
MarkLogic Server 11.0 Product DocumentationSearch Developer's Guide — Chapter 15
Entity Extraction and Enrichment
This chapter describes how to perform entity extraction or enrichment in MarkLogic Server. You can use these features to identify entities such as people and places in text, and then either add markup around the entities in your documents or extract a list of entities. You can use entity enrichment and extraction to classify documents and improve search accuracy.
This chapter covers the following topics:
- Overview of Entity Extraction and Enrichment
- Understanding Dictionary-Based Extraction and Enrichment
- Creating an Entity Dictionary
- Dictionary-Based Entity Enrichment
- Dictionary-Based Entity Extraction
- Using an Entity Type Map for Extraction or Enrichment
- Overlapping Entity Match Handling
- Entity Identification Using Reverse Query
- Entity Enrichment Pipelines
Overview of Entity Extraction and Enrichment
Entity extraction and entity enrichment are the process of identifying words or phrases that represent logical or business entities, and then either extracting a list of the entities from your content or enriching the content with information about the entities. Many industries have domain-specific entities that are useful to identify, such as extracting or marking up references to prescription drugs in patient history documents.
The following diagram illustrates the extraction process at a high level. Suppose you have entity rules that say the term Nixon represents a person entity and the term Paris represents a place entity. Then you could use the rules to extract a person and a place entity from the phrase Nixon visited Paris in an XML document:
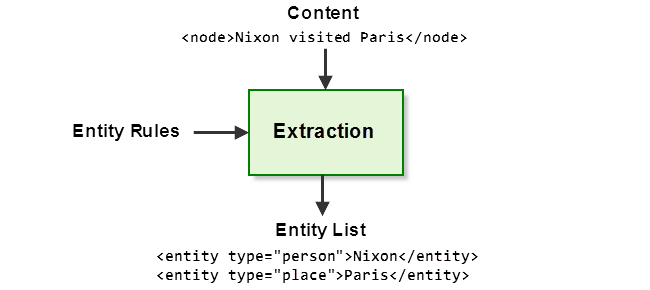
Similarly, you could use the rules to enrich the phrase Nixon visited Paris with markup around the person and place entities:
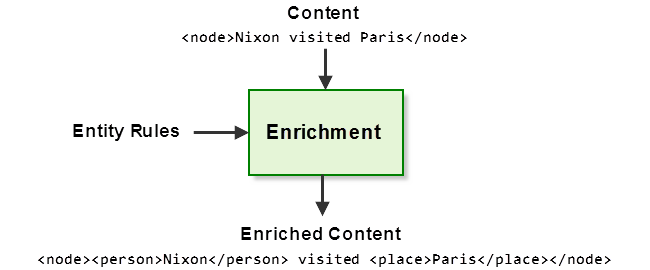
MarkLogic provides out-of-the-box support for expressing entity rules as an opaque entity dictionary or a search query. MarkLogic APIs support both approaches. You can create dictionaries in various ways, including deriving one from a Simple Knowledge Organization System (SKOS) ontology.
You can also use third-party entity enrichment services by integrating them into a the Content Processing Framework (CPF) pipeline. MarkLogic includes some sample entity enrichment pipelines; for details, see Entity Enrichment Pipelines.
The following table can help you select the right extraction or enrichment approach for your application:
| Use Case | Recommended Interface |
|---|---|
| Your entities can be identitied using simple string matching | Entity dictionaries and the entity enrichment and extraction APIs described in this chapter. For details, see Understanding Dictionary-Based Extraction and Enrichment. |
| Your entities can best be described by a cts query, or you require advanced string matching such as stemming or diacritic sensitivity | Reverse query and cts:highlight or cts.highlight. For more details, see Entity Identification Using Reverse Query. |
| You want to use a 3rd party entity extraction library | A Content Processing Framework (CPF) pipeline. For more details, see Entity Enrichment Pipelines. |
Understanding Dictionary-Based Extraction and Enrichment
MarkLogic comes with a set of built-in and library module functions that support basic entity extraction and enrichment using entity dictionaries.
These interfaces can only be used when simple codepoint equality can be used to identify entity matches. You can control whether the comparison should be case sensitive, but you cannot use pattern matching, stemming, or diacritic sensitivity. If you need such features, use the technique described in Entity Identification Using Reverse Query.
You can create an entity dictionary from tab-delimited text, from a SKOS ontology, or from a set of entity objects created using cts:entity (XQuery) or cts.entity (JavaScript). For more details, see Creating an Entity Dictionary.
Once you create a dictionary that describes your entities, you can use it for operations such as the following:
- Extract entities from text as XML nodes constructed by MarkLogic or with custom markup. For details, see Dictionary-Based Entity Extraction.
- Enrich text with markup constructed by MarkLogic or with custom markup. For more details, see Dictionary-Based Entity Enrichment.
The following table summarizes the entity dictionary-based built-in and library functions. The functions in the entity library module provide an easy-to-use interface with limited customization options. The built-in cts functions provide finer control, at the cost of increased complexity.
| Operation | XQuery | Server-Side JavaScript |
|---|---|---|
| Dictionary Management | ||
| Content Enrichment | ||
| Entity Extraction |
Creating an Entity Dictionary
This section covers the following topics related to entity dictionary creation:
- Understanding Entity Dictionaries
- Creating a Dictionary Using Entity Constructors
- Creating a Dictionary From Text
- Creating a Dictionary From a SKOS Ontology
- Persisting or Retrieving an Entity Dictionary
- Serializing a Dictionary as Text
Understanding Entity Dictionaries
An entity dictionary is a set of entity definitions that specify the following characteristics of each entity:
- entity id - A unique id for the entity.
- normalized text - The normalized form of the entity.
- text - The word or phrase to match against this entry during entity extraction.
- entity type - The type of the entity.
You can create an entity dictionary in memory from the following sources.
- A Simple Knowledge Organization System (SKOS) ontology, stored in MarkLogic as a graph. For details, see Creating a Dictionary From a SKOS Ontology.
- Tab-delimited text. For details, see Creating a Dictionary From Text.
- A sequence of cts:entity (XQuery) or cts.entity (Server-Side JavaScript) objects. For details, see Creating a Dictionary Using Entity Constructors.
For efficient re-use, you should persist your entity dictionaries in MarkLogic. For details, see Persisting or Retrieving an Entity Dictionary.
When you use the dictionary-based APIs, such as entity:enrich or entity.enrich, matching is based on strict codepoint equality. You can only tailor the matching by specifying whether or not matches against a given dictionary should be case-insensitive. You cannot use an entity dictionary to find matches that depend on pattern matching, stemming, or other advanced algorithms.
A dictionary can contain multiple entries for the same entity id. For example, suppose former United States President Richard Nixon is a logical entity in your application domain. You might create dictionary entries that specify the phrases Richard Nixon, Richard M. Nixon, and President Nixon resolve to equivalent entities, with the same id, entity type, and normalized text. That is, you might create a dictionary that includes the following entries:
| Id | Normalized Text | Text | Type |
|---|---|---|---|
| 11208172 | Nixon | Richard M. Nixon | person |
| 11208172 | Nixon | Richard Nixon | person |
| 11208172 | Nixon | President Nixon | person |
Thus, entity extraction or enrichment can map any of the phrases Richard M. Nixon, Richard Nixon, and President Nixon to the person entity with the id 11208172.
If your dictionary includes entries whose text overlaps, then multiple entries can match overlapping portions of a text node. For example, if your dictionary contains both President Nixon and Nixon Library, applying the dictionary to the phrase President Nixon Library results in overlapping entity matches. You can use the dictionary creation options allow-overlaps and remove-overlaps to affect overlap handling. The default behavior is allow-overlaps. For more details, see Overlapping Entity Match Handling.
