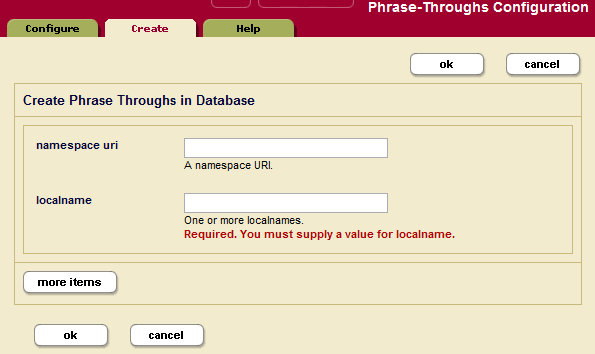
The new phrase-through is added.
If you change the element-word-query-through, phrase-through, or phrase-around settings for a particular database after documents have already been loaded, you should reindex your existing data, either by setting the reindexer enable setting to true for that database or by reloading the data.
Deleting a Phrasing or Element-Word-Query Setting
To delete an element-word-query-through, phrase-through, or phrase-around setting for a particular database, perform the following procedure in the Admin Interface:
- Click the Databases icon in the left tree menu.
- Locate the database for which you want to delete element-word-query-through, phrase-through, or phrase-around settings, either in the tree menu or in the Database Summary table.
- Click the name of the database for which you want to delete the settings.
- Click the Element-Word-Query-Throughs, Phrase-Throughs, or Phrase-Arounds icon, depending on which one you want to delete.
- Scroll down to the element that you want to delete.
- Click the Drop button next to the element that you want to delete.
- Confirm the delete operation and click OK.
The Phrase-Through or Phrase-Around element is deleted from the database.
If you change the element-word-query-through, phrase-through, or phrase-around settings for a particular database after documents have already been loaded, you should reindex your existing data, either by setting the
reindexer enablesetting totruefor that database or by reloading the data.
Query Behavior with Reindex Settings Enabled and Disabled
When you load a document into a database, it is indexed based on the index settings at the time of the load. When you issue a query to a database, it is evaluated based on a consistent view of the index settings. This consistent view might not include all of the index features that are enabled in the database. This section describes the behavior of queries at various index-setting states of the database, and includes the following parts:
- Understanding the Reindexer Enable Settings
- Query Evaluation According to the Lowest Common Denominator
- Reindexing Does Not Apply to Point-In-Time Versions of Fragments
- Example Scenario
Understanding the Reindexer Enable Settings
At the database level, you can enable or disable automatic reindexing by setting the reindexer enable setting to true or false for that database. When the reindexer is enabled, any index or fragment changes to the database settings will cause all documents in the database that are not indexed/fragmented according to the settings to initiate a reindex operation. Note the following about the database settings and the reindex operation:
- When reindexing is enabled, the reindex operation runs as a background task. You can set a higher or lower priority on the reindexing task by increasing or decreasing the setting of the
reindexer throttle. - Any new documents added to or updated in the database will get the new database settings. This is true both with reindexing enabled and with reindexing disabled.
- After changing index or fragmentation settings in a database, because new or modified documents get the new settings, the database can get into a state where some documents are indexed/fragmented differently from other documents in the database.
- After changing index or fragmentation settings in a database in which reindexing is enabled, the old documents are reindexed according to the new settings, but the new settings do not take effect for queries until the reindex operation has completed and all documents are indexed to the state matching the database settings.
- After changing index or fragmentation settings in a database in which reindexing is disabled, new and changed documents get the current settings, but queries will not take advantage of the new settings until all documents in the database match the database settings.
- Even if reindexing is disabled, when you add tokenizer overrides to a field, those tokenization changes take effect immediately, so all new queries against the field will use the new tokenization (even if it is indexed with the previous tokenization).
Query Evaluation According to the Lowest Common Denominator
When queries are evaluated, they use the index settings that are calculated for the database at a given time. The current index settings for a query are determined at the time of query evaluation, and are based on the lowest common denominator of (that is, the index/fragmentation settings that are the least of) the following:
- The index/fragmentation settings defined in the database configuration.
- The actual index/fragmentation of documents/fragments in the database.
At any given time, the current lowest common denominator is invalidated upon the following events:
- system startup
- a change to the database configuration settings
- when a reindexing operation completes
If the lowest common denominator is invalidated, it is recalculated the next time a query is issued against the database.
The net impact is that, when index/fragmentation settings have changed on a database after any data is loaded, queries cannot take advantage of the new settings until the new settings meet the lowest common denominator criteria. Depending on the types of index setting changes you make, this can cause queries that behaved one way before index settings were changed to behave differently after the changes. The next section provides a sample scenario to help illustrate this behavior.
Reindexing Does Not Apply to Point-In-Time Versions of Fragments
If you have set a merge timestamp on the database to retain older versions of fragments for point-in-time queries, the older versions of the fragments will retain the indexing properties of the database at the time when they were updated. Because of this, reindexing a database that uses point-in-time queries can cause unpredictable query results. MarkLogic recommends that you do not reindex a database that has the merge timestamp parameter set to anything but 0. For details on point-in-time queries, see the Point-In-Time Queries chapter in the Application Developer's Guide. For details on setting the merge timestamp parameter, see Merges and Point-In-Time Queries.
Example Scenario
This section describes a simple scenario showing the effect of changing index settings on query behavior over time.
The following figure shows how changing the index settings can effect queries that initiate after index setting changes occur.

In this scenario, the query issued at time T3 sees the doc1 document with stemming and 3-character wildcard indexes enabled. Wildcard queries such as abc* will be successful. The same wildcard query at time T5, however, will not be successful, because the 3-character index (which is required for the abc* query) was disabled at time T4. Note that the document doc1 is actually indexed with 3-character and stemming, but the query at time T5 only is able to use the stemming index. At time T7, the database has doc1 indexed with both stemming and 3-character indexes, but doc2 only has the stemming index. With reindexing disabled, the query at T7 will use the lowest common denominator, which is in this case stemming.