Creating a Dictionary Using Entity Constructors
In XQuery, you can use cts:entity to construct opaque dictionary entry objects, and then use cts:entity-dictionary to create an in-memory entity dictionary from them.
In Server-Side JavaScript, you can use cts.entity to construct opaque dictionary entry objects, and then use cts.entityDictionary to create an in-memory entity dictionary from them.
For example, the following example construct an in-memory entity dictionary contianing four entries:
You can persist the dictionary in MarkLogic using cts:dictionary-insert (XQuery) or cts.dictionaryInsert (JavaScript). For details, see Persisting or Retrieving an Entity Dictionary.
Creating a Dictionary From Text
You can construct an entity dictionary from specially formatted text using cts:entity-dictionary-parse (XQuery) or cts.entityDictionaryParse (JavaScript). The input must be strings containing dictionary entry lines of the following form. Dictionary entries must be newline separated, and the fields of entry must be tab separated.
id normalizedText text entityType
This is the same format produced when you serialize a dictionary; for details, see Serializing a Dictionary as Text.
For example, suppose you have a file /my/ent-dict.txt on the filesystem containing the following lines of tab-delimited text:
11208172 Nixon Nixon person:head of state 11208172 Nixon Richard Nixon person:head of state 09145751 Paris Paris administrative district:town 09500217 Paris Paris imaginary being:mythical being
Then the following example code creates an in-memory entity dictionary from the file contents.
You can persist such an in-memory dictionary in MarkLogic using entity:dictionary-insert (XQuery) or entity.dictionaryInsert (JavaScript). You can also load the text representation of an entity dictionary directly into MarkLogic using entity:dictionary-load (XQuery) or entity.dictionaryLoad (JavaScript). For details, see Persisting or Retrieving an Entity Dictionary.
Creating a Dictionary From a SKOS Ontology
You can create an entity dictionary from a Simple Knowledge Organization System (SKOS) ontology. A SKOS is a semantic graph composed of RDF triples; for details, see https://www.w3.org/TR/skos-primer/. SKOS ontologies are available for many application domains. A SKOS ontology includes exactly the kind of information used in a MarkLogic entity dictionary entry: An entity ID, with one or more matching terms, a normalized form, and an entity type.
Use the following steps to create an entity dictionary from a SKOS ontology:
- Insert the graph representing the ontology into MarkLogic, as described in Loading Semantic Triples in the Semantic Graph Developer's Guide.
- Use the library function entity:skos-dictionary (XQuery) or entity.skosDictionary (JavaScript) to create a dictionary from the graph.
A dictionary entry is created for each skos:Concept in the graph, where skos is shorthand for the namespace http://www.w3.org/2004/02/skos/core#. Dictionary entries will not be extracted for triples that use any other SKOS namespace.
The following table provides an overview of the mapping from SKOS properties to dictionary entry attributes. For more details on the mapping, see the function reference for entity:skos-dictionary (XQuery) or entity.skosDictionary (JavaScript).
For example, suppose you have a file on the filesystem with path /examples/canal.rdf that contains the following simplified SKOS ontology:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:skos="http://www.w3.org/2004/02/skos/core#"> <skos:Concept rdf:about="http://www.my.com/#canals"> <skos:definition>A feature type category for places such as the Erie Canal</skos:definition> <skos:prefLabel>canals</skos:prefLabel> <skos:altLabel>canal bends</skos:altLabel> <skos:altLabel>canalized streams</skos:altLabel> <skos:altLabel>ditch mouths</skos:altLabel> <skos:altLabel>ditches</skos:altLabel> <skos:altLabel>drainage canals</skos:altLabel> <skos:altLabel>drainage ditches</skos:altLabel> <skos:broader rdf:resource="http://www.my.com/#hydrographic%20structures"/> <skos:related rdf:resource="http://www.my.com/#channels"/> <skos:related rdf:resource="http://www.my.com/#locks"/> <skos:related rdf:resource="http://www.my.com/#transportation%20features"/> <skos:related rdf:resource="http://www.my.com/#tunnels"/> <skos:scopeNote>Manmade waterway used by watercraft or for drainage, irrigation, mining, or water power</skos:scopeNote> </skos:Concept> </rdf:RDF>
Then you can load the ontology into a graph in MarkLogic with the URI http://marklogic.com/examples/canal as follows:
Now, you can create an entity dictionary from the graph and save it in MarkLogic as shown by the following example. Note that your dictionary URI should not be the same as the graph URI. To learn more about creating graphs in MarkLogic, see Semantic Graph Developer's Guide.
The resulting entity dictionary contains the following entries. All the terms share the same entity type because the trivial example onotology defines only one concept.
Persisting or Retrieving an Entity Dictionary
For best performance, large dictionaries and dictionaries you use frequently should be stored in MarkLogic. To persist a dictionary in the database, use the following functions:
- entity:dictionary-insert (XQuery) or entity.dictionaryInsert (JavaScript): Save an in-memory dictionary in the database.
- entity:dictionary-load (XQuery) or entity.dictionaryLoad (JavaScript): Read in dictionary entries from a tab-delimited text file and save the results in the database. For format details, see Creating a Dictionary From Text.
For example, the following code creates an in-memory dictionary using entity constructors, and then saves it in the database:
The following example loads a properly serialized dictionary on the filesystem directly into MarkLogic. The expected format is the same as that described in Creating a Dictionary From Text and Serializing a Dictionary as Text.
To retrieve a dictionary stored in MarkLogic, use cts:entity-dictionary-get (XQuery) or cts.entityDictionaryGet (JavaScript).
Serializing a Dictionary as Text
You can serialize an entity dictionary as text, suitable for exporting to a file. You can use cts:entity-dictionary-parse or cts.entityDictionaryParse to re-create a cts:entity-dictionary object from the serialization.
The following example serializes an in-memory dictionary:
This example produces the following output. Each serialized dictionary entry is separated by a newline. Each field within an entry is separated by a TAB character. The first line, with the ## prefix, encodes the options used to create the dictionary.
## remove-overlaps case-insensitive 11208172 Nixon Nixon person 11208172 Nixon Richard Nixon person 09145751 Paris Paris district:town 09500217 Paris Paris mythical being
Dictionary-Based Entity Enrichment
Entity enrichment is the process of adding markup to a document that identifies the occurrence of entities in the text. MarkLogic provides a set up of APIs that enable you to define the set of possible entities in one or more entity dictionaries, and then tag matching entities in your XML documents. To generate a list of entities found in a document rather than add enrichment, use entity extraction; for details, see Dictionary-Based Entity Extraction.
This section covers the following topics related to using the dictionary-based APIs for entity enrichment:
- API Summary
- Using entity:enrich or entity.enrich
- Using cts:entity-highlight or cts.entityHighlight
- XQuery Example: entity:enrich
- XQuery Example: cts:entity-highlight
- JavaScript Example: entity.enrich
- JavaScript Example: cts.entityHighlight
API Summary
The following table summarizes the dictionary-based APIs available for adding entity enrichment to your XML documents. These APIs require you to create one or more entity dictionaries, as described in Creating an Entity Dictionary.
| Function | Description |
|---|---|
entity:enrich (XQuery) entity.enrich (JavaScript) |
Enclose words and phrases matching dictionary entries in a wrapper element decorated with the entity type. Some customization is available. |
cts:entity-highlight (XQuery) cts.entityHighlight (JavaScript) |
Replace words and phrases matching dictionary entries with content of your choosing. |
The enrich function is the easiest to use, and suitable for many applications. Use cts:entity-highlight or cts.entityHighlight if you require fine-grained control over the enrichment.
Using entity:enrich or entity.enrich
When you call entity:enrich or entity.enrich with just an input node and one or more dictionaries, MarkLogic wraps matched text in an <entity/> element that has a type attribute whose value is the entity type from the matching dictionary entry.
For example, if you call enrich in the form shown below:
Then the enrichment uses a wrapper such as the following:
<e:entity xmlns:e="http://marklogic.com/entity"> type="person:head of state">Nixon</e:entity>
For a complete example, see XQuery Example: entity:enrich or JavaScript Example: entity.enrich.
You can further tailor the enrichment as follows:
- Use the full option to decorate the wrapper element with additional information from the matched dictionary entry, such as the entity id and normalized text.
- Pass in a mapping between entity type names and element QNames to change the QName of the wrapper element. For details, see Using an Entity Type Map for Extraction or Enrichment.
If you pass multiple dictionaries to enrich, then the dictionaries are applied in turn, in the order provided.
For example, suppose you have an entity dictionary that defines the word Nixon as an entity of type person:head of state. Further, suppose you define a mapping from person:head of state to the QName entity:vip. Then, the following table summarizes different forms of enrichment available using entity:enrich or entity.enrich.
If this level of customization does not meet the needs of your application, see Using cts:entity-highlight or cts.entityHighlight.
Using cts:entity-highlight or cts.entityHighlight
The XQuery function cts:entity-highlight and the JavaScript function cts.entityHighlight give you complete control over construction of enriched content, at the cost of somewhat greater complexity.
The cts:entity-highlight XQuery function accepts a block of inline XQuery code that gets evaluated for each entity match. Use this code block to construct your enrichment. Nodes returned by your inline code are inserted into the final result.
The cts.entityHighlight JavaScript function accepts a callback function as a parameter. Your function gets called for each entity match. Your callback adds enriched content to the final result by interacting with the NodeBuilder passed in by MarkLogic.
In both XQuery and JavaScript, details about the matching dictionary entry are made available to your generator code. For details, see the function reference documentation for cts:entity-highlight and cts.entityHighlight.
For example, the following snippets use the entity type and matched text information provided by Marklogic to construct enriched replacement content for the matched text.
For a complete example, see XQuery Example: cts:entity-highlight or JavaScript Example: cts.entityHighlight.
XQuery Example: entity:enrich
This example uses entity:enrich to add entity-based markup to XML content, as described in Using entity:enrich or entity.enrich. The example demonstrates the use of various customization features of entity:enrich.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses the dictionary add enrichment around the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary. The input node can also be an XML document or other node in MarkLogic.
Copy and paste the following code into Query Console, set the Query Type to XQuery, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
xquery version "1.0-ml"; import module namespace entity="http://marklogic.com/entity" at "/MarkLogic/entity.xqy"; let $dictionary := cts:entity-dictionary(( cts:entity("11208172", "Nixon", "Nixon", "person:head of state"), cts:entity("11208172", "Nixon", "Richard Nixon", "person:head of state"), cts:entity("11208172", "Nixon", "Richard M. Nixon", "person:head of state"), cts:entity("11208172", "Nixon", "Richard Milhous Nixon", "person:head of state"), cts:entity("11208172", "Nixon", "President Nixon", "person:head of state"), cts:entity("08932568", "Paris", "Paris", "administrative district:national capital"), cts:entity("09145751", "Paris", "Paris", "administrative district:town"), cts:entity("09500217", "Paris", "Paris", "imaginary being:mythical being") )) let $mapping := map:new(( map:entry("",xs:QName("entity:entity")), map:entry("administrative district",xs:QName("entity:gpe")), map:entry("person", map:map() => map:with("", xs:QName("entity:location")) => map:with("head of state", xs:QName("entity:vip"))) )) let $input-node := <node>Nixon visited Paris</node> return ( "------- default -------", entity:enrich($input-node, $dictionary), "------- full option -------", entity:enrich($input-node, $dictionary, "full"), "------- mapping -------", entity:enrich($input-node, $dictionary, (), $mapping), "------- full + mapping -------", entity:enrich($input-node, $dictionary, "full", $mapping) )
You should see output similar to the following. (Whitespace has been added to improve readability. The enrichment does not introduce new whitespace or comments.)
------- default ------- <node xmlns:e="http://marklogic.com/entity"> <e:entity type="person:head of state">Nixon</e:entity> visited <e:entity type="administrative district:national capital">Paris</e:entity> </node> ------- full option ------- <node xmlns:e="http://marklogic.com/entity"> <e:entity id="11208172" norm="Nixon" type="person:head of state">Nixon</e:entity> visited <e:entity id="08932568" norm="Paris" type="administrative district:national capital">Paris </e:entity> </node> ------- mapping ------- <node xmlns:entity="http://marklogic.com/entity"> <entity:vip>Nixon</entity:vip> visited <entity:gpe>Paris</entity:gpe> </node> ------- mapping ------- <node xmlns:entity="http://marklogic.com/entity"> <entity:vip id="11208172" norm="Nixon">Nixon</entity:vip> visited <entity:gpe id="08932568" norm="Paris">Paris</entity:gpe> </node>
XQuery Example: cts:entity-highlight
This example illustrates how you can use cts:entity-highlight to enrich content when you need more control than that provided by entity:enrich. For details, see Using cts:entity-highlight or cts.entityHighlight.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses the dictionary add enrichment around the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary. The input node can also be an XML document or other node in MarkLogic.
Copy and paste the following code into Query Console, set the Query Type to XQuery, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
xquery version "1.0-ml"; let $dictionary := cts:entity-dictionary(( cts:entity("11208172","Nixon","Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard M. Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard Milhous Nixon", "person:head of state"), cts:entity("11208172","Nixon","President Nixon","person:head of state"), cts:entity("08932568","Paris","Paris", "administrative district:national capital"), cts:entity("09145751","Paris","Paris","administrative district:town"), cts:entity("09500217","Paris","Paris","imaginary being:mythical being") )) let $input-node := <node>Nixon visited Paris</node> return cts:entity-highlight( $input-node, (if ($cts:text ne "") then element { fn:replace($cts:entity-type, ":| ", "-") } { $cts:text } else ()), $dictionary)
The example produces the following output. Whitespace has been added to improve readability. The enrichment does not introduce new whitespace.
<node> <person-head-of-state>Nixon</person-head-of-state> visited <administrative-district-national-capital>Paris</administrative-district-national-capital> </node>
Each time cts:entity-highlight identifies a word or phrase that matches a dictionary entry, it evaluates the expression passed in as the second parameter. The example code simiply generates an entity wrapper that uses the entity type name as the wrapper element QName, after replacing any occurrences of ":" or " " with a dash ("-").
element { fn:replace($cts:entity-type, ":| ", "-") } { $cts:text }
The special variables $cts:text and $cts:entity-type are populated with information from the matching dictionary entry. Your code has access to other data from the matching dictionary entry, such as the normalized text ($cts:entity-id) and the entity id ($cts:entity-id). For details, see the function reference for cts:entity-highlight.
If text matches more than one dictionary entry, your code is evaluated for each match, but $cts:text will be empty for all but the first match. The example as given tests for an empty $cts:text and only generates replacement content for the first match.
if ($cts:text ne "") then element { fn:replace($cts:entity-type, ":| ", "-") } { $cts:text } else ()
For example, the term Paris matches 3 entries in the dictionary. If you remove the empty string test, as follows:
cts:entity-highlight( $input-node, (element { fn:replace($cts:entity-type, ":| ", "-") } { $cts:text }), $dictionary)
Then the example produces the following element related to the term Paris. The same wrapper is generated for the first match, but the subsequent matches insert an entity tag with no text content.
<administrative-district-national-capital>Paris</administrative-district-national-capital> <administrative-district-town/> <imaginary-being-mythical-being/>
JavaScript Example: entity.enrich
This example uses entity.enrich to add entity-based markup to XML content, as described in Using entity:enrich or entity.enrich. The example demonstrates the use of various customization features of entity.enrich.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses the dictionary add enrichment around the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary. The input node can also be an XML document or other node in MarkLogic.
Copy and paste the following code into Query Console, set the Query Type to JavaScript, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
'use strict'; const entity = require('/MarkLogic/entity'); // NOTE: The fields of each string below must be TAB separated. const dictionary = cts.entityDictionary([ cts.entity('11208172','Nixon','Nixon','person:head of state'), cts.entity('11208172','Nixon','Richard Nixon','person:head of state'), cts.entity('11208172','Nixon','Richard M. Nixon','person:head of state'), cts.entity('11208172','Nixon','Richard Milhous Nixon', 'person:head of state'), cts.entity('11208172','Nixon','President Nixon','person:head of state'), cts.entity('08932568','Paris','Paris', 'administrative district:national capital'), cts.entity('09145751','Paris','Paris','administrative district:town'), cts.entity('09500217','Paris','Paris','imaginary being:mythical being') ]); const mapping = { '' : fn.QName('http://marklogic.com/entity', 'entity:entity'), 'administrative district': fn.QName('http://marklogic.com/entity', 'entity:gpe'), person: { '': fn.QName('http://marklogic.com/entity', 'entity:person'), 'head of state': fn.QName('http://marklogic.com/entity', 'entity:vip') } }; const inputNode = new NodeBuilder() .addElement('node', 'Nixon visited Paris') .toNode(); const result = [ entity.enrich(inputNode, dictionary), entity.enrich(inputNode, dictionary, ['full']), entity.enrich(inputNode, dictionary, null, mapping), entity.enrich(inputNode, dictionary, ['full'], mapping) ]; result;
The example code generates XML of the forms shown below. Whitespace and comments have been added to improve readability. The enrichment does not introduce new whitespace or comments. (Due to the way Query Console formats XML for display, the generated XML appears as strings in the Query Console results window. In fact, they are XML element nodes.)
<!-- default enrichment --> <node xmlns:e="http://marklogic.com/entity"> <e:entity type="person:head of state">Nixon</e:entity> visited <e:entity type="administrative district:national capital">Paris</e:entity> </node> <!-- using the "full" option adds @id and @norm data --> <node xmlns:e="http://marklogic.com/entity"> <e:entity id="11208172" norm="Nixon" type="person:head of state">Nixon</e:entity> visited <e:entity id="08932568" norm="Paris" type="administrative district:national capital">Paris </e:entity> </node> <!-- using the entity type map changes the wrapper elements from -- e:entity to entity:vip and entity:gep --> <node xmlns:entity="http://marklogic.com/entity"> <entity:vip>Nixon</entity:vip> visited <entity:gpe>Paris</entity:gpe> </node> <!-- using the "full" option and the entity type map --> <node xmlns:entity="http://marklogic.com/entity"> <entity:vip id="11208172" norm="Nixon">Nixon</entity:vip> visited <entity:gpe id="08932568" norm="Paris">Paris</entity:gpe> </node>
JavaScript Example: cts.entityHighlight
This example illustrates how you can use cts.entityHighlight to enrich content when you need more control than that provided by entity.enrich. The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses the dictionary add enrichment around the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary. The input node can also be an XML document or other node in MarkLogic.
Copy and paste the following code into Query Console, set the Query Type to JavaScript, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
'use strict'; const dictionary = cts.entityDictionary([ cts.entity('11208172', 'Nixon', 'Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard M. Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard Milhous Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'President Nixon', 'person:head of state'), cts.entity('08932568', 'Paris', 'Paris', 'administrative district:national capital'), cts.entity('09145751', 'Paris', 'Paris', 'administrative district:town'), cts.entity('09145751', 'Paris', 'Paris', 'being:mythical being') ]); const inputNode = new NodeBuilder() .addElement('node', 'Richard Nixon visited Paris.') .toNode(); const resultBuilder = new NodeBuilder(); cts.entityHighlight(inputNodeode, function(builder, entityType, text, normText, entityId, node, start) { if (text != '') { builder.addElement(fn.replace(entityType, ':| ', '-'), text); } }, resultBuilder, dictionary); resultBuilder.toNode();
The example produces the following output. Whitespace has been added to improve readability. The enrichment does not introduce new whitespace.
<node> <person-head-of-state>Nixon</person-head-of-state> visited <district-national-capital>Paris</district-national-capital> </node>
The builder parameter of the callblack contains the NodeBuilder object you pass into cts.entityHighlight. The remaining parameters, such as text and entityType are populated with information from the matching dictionary entry. For details, see the function reference for cts.entityHighlight.
Each time cts.entityHighlight identifies a word or phrase that match a dictionary entry, it invokes the callback function passed in as the second parameter. The example function simiply generates an entity wrapper that uses the entity type name as the wrapper element QName, after replacing any occurrences of ":" or " " with a dash ("-").
builder.addElement(fn.replace(entityType, ':| ', '-'), text)
Note that you are responsible for extracting the final result from the NodeBuilder when the highlighting walk completes. For example, by calling NodeBuilder.toNode().
If text matches more than one dictionary entry, your callback is invoked for each match, but the text parameter will be an empty string for all but the first match. The example as given tests for an empty text string and only generates replacement content for the first match.
function(builder, entityType, text, normText, entityId, node, start) { if (text != '') { builder.addElement(fn.replace(entityType, ':| ', '-'), text); } }
For example, the term Paris actually matches 3 entries in the dictionary. If you remove the empty string test from the callback function, then the example produces the following output. The same wrapper is generated for the first match, but the subsequent matches insert an entity tag with no text content because text parameter is an empty string.
<administrative-district-national-capital>Paris</administrative-district-national-capital> <administrative-district-town/> <being-mythical-being/>
You can control the entity traversal through the value returned by the callback. The default action is continue. If you return skip or break, then you can interrupt the walk. For example, the following call exits the walk after the first match:
function(builder, entityType, text, normText, entityId, node, start) { if (text != '') { builder.addElement(fn.replace(entityType, ':| ', '-'), text); return 'break'; } }
Dictionary-Based Entity Extraction
You can use entity extraction to generate a list of entities from an XML document or other XML node. You define the set of possible entities in one or more entity dictionaries. You can use extracted entities for purposes such as creating searchable metadata or maintaining classification data outside of the original content. To mark up entity data inline, use entity enrichment; for details see Dictionary-Based Entity Enrichment.
This section covers the following topics related to using the dictionary-based APIs for entity extraction:
- API Summary
- Extraction Using entity:extract or entity.extract
- Extraction Using cts:entity-walk or cts.entityWalk
- XQuery Example: entity:extract
- XQuery Example: cts:entity-walk
- JavaScript Example: entity.extract
- JavaScript Example: cts.entityWalk
API Summary
The following table summarizes the dictionary-based APIs available for extracting entities from your XML documents. These APIs require you first to create one or more entity dictionaries, as described in Creating an Entity Dictionary.
| Function | Description |
|---|---|
entity:extract (XQuery) entity.extract (JavaScript) |
Identify entities in a node and extract it as an XML element decorated with the entity type. Some customization of the generated XML is available. |
cts:entity-walk (XQuery) cts.entity-walk (JavaScript) |
Identify entities in a node and extract them in a custom format. |
The entity:extract or entity.extract function generates entity elements of the same form as the replacement content generated by entity:enrich or entity.enrich. The output from extract should satisfy the needs of most applications. If you require more control, you can use cts:entity-walk or cts.entityWalk extraction instead.
Extraction Using entity:extract or entity.extract
When you call entity:extract (XQuery) or entity.extract (JavaScript) with just an input node and one or more entity dictionaries, then the extracted entities are wrapped in an <entity/> element with a type attribute that contains the entity type.
For example, the following element nodes were generated by enrich on content that contained text matching five entity dictionary entries for the terms Richard Nixon, Nixon, and Paris.
<e:entity type="person:head of state" xmlns:e="http://marklogic.com/entity">Richard Nixon</e:entity> <e:entity type="person:head of state" xmlns:e="http://marklogic.com/entity">Nixon</e:entity> <e:entity type="administrative district:national capital" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity type="administrative district:town" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity type="imaginary being:mythical being" xmlns:e="http://marklogic.com/entity">Paris</e:entity>
For a complete example, see XQuery Example: entity:extract or JavaScript Example: entity.extract.
If you pass multiple dictionaries to extract, then the dictionaries are applied in turn, in the order provided.
You can further tailor the output of extract as follows:
- Use the full option to decorate the entity element with additional information from the matched dictionary entry, such as the entity id and normalized text.
- Pass in a mapping between entity type names and element QNames to change the QName of the entity element based on the entity type.
For example, suppose you have an entity dictionary that defines the word Nixon as an entity of type person:head of state. Further, suppose you define a mapping from person:head of state to the QName entity:vip. Then, the following table illustrates different ways of formatting the extracted entities:
If this level of customization does not meet the needs of your application, see Extraction Using cts:entity-walk or cts.entityWalk.
Extraction Using cts:entity-walk or cts.entityWalk
When you use cts:entity-walk or cts.entityWalk , MarkLogic runs caller-specified code whenever text matches an entity dictionary entry. This means you have complete control over the result of the walk.
Using cts:entity-walk in XQuery
When you use XQuery, you pass an inline entity generator expression to cts:entity-walk as an inline expression. The walk returns whatever items your generator produces.
MarkLogic makes information about the match available to your code through special variables such as $cts:entity-type, $cts:text, $cts:entity-id, $cts:normalized-text, and $cts:start. For details, see the function reference documentation for cts:entity-walk.
For example, the following code returns a sequence of JSON objects containing details about each match. The $cts:* variables are populated with details about the match by cts:entity-walk.
cts:entity-walk($input-node, (object-node { "type": $cts:entity-type, "text": $cts:text, "normText": $cts:normalized-text, "id": $cts:entity-id, "start": $cts:start }), $dictionary)
You can control the walk by using xdmp:set to set the variable $cts:action to continue, skip, or break. The default action is to continue.
For a complete example, see XQuery Example: cts:entity-walk.
Using cts.entityWalk in JavaScript
When you use Server-Side JavaScript, you pass an entity generator callback function to cts.entityWalk. MarkLogic invokes the callback whenever an entity match is found. The callback function has the following signature:
function(entityType, text, normText, entityId, node, start)
MarkLogic populates these parameters with details from the input node and matched entity dictionary entry.
You're responsible for accumulating any data created by the extraction in a variable in scope at the point of call. For example, the following code creates a JavaScript object containing details about each match and accumulats the objects in a results variable.
const results = []; cts.entityWalk(inputNode, function(entityType, text, normText, entityId, node, start) { results.push({ type: entityType, text: text, norm: normText, id: entityId, start: start }); }, dictionary);
The value returned by your callback controls the walk. The default action is to continue the walk. You can return skip or break to halt the walk.
For a complete JavaScript example, see JavaScript Example: cts.entityWalk.
XQuery Example: entity:extract
This example uses entity:extract to extract entities from XML content, as described in Extraction Using entity:extract or entity.extract. The example demonstrates the use of various cutomization features of entity:extract.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary.
The example uses the dictionary to extract entities for the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
Copy and paste the following code into Query Console, set the Query Type to XQuery, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
xquery version "1.0-ml"; import module namespace entity="http://marklogic.com/entity" at "/MarkLogic/entity.xqy"; let $dictionary := cts:entity-dictionary(( cts:entity("11208172","Nixon","Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard M. Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard Milhous Nixon", "person:head of state"), cts:entity("11208172","Nixon","President Nixon","person:head of state"), cts:entity("08932568","Paris","Paris", "administrative district:national capital"), cts:entity("09145751","Paris","Paris","administrative district:town"), cts:entity("09500217","Paris","Paris","imaginary being:mythical being") )) (: Entity type to element QName map :) let $mapping := map:map() => map:with("", xs:QName("entity:entity")) => map:with("administrative district", xs:QName("entity:gpe")) => map:with("person", map:map() => map:with("", xs:QName("entity:location")) => map:with("head of state", xs:QName("entity:vip"))) let $input-node := <node>Nixon visited Paris</node> return ( "------- default -------", entity:extract($input-node, $dictionary), "------- full option -------", entity:extract($input-node, $dictionary, ("full")), "------- mapping -------", entity:extract($input-node, $dictionary, (), $mapping), "------- full + mapping -------", entity:extract($input-node, $dictionary, ("full"), $mapping) )
The example extracts four entities, in different formats: One match for Nixon, and three for Paris. The following entities are extracted by the various parameter and option combinations:
------- default ------- <e:entity type="person:head of state" xmlns:e="http://marklogic.com/entity">Nixon</e:entity> <e:entity type="administrative district:national capital" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity type="administrative district:town" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity type="imaginary being:mythical being" xmlns:e="http://marklogic.com/entity">Paris</e:entity> ------- full option ------- <e:entity id="11208172" norm="Nixon" start="1" path="/node/text()" type="person:head of state" xmlns:e="http://marklogic.com/entity">Nixon</e:entity> <e:entity id="08932568" norm="Paris" start="15" path="/node/text()" type="administrative district:national capital" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity id="09145751" norm="Paris" start="15" path="/node/text()" type="administrative district:town" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity id="09500217" norm="Paris" start="15" path="/node/text()" type="imaginary being:mythical being" xmlns:e="http://marklogic.com/entity">Paris</e:entity> ------- mapping ------- <entity:vip xmlns:entity="http://marklogic.com/entity">Nixon</entity:vip> <entity:gpe xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:gpe xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:entity type="imaginary being:mythical being" xmlns:entity="http://marklogic.com/entity">Paris</entity:entity> ------- full + mapping ------- <entity:vip id="11208172" norm="Nixon" start="1" path="/node/text()" xmlns:entity="http://marklogic.com/entity">Nixon</entity:vip> <entity:gpe id="08932568" norm="Paris" start="15" path="/node/text()" xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:gpe id="09145751" norm="Paris" start="15" path="/node/text()" xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:entity id="09500217" norm="Paris" start="15" path="/node/text()" type="imaginary being:mythical being" xmlns:entity="http://marklogic.com/entity">Paris</entity:entity>
If the full option and entity type map features of entity:extract do not provide enough control of the output to meet the needs of your application, use cts:entity-walk instead.
For more details on entity type maps, see Using an Entity Type Map for Extraction or Enrichment.
XQuery Example: cts:entity-walk
This example uses cts:entity-walk to extract entities as JSON object nodes, rather than as XML elements as you would get using entity:extract. Each object contains details about the match, such as the entity type, entity id, and codepoint offset in the input node.
For more details, see Extraction Using cts:entity-walk or cts.entityWalk.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary.
The example uses the dictionary to extract entities for the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
Copy and paste the following code into Query Console, set the Query Type to XQuery, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
xquery version "1.0-ml"; let $dictionary := cts:entity-dictionary(( cts:entity("11208172","Nixon","Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard M. Nixon","person:head of state"), cts:entity("11208172","Nixon","Richard Milhous Nixon", "person:head of state"), cts:entity("11208172","Nixon","President Nixon","person:head of state"), cts:entity("08932568","Paris","Paris", "administrative district:national capital"), cts:entity("09145751","Paris","Paris","administrative district:town"), cts:entity("09500217","Paris","Paris","imaginary being:mythical being") )) let $input-node := <node>Nixon visited Paris</node> return cts:entity-walk($input-node, (object-node { "type": $cts:entity-type, "text": $cts:text, "normText": $cts:normalized-text, "id": $cts:entity-id, "start": $cts:start }), $dictionary)
You should get output similar to the following:
{ "type":"person:head of state",
"text":"Nixon", "normText":"Nixon",
"id":"11208172", "start":1}
{ "type":"administrative district:national capital",
"text":"Paris", "normText":"Paris",
"id":"08932568", "start":15}
{ "type":"administrative district:town",
"text":"Paris", "normText":"Paris",
"id":"09145751", "start":15}
{ "type":"imaginary being:mythical being",
"text":"Paris", "normText":"Paris",
"id":"09500217", "start":15}The $cts:* variables used to populate the JSON property values are set by cts:entity-walk, based on the matched text and dictionary entry.
You can control the walk by setting $cts:action. The default action is continue. If you set the action to skip or break using xdmp:set, then you can interrupt the walk. For example, the following call exits the walk after the first match:
cts:entity-walk($input-node, (xdmp:set($cts:action, "break"), object-node { "type": $cts:entity-type, "text": $cts:text, "normText": $cts:normalized-text, "id": $cts:entity-id, "start": $cts:start }), $dictionary)
JavaScript Example: entity.extract
This example uses entity.extract to identify entities in your content and generate a sequence of entity elements that describe the matches, as described in Extraction Using entity:extract or entity.extract. The example demonstrates the use of various customization features of entity.extract.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary.
The example uses the dictionary to extract entities for the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
Copy and paste the following code into Query Console, set the Query Type to JavaScript, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
'use strict'; const entity = require('/MarkLogic/entity'); // Construct the dictionary. Could also get it from the db. const dictionary = cts.entityDictionary([ cts.entity('11208172', 'Nixon', 'Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard M. Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard Milhous Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'President Nixon', 'person:head of state'), cts.entity('08932568', 'Paris', 'Paris', 'administrative district:national capital'), cts.entity('09145751', 'Paris', 'Paris', 'administrative district:town'), cts.entity('09500217', 'Paris', 'Paris', 'being:mythical being') ]); // Entity type to wrapper element QName map const mapping = { '' : fn.QName('http://marklogic.com/entity', 'entity:entity'), 'administrative district': fn.QName('http://marklogic.com/entity', 'entity:gpe'), person: { '': fn.QName('http://marklogic.com/entity', 'entity:person'), 'head of state': fn.QName('http://marklogic.com/entity', 'entity:vip') } }; // Construct <node>Nixon visited Paris</node> const inputNode = new NodeBuilder() .addElement('node', 'Nixon visited Paris') .toNode(); const resultBuilder = new NodeBuilder(); const result = [ entity.extract(inputNode, dictionary), entity.extract(inputNode, dictionary, ['full']), entity.extract(inputNode, dictionary, null, mapping), entity.extract(inputNode, dictionary, ['full'], mapping) ]; result;
The example extracts four entities, in different formats: One match for Nixon, and three for Paris. The example extracts the following entities, based on the various parameter and option combinations:
------- default ------- <e:entity type="person:head of state" xmlns:e="http://marklogic.com/entity">Nixon</e:entity> <e:entity type="administrative district:national capital" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity type="administrative district:town" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity type="imaginary being:mythical being" xmlns:e="http://marklogic.com/entity">Paris</e:entity> ------- full option ------- <e:entity id="11208172" norm="Nixon" start="1" path="/node/text()" type="person:head of state" xmlns:e="http://marklogic.com/entity">Nixon</e:entity> <e:entity id="08932568" norm="Paris" start="15" path="/node/text()" type="administrative district:national capital" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity id="09145751" norm="Paris" start="15" path="/node/text()" type="administrative district:town" xmlns:e="http://marklogic.com/entity">Paris</e:entity> <e:entity id="09500217" norm="Paris" start="15" path="/node/text()" type="imaginary being:mythical being" xmlns:e="http://marklogic.com/entity">Paris</e:entity> ------- mapping ------- <entity:vip xmlns:entity="http://marklogic.com/entity">Nixon</entity:vip> <entity:gpe xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:gpe xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:entity type="imaginary being:mythical being" xmlns:entity="http://marklogic.com/entity">Paris</entity:entity> ------- full + mapping ------- <entity:vip id="11208172" norm="Nixon" start="1" path="/node/text()" xmlns:entity="http://marklogic.com/entity">Nixon</entity:vip> <entity:gpe id="08932568" norm="Paris" start="15" path="/node/text()" xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:gpe id="09145751" norm="Paris" start="15" path="/node/text()" xmlns:entity="http://marklogic.com/entity">Paris</entity:gpe> <entity:entity id="09500217" norm="Paris" start="15" path="/node/text()" type="imaginary being:mythical being" xmlns:entity="http://marklogic.com/entity">Paris</entity:entity>
If the full option and entity type map features of cts:extract do not provide enough control of the output to meet the needs of your application, use cts.entityWalk instead.
For more details on entity type maps, see Using an Entity Type Map for Extraction or Enrichment.
JavaScript Example: cts.entityWalk
This example uses cts.entityWalk to extract entities as JSON object nodes, rather than as the XML elements you get from entity.extract. Each object contains details about the match, such as the entity type, entity id, and codepoint offset in the input node.
For more details, see Extraction Using cts:entity-walk or cts.entityWalk.
The example uses an in-memory dictionary that defines the following:
- An entity of type person:head of state for various phrases that describe former United States President Richard Nixon.
- Several different entity types for the word Paris.
The example uses an in-memory dictionary and input data for the sake of self-containment. In a real application, you would usually store the dictionary in MarkLogic, as described in Persisting or Retrieving an Entity Dictionary.
The example uses the dictionary to extract entities for the phrases Nixon and Paris in the following input node:
<node>Nixon visited Paris</node>
Copy and paste the following code into Query Console, set the Query Type to JavaScript, and run it. If you are unfamiliar with Query Console, see the Query Console User Guide.
'use strict'; // Construct the dictionary. Could also get it from the db. const dictionary = cts.entityDictionary([ cts.entity('11208172', 'Nixon', 'Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard M. Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'Richard Milhous Nixon', 'person:head of state'), cts.entity('11208172', 'Nixon', 'President Nixon', 'person:head of state'), cts.entity('08932568', 'Paris', 'Paris', 'administrative district:national capital'), cts.entity('09145751', 'Paris', 'Paris', 'administrative district:town'), cts.entity('09500217', 'Paris', 'Paris', 'being:mythical being') ]); // Construct <node>Nixon visited Paris</node> const inputNode = new NodeBuilder() .addElement('node', 'Richard Nixon visited Paris') .toNode(); const resultBuilder = new NodeBuilder(); const results = []; cts.entityWalk(inputNode, function(entityType, text, normText, entityId, node, start) { results.push({ type: entityType, text: text, norm: normText, id: entityId, start: start }); }, dictionary); results;
The example constructs a JavaScript object for each match. Each object contains details about the match, such as the entity type, entity id, and code-point offset in the input node. You should get output similar to the following:
[{"type":"person:head of state",
"text":"Nixon", "normText":"Nixon",
"id":"11208172", "start":1},
{ "type":"administrative district:national capital",
"text":"Paris", "normText":"Paris",
"id":"08932568", "start":15},
{ "type":"administrative district:town",
"text":"Paris", "normText":"Paris",
"id":"09145751", "start":15},
{ "type":"imaginary being:mythical being",
"text":"Paris", "normText":"Paris",
"id":"09500217", "start":15}]The parameter values passed to your callback are populated by cts.entityWalk based on the matched text and dictionary entry.
You can control the walk by returning an action string value. The default action is continue. If you return skip or break, then you can interrupt the walk. For example, the following call exits the walk after the first match:
cts.entityWalk(inputNode, function(entityType, text, normText, entityId, node, start) { results.push({ type: entityType, text: text, norm: normText, id: entityId, start: start }); return 'break'; }, dictionary);
Using an Entity Type Map for Extraction or Enrichment
This section describes how to use the entity type map parameter accepted by the XQuery functions entity:extract and entity:enrich, or the JavaScript functions entity.extract and entity.enrich. Such a mapping gives you more control over the format of the extracted entities or enrichment markup.
This section covers the following topics:
- Entity Type Map Basics
- The Default Entity Type Map
- Handling Compound Entity Types
- Filtering Entity Types With a Mapping
Entity Type Map Basics
When you use the XQuery functions entity:enrich and entity:extract, or the JavaScript functions entity.enrich and entity.extract, you can pass in a mapping from entity type names to XML element QNames.
MarkLogic defines a default mapping that the enrich and extract functions use if you do not provide your own enitity type mapping. For details, see The Default Entity Type Map.
An entity type map enables you to change the QName of the generated entity wrapper element based on the entity type of a matching dictionary entry. For example, you can create a mapping that generates a my:person wrapper element when the entity type is person, instead of the default e:entity wrapper element.
In XQuery, use a map:map to define the entity type mappings. In JavaScript, use a JavaScript object.
The key value pairs in the mapping have the following characteristics:
- The key is an entity type name.
- A key that is an empty string specifies the QName to use when no explicit mapping exists for a type.
- The value is either a QName or another entity type map. When the value is a map, it defines a mapping for a segment of a compound entity type such as place:building. For more details, see Handling Compound Entity Types.
- If you map a type to the default entity QName (
fn:QName("http://marklogic.com/entity", "entity")), then the generated wrapper element includes atypeattribute, just as it does when you do not use a map. If you map a type to any other QName, then the wrapper element has notypeattribute because the type is implicit in the mapping.
If you use a type map, then any entity that is not covered by the map is discarded. That is, text of an umapped type is not treated as an entity, even if it matches an entity dictionary entry.
For example, the default entity wrapper generated by enrich and extract is of the following form:
<e:entity xmlns:e=... type="theEntityType">theText</e:entity>
Suppose you do not want all entities to generate an <e:entity/>. Instead, you want the following behavior:
| If the entity type is | Then generate a wrapper with QName |
|---|---|
person |
my:person |
location |
my:place |
anything else |
e:entity |
The followig map produces the desired behavior:
The example map produce entities of the following forms.
<my:person xmlns:my=...>somePerson</my:person> <my:place xmlns:my=...>somePlace</my:place> <e:entity xmlns:e=... type="thing">someThing</e:entity>
Notice that only the e:entity element includes a type attribute. This is because the entity type is assumed to be implicit in the QName customization when you use a custom QName.
In JavaScript, you can also use associative array syntax to construct a map. For example:
map[''] = fn.QName('http://marklogic.com/entity', 'entity:entity'); map['location' = fn.QName('http://my/example', 'my:place'); map['person'] = person: fn.QName('http://my/example', 'my:person');
The Default Entity Type Map
If you do not pass your own entity type map into the extract and enrich library functions, MarkLogic uses its default map. The default map enables you to create a dictionary for some commonly used entity abstractions without adopting a complex external ontology or defining your own type system.
The wrapper elements generated using the default map are all in the namespace http://marklogic.com/entity. For example:
<e:entity xmlns:e="http://marklogic.com/entity">...</e:entity>
The default map defines mappings for common entity abstractions such as person, location, url, and currency. For example, the entity type name PERSON maps to the QName e:person, and the entity type IDENTIFIER:URL maps to e:url. Any unrecognized entity type maps to the QName e:entity.
For a complete list of the default key-value pairs, see the function reference for the XQuery functions entity:enrich or entity:extract, or the JavaScript functions entity.enrich and entity.extract.
The following example defines an entity dictionary that uses entity types from the default map (LOCATION, IDENTIFIER:MONEY, and NATIONALITY) and one type (thing) that is not used by the default map.
The example extracts the following sequence of entities. Notice that the entity "trip", whose type does not have an entry in the default map, is extracted as an e:entity element.
<e:entity type="thing" xmlns:e="http://marklogic.com/entity">cost</e:entity> <e:location xmlns:e="http://marklogic.com/entity">Washington, DC</e:location> <e:nationality xmlns:e="http://marklogic.com/entity">Japanese</e:nationality> <e:money xmlns:e="http://marklogic.com/entity">Yen</e:money>
Handling Compound Entity Types
A compound entity type is composed of colon (:) separated segments that specify sub-types of that type. For example, an entity type such as person:head of state has two segments: person and head of state and specifies a sub-type of person. You can create an entity type map that takes such specialization into consideration by creating a key-value pair where the value is a map.
For example, suppose you want to create a mapping that has the following effect:
| If the entity type is | Then generate a wrapper with QName |
|---|---|
person |
person |
person:artist |
artiste |
person:head of state |
vip |
person:anythingElse |
person |
Then you can use the following map get the desired behavior. Notice that the value for the person key is itself a type map.
You can nest the type maps as deeply as necessary to cover additional type segments.
Filtering Entity Types With a Mapping
When you use type map, any entity type not covered by the map is discarded. That is, text that matches an unmapped type is not treated as an entity reference for purposes of enrichment or extraction. In this way, an entity type map can serve as a filter.
For example, if you have an entity dictionary that contains entries for the entity types person, location and thing, but you are only interested in extracting person entities, then you can define a map that only covers the person entity type, causing any location or thing entities to be treated as non-entity text, and thus not extracted. Note that you still incur the cost of entity matching.
The following example defines a map that covers only a single entity type, person. If used with an entity dictionary that also defines location and thing entity types, such entities would not be extracted when used with the map.
| Language | Example |
|---|---|
| XQuery | map:map()=> map:with("person", xs:QName("entity:entity")) |
| Server-Side JavaScript | {'person' : fn.QName('http://marklogic.com/entity', 'entity:entity') } |
Overlapping Entity Match Handling
This section discusses how the dictionary-based APIs behave when more than one entity definition applies to the same piece of text. See the following topics for more details:
- Understanding Entity Overlaps
- Overlap Handling Options
- Example: Overlap Handling in entity:extract and entity.extract
- Example: Overlap Handling in entity:enrich and entity.enrich
- Interaction with the Walk and Highlight Functions
Understanding Entity Overlaps
An entity overlap occurs when the same run of input text matches more than one entry in the same entity dictionary. For example, suppose you create a dictionary with entries for the terms cat, black cat, and cat fur. Then the phrase A black cat fur ball contains overlapping text runs matching all three of these entries:

The best treatment for such overlaps depends on your application. Allowing overlaps is often the best choice for entity extraction, but may not produce desirable results for entity enrichment.
When you allow overlaps during enrichment, the text captured for enrichment can be an empty string if one entity match is completely contained in another (cat in black cat), or a partial string if the matches partially overlap (black cat and cat fur). For more details, see Example: Overlap Handling in entity:enrich and entity.enrich.
MarkLogic supports both allowing and removing overlaps through options that are available during dictionary creation. For details, see Overlap Handling Options.
Overlaps are only a concern within a single dictionary. You can pass multiple dictionaries to the extract and enrich library functions, and those dictionaries can contain entries whose text overlaps, but the dictionary with the first match always wins.
Overlap Handling Options
When you create an entity dictionary, you can use the following options to control the handling of overlaps. These options are mutually exclusive.
allow-overlaps: During extraction, include all overlapping matches. During enrichment, enrich the non-overlapping portions of each match; do not enrich entities completely contained within another match.remove-overlaps: MarkLogic selects a single best match and discards the others. The best match is the longest match when the text is scanned from left to right. If more than one match qualifies, select the leftmost.
By default, dictionaries are created with allow-overlaps.
For more details, see Example: Overlap Handling in entity:extract and entity.extract and Example: Overlap Handling in entity:enrich and entity.enrich.
These options also affect how often your extraction or enrichment code is called and with which values when you use cts:entity-highlight, cts:entity-walk, cts.entityHighlight, or cts.entityWalk. For details, see Interaction with the Walk and Highlight Functions.
Example: Overlap Handling in entity:extract and entity.extract
This section explores how the overlap option set for a dictionary affects the output of entity:extract and entity.extract.
Suppose you have an entity dictionary containing the following entries:
| ID | Norm. Text | Text | Entity Type |
|---|---|---|---|
1234 |
cat |
cat |
feline |
2345 |
black cat |
black cat |
superstition |
3456 |
cat fur |
cat fur |
allergen |
Suppose that your input data is the following XML element node:
<node>A black cat fur ball</node>
Then the following table illustrates default results from calling entity:extract or entity.extract with the example data and a dictionary using different overlap options. (Whitespace has been added to the sample output to improve readability.)
Notice that when you use remove-overlaps, extract returns only the black cat entity match because this is longest match.
Example: Overlap Handling in entity:enrich and entity.enrich
This section explores how the overlap option set for a dictionary affects the output of entity:enrich and entity.enrich.
Suppose you have an entity dictionary containing the following entries:
| ID | Norm. Text | Text | Entity Type |
|---|---|---|---|
1234 |
cat |
cat |
feline |
2345 |
black cat |
black cat |
superstition |
3456 |
cat fur |
cat fur |
allergen |
Suppose that your input data is the following XML element node:
<node>A black cat fur ball</node>
The following table illustrates default results from calling entity:enrich or entity.enrich with the example data and a dictionary using different overlap options. (Whitespace has been added to the sample output to improve readability.)
Notice the following about using a dictionary with allow-overlapsenabled during enrichment:
- The cat entity is not reflected in the output because the matched text (cat) is completely encapsulated in another match, black cat. The term cat cannot be marked up without adding new, duplicate text to the content, which the API never does.
- The cat fur entity markup only captures the text fur because this is the non-overlapping portion of the matched text. Again, it is not possible to mark up the whole phrase cat fur without introducing duplicate text.
Thus, you usually want to use a dictionary with remove-overlaps enabled for enrichment.
Interaction with the Walk and Highlight Functions
The XQuery functions cts:entity-walk or cts:entity-highlight and the Server-Side JavaScript functions cts.entityWalk or cts.entityHighlight interact with overlaps as follows:
- When remove-overlaps is enabled on a dictionary, your code is only evaluated for the best match, as previously described.
- When allow-overlaps is enabled on a dictionary, your code is evaluated for every overlapping match in the dictionary.
- When allow-overlaps is enabled, then the
textvalue made available to your code by cts:entity-highlight and cts.entityHighlight will be an empty string if it is completely contained in another match (as with cat and black cat) - When allow-overlaps is enabled, then the
textvalue made available to your code by cts:entity-highlight and cts.entityHighlight will be only the non-overlapping part of a partial overlap (as with black cat and cat fur).
For examples of cases where you might get an empty or partial string during entity highlighting, see Example: Overlap Handling in entity:enrich and entity.enrich. The enrich library function is basically an abstraction on top of cts:entity-highlight and cts.entityHighlight.
Entity Identification Using Reverse Query
If your entities cannot be identified by string matching, but can be described by a query, you can use a reverse query for entity identification. A normal query says find all documents that match this query. A reverse query says find all queries that would match this document.
- Create a rule document containing a serialized cts query that describe the entity.
- Use cts:reverse-query (XQuery) or cts.reverseQuery (JavaScript) to find the rule documents that contain revere queries satisfied by your content.
- If you want to enrich the content, apply cts:highlight (XQuery) or cts.highlight (JavaScript) to the input and matching rules.
- If you want to extract entities, apply cts:walk (XQuery) or cts.walk (JavaScript) to the input and matching rules.
For example, suppose you want to annotate terms in your content that correspond to activities such as hiking, biking, and running. However, you want to use a stemmed word query instead of a simple string match so that terms such as run, ran, and running match the run activity. You cannot use entity:enrich or entity.enrich because dictionary matching does use stemmed search.
The following node can serve as an entity matching rule for terms that stem to run, swim, hike, and bike.
<activity type="outdoor"> <query>{cts:word-query(("run", "swim", "hike", "bike"))}</query> </activity>
If you insert such rules into MarkLogic in a collection with the URI activity, then the following query finds words that match the rules, and wraps each matched word in an wrapper element whose local name is the same as the type attribute on the matching rule:
If the activity collection includes the rule for run, swim, hike, and bike shown above, then the example produces the following output:
<node> I <outdoor>ran</outdoor> 5 miles and then went <outdoor>hiking</outdoor> </node>
If you use cts:walk or cts.walk instead of cts:highlight or cts.highlight, then you can extract entities, rather than enrich the content. For example:
The example produces the following extracted entities:
<outdoor>ran</outdoor> <outdoor>hiking</outdoor>
Entity Enrichment Pipelines
If your entities cannot be identified using a dictionary (string matching) or a query, you can use a 3rd party entity extraction or enrichment library.
MarkLogic Server includes Content Processing Framework (CPF) applications to perform entity enrichment on your XML. You can use the CPF applications for third-party entity extraction technologies, or you can create custom applications with your own technology or some other third-party technology. This section includes the following parts:
These CPF applications require you to install content processing on your database. For details on CPF, including information about domains and pipelines, see the Content Processing Framework Guide guide.
Sample Pipelines Using Third-Party Technologies
There are sample pipelines and CPF applications which connect to third-party entity enrichment tools. The sample pipelines are installed in the <marklogic-dir>/Installer/samples directory. There are sample pipelines for the following entity enrichment tools:
MarkLogic Server connects to these tools via a web service. Sample code is provided on an as-is basis; the sample code is not intended for production applications and is not supported. For details, including setup instructions, see the README.txt file and the samples-license.txt file in the <marklogic-dir>/Installer/samples directory.
Custom Entity Enrichment Pipelines
You can create custom CPF applications to enrich your documents using other third-party enrichment applications. To create a custom CPF application you will need the third party application, a way to connect to it (via a web service, for example), and you will need to write XQuery code and a pipeline file similar to the ones used for the sample applications described in the previous section.